| GitHub | 您所在的位置:网站首页 › 实时数仓flink项目经历编写 › GitHub |
GitHub
|
介绍
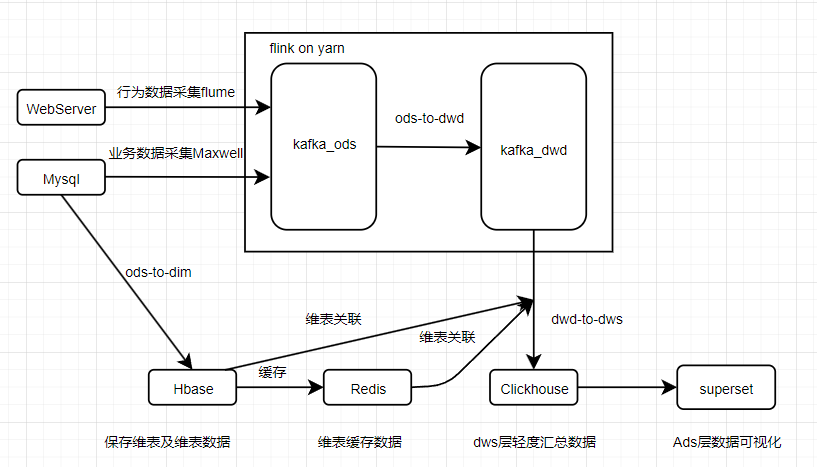
基于电商主题数据搭建的flink on yarn的实时数仓,flink 作业提交模式为per join,包含Ods、Dim、Dwd、Dws层。数据源包括行为日志数据以及业务数据。最终实现Dws层交易域、流量区域、用户区的轻度汇总表并将Dws层数据写入Clichouse中。 设计组件:Flink1.13.0、Hbase、Clickhouse、Redis、HDFS、Yarn、Kafka、Flume、Maxwell、Zookeeper、Docker Ods-To-Dim:将业务数据库中的维表以及维表数据写入到Hbase中。使用flinkCDC+双流(广播流+主流)实现动态增加维表插入HBase的功能。 详见:Ods-To-Dim任务Readme Ods-To-Dwd:将Ods层的用户行为数据以及业务数据经过脏数据去除、主题数据过滤等操作写入到对应主题的kafka中。 详见:Ods-To-Dwd行为数据Readme 、 Ods-To-Dwd业务数据Readme Dwd-To-Dws:用户域:用户登录数以及7日用户回流数、用户注册数。流量域:首页以及商品详情页独立访客数、关键词搜索数。交易域:加购物数汇总表、支付窗口汇总表、下单窗口汇总表、spu粒度下单汇总表、省份粒度下单汇总表。 详见:Dwd-To-Dws轻度汇总Readme 项目流程见下图
整个实验环境基于学校服务器内网搭建,使用Docker部署rtgMaster、rtgSlave1、rtgSlave2三个容器模拟实验环境。 校内服务访问: HDFS 172.21.13.53:9870 存放Hbase数据、Flink Checkpoint数据、每个Flink job存放的依赖以及日志 Yarn 172.21.13.53:8088 获取Flink Web Ui地址查看Flink job运行情况 HBase 172.21.13.53:16010 查看维度表以及Hbase运行状态 JobHistoryServer 172.21.13.53:19888 存放历史任务以及日志服务器配置:
rtgMaster、rtgSlave1、rtgSlave2节点服务分布如下表所示。
conf目录下 项目中遇到的问题 实验环境为docker 环境,在docker commit 时会有多个版本的镜像,因为在打包镜像时zk和Hbase有多次start和stop导致zk保存的Hbase元数据与Hbase本身不一致。解决:因为还没有对维度数据进行初始化,所以在zkCli中直接rmr /hbase phoenix-5.0.0-HBase-2.0-client.jar 冲突问题:phoenix与打的jar包中phoenix-5.0.0-HBase-2.0-client.jar冲突,报错为Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.mapreduce.InputFormat。解决:在pom文件中phoenix-5.0.0-HBase-2.0-client.jar位置provided掉,然后把phoenix-5.0.0-HBase-2.0-client.jar copy到 flink/lib下。 Flink写入phoenix中的数据中文乱码:flink-con.yaml中添加:env.java.opts: -Dfile.encoding=UTF-8 在提交flink任务时因为yarn资源配置以及jobmanager、taskmanager内存设置不合理,导致只能提交两个任务,yarn没有更多的资源了。解决过程详见Ods-To-Dwd行为数据Readme 在使用docker进行搭建HDFS、Yarn、Hbase等服务的环境时注意容器端口与物理机的映射,端口映射不一致导致无法访问服务。 TODO下一步计划 对Flink job进行反压、CheckPoint的监控。经过调研发现目前使用的Flink 作业的监控都是采用pushgateway+Prometheus+Grafana。但是经过尝试发现pushgateway不会主动清除过期数据,只能调用api删除。思考换一种方式解决Flink job反压以及CheckPoint的监控报警问题,从而及时得到Flink job的运行状态。 使用Docker-Compose来简化服务部署流程。 |


【本文地址】
公司简介
联系我们