| 《数字图像处理》题库5:计算题 ③ | 您所在的位置:网站首页 › 对二值图像进行标记处理 › 《数字图像处理》题库5:计算题 ③ |
《数字图像处理》题库5:计算题 ③
|
前言
这是我在学习数字图像处理这门课程时,从网络上以及相关书籍中搜集到的一些题目, 这些题目主要是针对期末考试的。 做题之前你需要注意以下几点: 这篇文章整理了第5种题型,即计算题的第3部分。由于题目或答案中会出现许多的公式,重新编写很费时间,因此,我会将整个题目或答案截成图片来代替。为了提高复习的效率,这篇文章从考试可能涉及到的各个考点出发, 将题目按照考点归类,每一个考点中包括知识点回顾、经典例题、举一反三这3个部分。如果你需要举一反三中练习题的答案,可以前往我的个人主页下载对应的资源(整理不易,希望大家支持)。 考点21:香农—范诺编码 知识点回顾香农—范诺(Shannon-Fannon)编码也是一种典型的可变字长编码。与哈夫曼编码相似,当信源符号出现的概率正好为2的负幂次方时,香农—范诺编码的编码效率可以达到100%。 香农—范诺编码的理论基础是符号的码字长度N i完全由该符号出现的概率来决定,对于二进制编码即有 编码步骤 将信源符号按其出现的概率由大到小顺序排列,若两个符号的概率相等,则相等概率的字符顺序可以任 意排列;计算出各概率符号所对应的码字长度N i;将各符号的概率累加,计算累加概率P,即: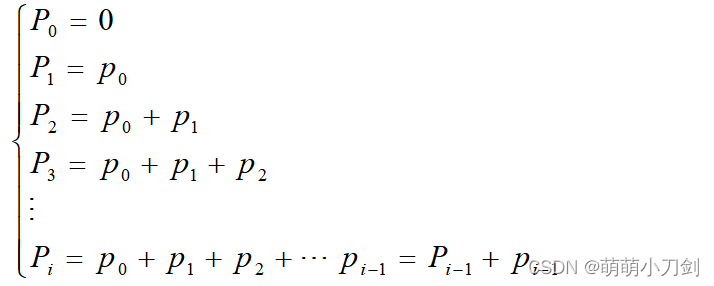 把各个累加概率P由十进制转换为二进制;取二进制累加概率前N i位的数字,并省去小数点前的“0.”字符即为对应信源符号的香农—范诺编码码字 把各个累加概率P由十进制转换为二进制;取二进制累加概率前N i位的数字,并省去小数点前的“0.”字符即为对应信源符号的香农—范诺编码码字
设一幅灰度级为8的图像中,各灰度级分别用S0、S1、S2、S3、S4、S5、S6、S7表示,对应的概率分别为0.40、0.18、0.10、0.10、0.07、0.06、0.05、0.04,对其进行香农—范诺编码。并分别计算图像信息熵,平均码字长,效率以及信息冗余度 将信源符号按其出现概率由大到小顺序排列,为0.40,0.18,0.10,0.10,0.07,0.06,0.05,0.04; (2) 对于概率0.40对应的符号S0,根据(8-11)计算N0=2,将累加概率0.00转换位二进制小数为0.00,取前N0=2位,并去除小数点前的字符,即S0字符编码为00; (3) 对于概率0.18对应的符号S1,根据(8-11)计算N1=3,将累加概率0.40转换位二进制小数为0.0110,取前N1=3位,并去除小数点前的字符,即S1字符编码为011; (4) 对于概率0.10对应的符号S2,根据(8-11)计算N2=4,将累加概率0.58转换位二进制小数为0.10010,取前N2=4位,并去除小数点前的字符,即S2字符编码为1001; (5) 对于概率0.10对应的符号S3,根据(8-111)计算N3=4,将累加概率0.68转换位二进制小数为0.10100,取前N3=4位,并去除小数点前的字符,即S3字符编码为1010; (6) 对于概率0.07对应的符号S4,根据(8-11)计算N4=4,将累加概率0.78转换位二进制小数为0.11000,取前N4=4位,并去除小数点前的字符,即S4字符编码为1100; (7) 对于概率0.06对应的符号S5,根据(8-11)计算N5=5,将累加概率0.85转换位二进制小数为0.1101100,取前N5=5位,并去除小数点前的字符,即S5字符编码为11011; (8) 对于概率0.05对应的符号S6,根据(8-11)计算N6=5,将累加概率0.91转换位二进制小数为0.1110100,取前N6=5位,并去除小数点前的字符,即S6字符编码为11101; (9) 对于概率0.04对应的符号S7,根据(8-11)计算N7=5,将累加概率0.68转换位二进制小数为0.11110100,取前N7=5位,并去除小数点前的字符,即S7字符编码为11110; 综上所述,S1-S7的香农—范诺编码如下: 灰度级 S0 S1 S2 S3 S4 S5 S6 S7 编码 00 011 1001 1010 1100 11011 11101 11110
费诺—仙农编码与Huffman编码相反,采用从上到下的方法。 香农-范诺编码算法步骤: (1)按照符号出现的概率减少的顺序将待编码的符号排成序列。 (2)将符号分成两组,使这两组符号概率和相等或几乎相等。 (3)将第一组赋值为0,第二组赋值为1。 (4)对每一组,重复步骤2的操作。 经典例题设一幅灰度级为8的图象中,各灰度所对应的概率如下表,要求对其进行费诺.仙侬编码。 灰度值 S0 S1 S2 S3 S4 S5 S6 S7 出现频率 0.40 0.18 0.10 0.10 0.07 0.06 0.05 0.04 解:根据费诺—仙农编码的方法进行分组和赋值如下图所示
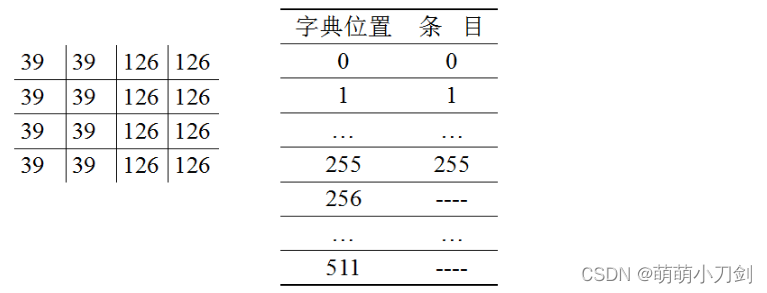
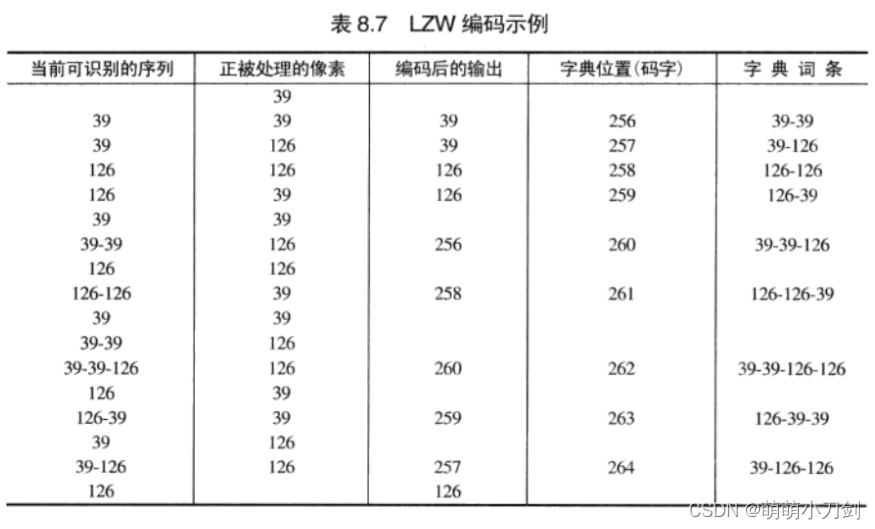
所得编码结果如下表 灰度值 S0 S1 S2 S3 S4 S5 S6 S7 费诺—仙农码 00 01 100 101 1100 1101 1110 1111 考点23:LZW编码 知识点回顾前几节中所覆盖的技术集中在消除编码冗余上。在这一节中,我们考虑一种致力于图像中的空间冗余的无误差压缩方法。称为Lempel-Ziv-Welch(LZW)编码的这种技术将定长码字分配给变长信源符号序列。 在第一定理的证明中,山农使用了信源符号编码序列这一思想,而不是单个信源符号。LZW 编码的关键特点是它不需要被编码符号出现的概率的先验知识。 LZW编码的原理 LZW 编码在概念上非常简单。 在编码过程的开始阶段,先构建一个包含被编码信源符号的码书或字典。对于8比特单色图像,字典中的前 256个字被分配给灰度值O.1.2,……,255。 当编码器顺序地分析图像像素时,不在字典中的灰度序列被放置在算法确定的位置(即下一个未用的位置)。 例如,如果图像的前两个像素为白色,则序列"255-255"可能被分配到 256 的位置,该位置后面的地址保留给灰度级 0 到 255。下次遇到两个连续的白色像素时,就用码字 256(即包含序列 255-255的位置的地址)来表示它们。 如果在编码过程中采用个9 比特、512字的字典,则最初用于表示这两个像素的(8+8)比特被单个9 比特码字替代。 很明显,字典的大小是一个很重要的系统参数。 如果字典太小,则匹配灰度级序列的检测将变得不太可能。如果字典太大,则码字的大小反而会影响压缩性能。LZW编码的特点 LZW 编码的一个独特的特点是,编码字典或码书是在对数据进行编码的同时创建的。很明显,在 LZW解码器对编码数据流进行解码的同时建立一个同样的解压缩字典。 多数实际应用都需要—种处理字典溢出的策略。一种简单的解决办法是,当字典已满时,刷新或重新初始化该字典,并使用一个新初始化后的字典继续编码。另一种复杂的选择是,监控压缩性能,并在性能变得低下或不可接受时刷新字典。此外,需要时,可跟踪并替换那些使用最少的字典词条。 经典例题【冈萨雷斯《数字图像处理》第3版 P352 例题8.7】 考虑下列大小为 4x4的8比特垂直边缘图像,并假设一个512字带有下列初始内容的字典(位置256到511开始时未使用)
下表中详细给出了对其16个像素进行编码的步骤。
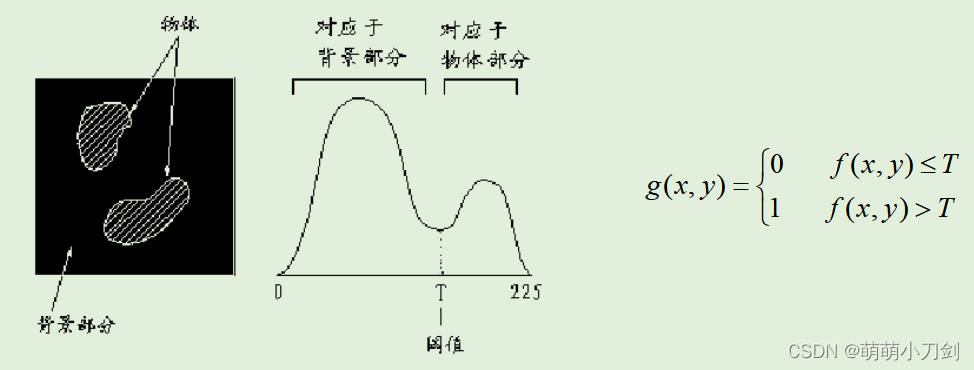
图像按从左到右、从上到下处理其像素的方法来进行编码。每个连续的灰度值与表中称之为"当前可识别的序列"的第 1 列的一个变量链接。就像我们能看到的那样,该变量最初为空。 对每一个链接的序列搜索字典,如果找到了,如表中第一行的情况,则用新链接且可识别的序列(即位于字典中的序列)替代它。这可在第2行的第1列中实现。这既不产生输出代码,也不更改字典。 然而,如果没有找到链接的序列,则将当前可识别序列的地址作为下一个编码值输出,并将链接但不可识别的序列添加到字典中,当前可识别的序列则初始化为当前的像素值。这出现在表中的第 2 行。 最后两列详细给出了扫描整个4x4 图像时添加到了字典中的灰度序列。定义了9个附加的码字。编码结束时,字典包含 256个码字,且LZW算法成功地识别了几个重复的灰度序列,平衡它们将 128 比特的原图像降到了90 比特(即 10个9比特码)。从上到下读取第3列即可得到编码输出。得到的压缩率是1.42∶1(128:90)。 举一反三【类似于 冈萨雷斯《数字图像处理》第3版 P400 例题8.19】 1、使用LZW编码算法,对7比特ASCII码字符串"aaaaaaaaaaa”进行编码 【冈萨雷斯《数字图像处理》第3版 P400 例题8.20】 2、为例8.7的LZW编码输出的解码操作设计一种算法。由于编码期间使用的字典此时不能使用,所以在对输出进行解码时必须重新生成码书。 考点24:压缩率 经典例题对于扫描结果:aaaabbbccdeeeeefffffff,若对其进行霍夫曼编码之后的结果是:f=01 e=11 a=10 b=001 c=0001 d=0000。 若使用行程编码和霍夫曼编码的混合编码,压缩率是否能够比单纯使用霍夫曼编码有所提高?若使用行程编码和霍夫曼编码的混合编码,压缩率是否能够比单纯使用行程编码有所提高?原始扫描结果所占空间为:22*8=176(bits) 单纯霍夫曼编码的结果是:10101010001001001000100010000111111111101010101010101,共占53(bits)。压缩比为176:53. 单纯行程编码的结果是:4a3b2c1d5e7f,共占6(3+8)=66(bits).压缩比为176:66 Hufman与行程编码混合:41030012000110000511701 ,共占3+2+3+3+3+4+3+4+3+2+3+2=35(bits),压缩比为176:35. 即两个压缩比都有所提高。 举一反三1、一图像大小为640×480 ,256 色。用软件工具SEA(version 1、3)将其分别转成24位色BMP,24位色 JPEG,GIF(只能转成256 色)压缩格式,24位色 TI FF压缩格式,24位色TGA压缩格式,得到的文件大小分别为:921,654 字节;17,707 字节;177,152 字节;923,044 字节;768,136 字节。分别计算每种压缩图像的压缩比。 2、某视频图像为每秒 30 帧,每帧大小为 512×512,32 位真彩色。现有 40 GB 的可用硬盘空间,可以存储多少秒的该视频图像?若采用隔行扫描且压缩比为 10 的压缩方法,又能存储多少秒的该视频图像? 考点25:区域分割、区域增长 知识点回顾状态法(峰谷法、灰度阈值法) 基本思想: 确定一个合适的阈值T。将大于等于阈值的像素作为物体或背景,生成一个二值图像。阈值的选定可以通过如下图中灰度直方图确定。方法:首先统计最简单图像的灰度直方图,若直方图呈双峰且有明显的谷,则将谷所对应的灰度值T作为阈值,按图右侧的等式进行二值化,就可将目标从图像中分割出来。 这种方法适用于目标和背景的灰度差较大、有明显谷的情况。 在四邻域中有背景的像素,既是边界像素。
简单区域扩张法 步骤:以图像的某个像素为生长点,比较相邻像素的特征,将特征相似的相邻像素合并为同一区域;以合并的像素为生长点,继续重复以上的操作,最终形成具有相似特征的像素是最大连通集合。这种方法称简单(单一型)区域扩张法。 具体步骤: 从图像最左上角开始,对图像进行光栅扫描,找到不属于任何的像素。把这个像素灰度同其周围(4邻域或8邻域)不属于其他区域的像素的灰度值和已存在区域的像素灰度 平均值进行比较,若灰度差值小于阈值,则合并到同一区域,并对合并的像素赋予标记。从新合并的像素开始,反复进行(2)的操作。反复进行(2)、(3)的操作,直至不能再合并。返回(1)操作,寻找新区域出发点的像素。分裂合并法(基于四叉树思想的方法) 对于图像中灰度级不同的区域,均分为四个子区域。如果相邻的子区域所有像素的灰度级相同,则将其合并。反复进行上两步操作,直至不再有新的分裂与合并为止。 经典例题
1) 统计图象1各灰度级出现的频率结果为 p(0) = 5/64≈0.078 p(1)=12/64≈0.188 p(2)=16/64=0.25 p(3)=9/64≈0.141 p(4)=1/64≈0.016 P(5)=7/64≈0.109 p(6)=10/64≈0.156 p(7)=4/64≈0.063 信息量为 2) 对于二值化图象, 若采用4-连接,则连接成分数为4,孔数为1,欧拉数为4-1=3; 若采用8-连接,则连接成分数为2,孔数为2,欧拉数为2-2=0; 2、对下图采用基于区域生长的方法进行图像分割,种子像素选为图中斜线画出的像素,给出生长准则为:邻近像素与当前区域灰度差值T |
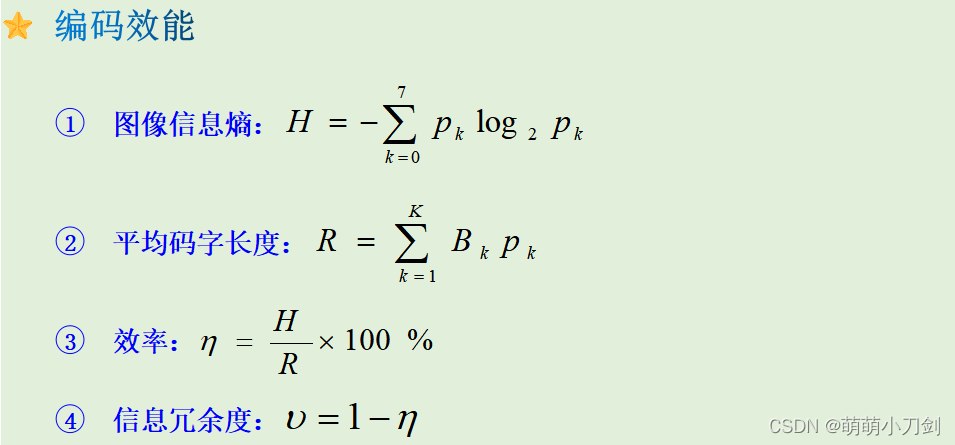
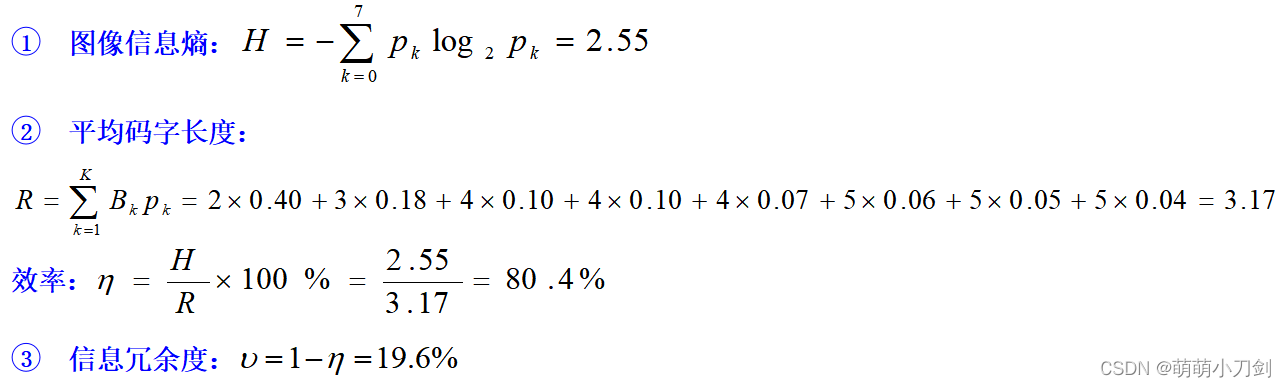


【本文地址】