| 结合深度信息的室内图像语义分割* | 您所在的位置:网站首页 › 对一张图片进行语义分割的方法 › 结合深度信息的室内图像语义分割* |
结合深度信息的室内图像语义分割*
|
李丽瑶 张荣国 胡 静 刘小君 李晓明 (1.太原科技大学计算机科学与技术学院 太原 030024)(2.合肥工业大学机械工程学院 合肥 230009) 1 引言图像语义分割,其任务是将图像分割成多个具有语义信息的块,并同时识别出其类别[1]。随着近年来卷积神经网络的发展,图像语义分割也进入了新的发展方向。在现有大多方法中,卷积神经网络(CNN)在利用RGB图像进行语义分割方面表现出很大的优势。一种称为全卷积神经网络(FCN)的典型CNN模型在过去几年语义分割研究中取得了卓越的性能。如文献[2]应用的编码器-解码器类型的FCN通过融合不同的卷积层表示,极大提高了分割预测的准确性。文献[3~4]使用了一个扩展的卷积算子来代替编码器-解码器体系结构使其在不损失分辨率的情况下扩展感受野并在多个分割任务上产生更好的性能。但大多数FCN及其衍生模型[5-7]是将深度图像视为一个额外的输入,使用两个CNN网络分别处理RGB图像和深度图像,分割效果有所改善但却增加了参数量且还无法将两幅图像直接的几何相关性关联起来并借助CNN模型训练。其次,由卷积神经网络直接分割出的物体边界大多粗糙,为了解决这个问题,研究人员开始将基于RGB模型的稠密条件随机场(CRF)与CNN结合起来,并在几个语义分割基准上获得了改进[8~9]。但室内真实场景复杂,其很难在光线较暗或较强的场景中应用这些方法。而Kinect深度相机的出现解决了这个问题。Kinect相机获取的RGBD图像既包含了被拍摄物体的RGB图像,也包含了深度信息[10]。最近,一些RGBD图像数据集已经公开发布[11~12]。由于深度信息包括对象的3D位置和结构,因此将深度通道用作RGB通道的补充信息可能会增加语义分割的准确性。综合以上,本文提出了一种具有深度敏感的卷积神经网络与条件随机场结合的新型模型。将具有深度信息的条件随机场模型合并到同样具有深度信息的神经网络中以提高分割准确性。本文贡献如下: 1)用深度感知卷积和深度感知平均池化替代原来传统的卷积和池化部分,以此将深度图中的深度信息无缝整合进CNN; 2)提出了一种新颖的包含深度信息的模型,该模型将RGB-D神经网络与深度敏感的全连接条件随机场相结合以提高分割精度; 3)在NYUv2数据集上进行对比实验,验证了所提出的模型在室内图像语义分割上的有效性。 2 相关工作基础2.1 卷积神经网络卷积神经网络(CNN)自2012年以来,在图像分类和图像检测等方面取得了巨大的成就,应用广泛。CNN的优点在于它的多层结构能自动学习多个层次的特征:较浅的卷积层感受野较小,可以学习到一些局部区域的特征;较深的卷积层具有较大的感受野,能够学习到更加抽象的特征。这些抽象特征对物体的大小、位置和方向等敏感性较高,从而有助于识别性能的提高。随着深度相机的出现,将具有几何特征的深度信息信息整合到CNN中既重要又具有挑战性。 2.2 条件随机场条件随机场模型最初是由Lafferty[13]在2001年提出的一种典型的判别式模型。它在观测序列的基础上对目标序列进行建模,重点解决序列化标注的问题条件随机场模型既具有判别式模型的优点,又具有产生式模型考虑到上下文标记间的转移概率,以序列化形式进行全局参数优化和解码的特点,解决了其他判别式模型(如最大熵马尔科夫模型)[14]难以避免的标记偏置问题,评估目标都是要得到最终的类别标签Y,即Y=argmax p(y|x)。判别式模型直接通过解在满足训练样本分布下的最优化问题得到模型参数,主要用到拉格朗日乘算法、梯度下降法等。 近年来很多语义分割的工作都建立在条件随机场上。Shotton等[15]提出的TextonBoost方法,在条件随机场中利用了目标类别的外观、形状、上下文等多种信息,可以用来完成目标识别和目标分类双重任务。Philipp等[16]提出了一种全连接CRF模型的近似判别算法,在这一模型中二元的边缘势函数被定义为两个高斯核的线性组合。算法是基于平均场近似的CRF分布。近些年随着深度学习方法的发展,越来越多的研究工作采用基于神经网络的方法解决图像语义分割问题或图像目标分析问题。后续研究[3]也证明,可以通过具有RGB信息的条件随机场来解决FCN输出中边界精度差的问题。 受上述工作启发,本文在这些研究基础上,将深度图像中的深度信息用深度感知卷积和深度感知平均池化整合进传统CNN的卷积和池化中去,在得到随机场的一元势能后,将其作为输入把深度信息与全连接条件随机场相结合进行神经网络分割后的后续细化,最终得到室内图像语义分割结果,具体内容如下。 3 本文的深度信息语义分割方法3.1 深度信息卷积神经网此段我们将具有深度感知的CNN进行初始语义分割。给定RGB图像和深度图像,得到每个像素的标签。我们使用经过修改的VGG-16网络[17]作为基准编码器,将深度感知卷积和平均池去替换标准CNN中的对应卷积网络中的层,最终生成分割概率图。具体操作如下。 首先输入特征图x∈Rci×h×w以及深度图像D∈Rh×w,其中ci是输入特征通道的数量,h是高度,w是宽度。输出特征图表示为y∈Rco×h×w,其中co是输出特征通道的数量。 接下来进行深度感知卷积。对于在y上的某个像素位置Po,标准2D卷积的输出:
其中R是x内在位置Po处的局部网格(local grid),W是卷积核。 为了描述深度信息,增加了两类权重: 可学习的卷积核m和两个像素之间的深度相似度FD:
其中∂是一个常数,本文中设为8.3,FD不需要反向传播梯度,所以上式中不会引入额外的参数。 然后进行深度感知平均池化。计算的是X在网格R中的均值,定义如下式:
平均池化是将全局像素等同分析处理,因此会在一定程度上导致目标边缘的模糊。而深度图像中的几何信息信息就可以用来解决这个问题,所以这里也利用深度信息FD,迫使在图像中几何信息关系更紧密的点对输出的贡献更大。对于每个在位置p0的像素点,操作定义如下:
传统CNN中,感受野和采样区域在feature map上是固定的;而在RGBDCNN中,我们可以通过深度感知卷积和深度感知池化层去影响感受野和采样动作。 用替换过层的VGG-16作为编码器生成分割概率图作为条件随机场的一元势能的输入。 3.2 深度信息条件随机场接下来,本文将不敏感于室内光照或遮挡影响的几何深度引入像素级全连接条件随机场模型来细化边缘分割,我们使用的全连接CRF模型的形式如下:
在上述深度敏感的全连接CRF中,每个像素都被视为一个CRF节点,能量函数由一元势能和成对势能(也称为一阶和二阶因子)组成。其中y=[y1,y2,…,yi,…,yn]T,其中i∈[1,n],上标T表示矩阵或向量的转置。yi元素是第i个像素分配的标签。一元电势φi(yi)=-log P(yi)是从CNN的最后一层计算得出的,其中P(yi)是在像素i的概率图上应用softmax的结果。φij(yi,yj)则是在图像I中所有像素对上具有高斯核的成对势函数。
其中μ是标签兼容性函数。在我们的条件随机场模型中用简单的Potts模型提供μ(xi,xj)[xi≠xj]。描述被分配到不同标签的相近相似像素的惩罚fi和fj是第i和第j位置像素的特征向量。θs(fi,fj)是平滑度内核,即
其中pi和pj表示第i个像素和第j个像素的位置。参数σ控制两个像素的接近度度。平滑度内核用于消除小的孤立区域。θ∂(fi,fj)是外观内核。在本文中,我们运用了一种新的外观内核,即
其中pi的定义与之前相同,Ii是第i个像素的颜色矢量,di是第i个像素的深度矢量。σ∂,θβ和σν控制两个像素之间的接近度和相似度。通过此定义,位置接近,颜色相似和深度相似的像素将被强制作为同一标签。位置、颜色和深度特征在上述等式中组合为一个高斯核。 与RGB对应的标准偏差相同。这允许深度图像和RGB图像在CRF模型中具有兼容的值范围。 4 实验结果及分析我们使用PyTorch深度学习框架,深度感知卷积和深度感知平均池运算符均通过CUDA加速实现,在条件随机场上的有效推断则利用平均场近似来进行高维滤波减少消息传递的复杂性。 4.1 数据集采用NYUv2[10]室内场景数据集,此数据集包含1449组RGBD图像对,其中795组用来训练,654组用来测试,分为十三个类别标签(bed,books,ceiling,chair,floor,furniture,objects,picture,safa,table,tv,wall,window)。 4.2 评估指标我们使用的评估指标有三个,即像素精度、平均准确度和交叉相交(IoU)分数。Cij表示被预测为类别j但实际上属于类别i的像素数。Cii表示正确预测类别i的像素数。Ti表示在地面真实情况下属于类别i的像素的总数。K表示数据集中的类别总数。 PA:像素精度
MPA:不同类别的平均像素精度
IoU:模型产生的目标窗口与原来标记窗口的交叠率(交并比)
为了对分割效果有个直观的了解,我们从NYUv2数据集中选取了部分图片,用所提方法进行了图像语义分割实验,并对条件随机场与深度信息的添加与否分别进行了实验,以此形成对比,结果如图1所示。实验表明条件随机场有细化分割的能力,而深度信息的加入则在一定程度上改善了由光照阴影造成的语义分割误差。
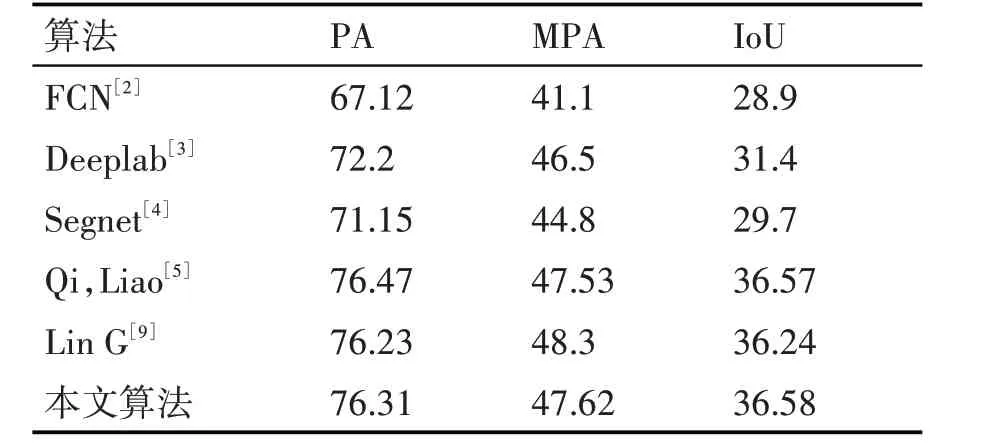
图1 本文方法图像分割结果图 为了说明所提方法的有效性,本文选取了五种现有算法,用前面所述的三种评估指标,在NYUv2数据集上的654组RGBD图像作进一步的实验,结果列于表1中。 表1实验数据表明本文实验在总体数据上都略微优于所对比实验分割结果,但在单个像素准确率上低于文献[5]所提方法。
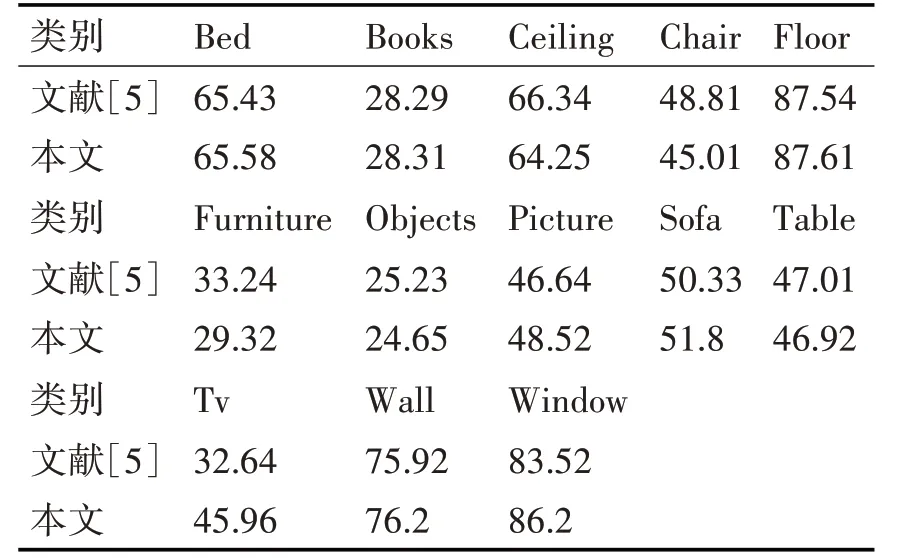
表1 使用NYUv2数据集六种算法实验对比结果 为了进一步验证本文方法在具体室内场景图像语义分割的效果和文献[5]所提方法分割效果的差别,对NYUv2数据集上十三个类别的图像分别进行了IoU评估,详细内容如表2所示。
表2 十三个类别两种方法IoU对比结果 从表2中可以看到,本文方法在大多数类的分割结果上略微优于文献[5]的方法。 5 结语本文针对室内场景分割中对光照敏感的问题提出了一种融合深度信息的室内场景图像语义分割方法,首先将深度信息先引入卷积神经网络中,后续再通过融合深度信息的稠密条件随机场继续进行细化分割,通过实验对比可证明本文方法可有效提高分割精度且优于其他方法。 猜你喜欢 类别语义卷积 真实场景水下语义分割方法及数据集北京航空航天大学学报(2022年8期)2022-08-31基于3D-Winograd的快速卷积算法设计及FPGA实现北京航空航天大学学报(2021年9期)2021-11-02论陶瓷刻划花艺术类别与特征陶瓷学报(2021年4期)2021-10-14一种并行不对称空洞卷积模块①计算机系统应用(2021年9期)2021-10-11一起去图书馆吧少儿画王(3-6岁)(2020年4期)2020-09-13从滤波器理解卷积电子制作(2019年11期)2019-07-04基于傅里叶域卷积表示的目标跟踪算法北京航空航天大学学报(2018年1期)2018-04-20“吃+NP”的语义生成机制研究长江学术(2016年4期)2016-03-11情感形容词‘うっとうしい’、‘わずらわしい’、‘めんどうくさい’的语义分析人间(2015年21期)2015-03-11汉语依凭介词的语义范畴长江学术(2015年1期)2015-02-27
|
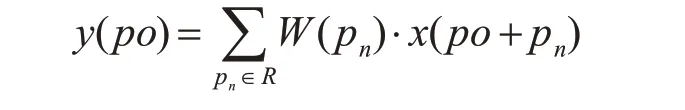
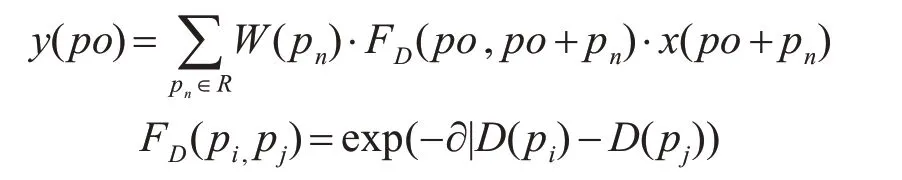
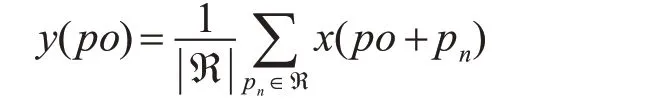
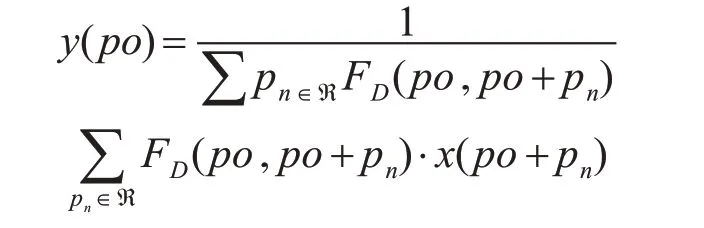
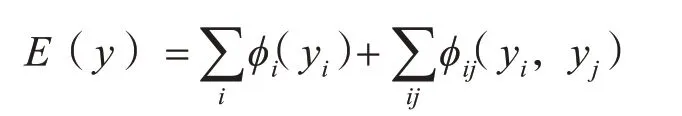
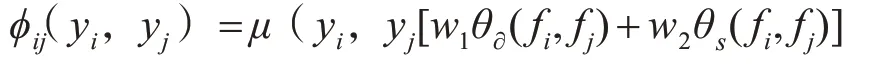
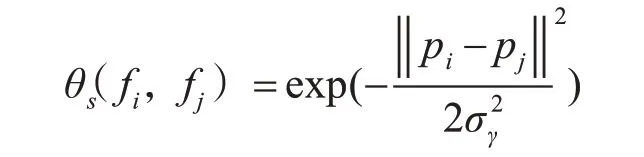
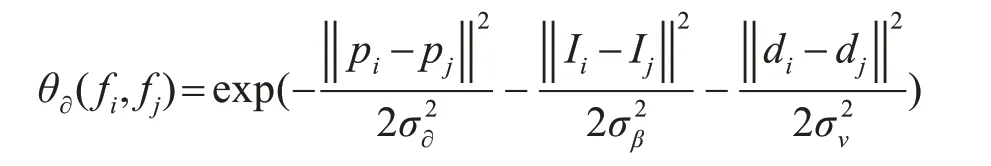
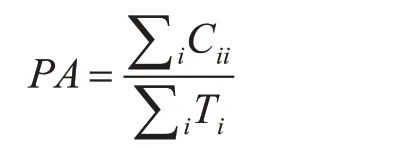
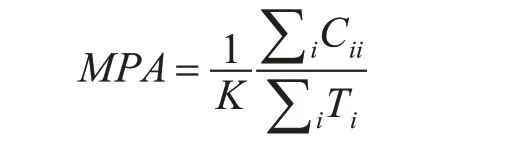
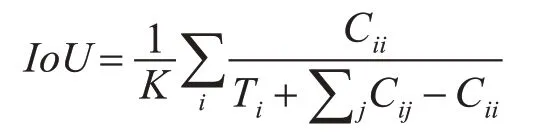

 计算机与数字工程2021年12期
计算机与数字工程2021年12期【本文地址】