| UDA(Unsupervised Data Augmentation) | 您所在的位置:网站首页 › 对抗训练是什么意思 › UDA(Unsupervised Data Augmentation) |
UDA(Unsupervised Data Augmentation)
|
1 简介
当标注好的数据很少时,半监督学习在深度学习模型中有非常好的表现。目前常用的方法是一致性训练,基于大量的非标注数据进行训练来使模型可以应对各种输入噪声(或者隐状态的噪声)。 有些方法是来设计各种噪声注入模型进行训练,如附加高斯噪声、dropout、对抗噪声。 而UDA(Unsupervised Data Augmentation)是强调这些优秀数据增强方法的使用。不过从名字就可以看出来,UDA是对非标注数据进行数据增强,以前的方法一般是对标注数据增强。 本文依据2020年《Unsupervised Data Augmentation for Consistency Training》翻译总结。 主要贡献如下: 1)我们显示在监督学习中优秀的数据增强方法也适用于半监督学习的一致性训练中。 2)UDA可以媲美甚至超越监督学习的效果。而这些监督学习却使用了比UDA非常多的标注数据。无论是在视觉任务还是语言任务上。UDA只需使用很少的标注数据。 3)UDA也可以利用迁移学习,如fine-tuning后的BERT,加上UDA可以取得更好的成绩。同时UDA在大数据量的ImageNet上也有效。 4)同时我们进行了UDA的理论分析。 2 Unsupervised Data AugmentationUDA的目标函数公式如下,示意图也如下。可以看到分为两部分,第一部分是Supervised Cross-entropy Loss,第二部分是Unsupervised Consistency Loss。第二部分又是求数据增强后和数据增强前的一致性(CE那部分)。可以看到数据增强部分是对非标注数据进行的,不像传统的方法是对标注数据进行的。 参数: λ,权重因子,平衡第一部分Supervised Cross-entropy Loss和第二部分Unsupervised Consistency Loss。我们大部分的实验采用λ=1。 CE:表示交叉熵cross entropy。
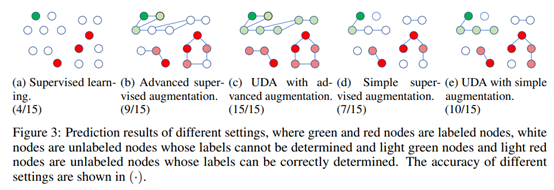
1)在图片分类任务中使用RandAugment:从Python Image Library (PIL) 中均匀采样数据增强方法。 2)文本分类中采用Back-translation:将样本x翻译成另一种语言B,然后再翻译回来x ̂. 3) 将低TF-IDF分的单词替换掉,保持高TF-IDF分的。 4 额外的训练技巧第二部分Unsupervised Consistency Loss采用如下公式:(1)引入了一个阈值β,分类概率大于β的才考虑。(2)Sharpening Predictions,采用一个低softmax温度控制参数τ。我们实验中采用0.4. 大体思路是(1)数据增强丰富了(覆盖了)子类别的各种情况,如下面c图。(2)子类列中的数据是可以通过各种转换操作进行互相转换的,所以UDA只需要很少的标注样本即可。
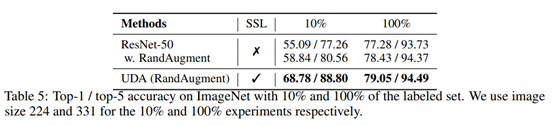
下图可以看出来UDA只需要很少的标注数据就可以取得很好的成绩(较低的错误率)。 图像任务比较:其中ICT、MixMatch也是半监督学习方法。 文本任务比较: ImageNet Dataset上比较: |
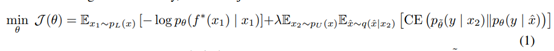



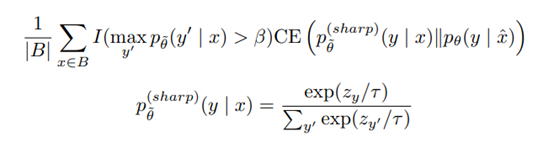



【本文地址】