| 一文包揽文本分割(话题分割)的6种评估性能的方法,理论+样例+代码,看完还不会的来找我! | 您所在的位置:网站首页 › 实例分割模型评估方法包括什么 › 一文包揽文本分割(话题分割)的6种评估性能的方法,理论+样例+代码,看完还不会的来找我! |
一文包揽文本分割(话题分割)的6种评估性能的方法,理论+样例+代码,看完还不会的来找我!
|
在本文中,我们将会简要介绍文本分割任务,并介绍6种常用的性能评估指标,使用通俗易懂的例子进行一个直观的感受,并最后使用代码实现评估过程,让你看完本文,就可以进行文本分割任务的评估了。如果看完理论+样例+代码还是不会的话,直接私聊我! 任务定义本文讨论的文本分割/话题分割是比较大的颗粒度的,一般是基于句子或者段落的。一般的,连续的段落会有一个子话题,我们就是在一篇文章中进行子话题的划分,例如下面这样一个诗歌: In Xanadu did Kubla KhanA stately pleasure-dome decree:Where Alph, the sacred river, ranThrough caverns measureless to manDown to a sunless sea.So twice five miles of fertile groundWith walls and towers were girdled round:And here were gardens bright with sinuous rills,Where blossomed many an incense-bearing tree;And here were forests ancient as the hills,Enfolding sunny spots of greenery.它共包含11个句子,可以被划分为下面3个部分: 1–2 Kubla Khan and his decree 3–5 Waterways 6–11 Fertile ground and greenery 这样的拆分就是文本分割任务。我们这里先不讲如何通过模型进行判断,当然可以使用无监督、分类、序列标注等模型进行实验,我们会在下一篇文章中介绍。 下面将会介绍在文本分割中常用的6类评估指标,使用实例告诉具体的计算方法,并在最后给出其代码实现。 评估指标判断一个模型进行文本分割任务的性能的高低,方法主要有以下6种: PRF值 这个评判标准在信息抽取(IR)中非常广泛的使用。在之前的文章中,我们就已经介绍过,这里不再赘述。 基于分词的方法 基于这个方法有两种,一种是比较宽容的,以BMEO四个标签的正确与否来进行判别,另一类则是比较严格的,必须预测正确每一个span的首位置和尾位置才算正确,例如正确的span划分为(1,3),(4,4),(5,7),那么你要是划分为(1,2),(3,4),(5,7),则只算对1个。 P k P_k Pk值 P k P_k Pk值最早在1997年TextTiling: Segmenting Text into Multi-paragraph Subtopic Passages 的论文中出现,后来在1999年Statistical Models for Text Segmentation中有了明确的定义,下面是它最原始的定义。 P μ ( r e f , h y p ) = ∑ 1 ≤ i ≤ j ≤ n D μ ( i , j ) δ r e f ( i , j ) X N O R δ h p y ( i , j ) P_μ(ref,hyp)=\sum_{1 \le i \le j \le n}D_μ(i,j)\delta_{ref}(i,j) XNOR \delta_{hpy}(i,j) Pμ(ref,hyp)=1≤i≤j≤n∑Dμ(i,j)δref(i,j)XNORδhpy(i,j) 我们不解释其公式的具体含义,我们解释一下它的目的,它就是使用一个窗口大小为K的滑动窗口(其中K如果不指定,K为标准分割的每个块的大小的平均值的一半),判断窗口的2个边缘的节点是否属于同一个主题,然后再看标准的判断和预测的判断是否一致即可,最后将一致的数量除以滑动次数就得出 P k P_k Pk值。下面我们会有真实的例子进行讲解。 WindowDiff(WD) 从刚才的描述来看, P k P_k Pk是一个相当麻烦的评估方法,而且并没有直接评估划分的是否正确,因此,到了2002年的论文(A Critique and Improvement of an Evaluation Metric for Text Segmentation),才有了Windowdiff(WD)。 WD指出Pk拥有5个问题: False negatives penalized more than false positives(假负例比假正例更容易受到惩罚)Number of boundaries ignored(忽略边界数量)Sensitivity to variations in segment size (对文本块大小敏感)Near-miss error penalized too much(对于小错误处罚太多)What do the numbers mean? (指标意图不明显)Windowdiff是替代Pk的评价指标,更加客观,其评估的公式为: W i n d o w D i f f ( r e f , h y p ) = 1 N − k ∑ i = 1 N − k ( ∣ b ( r e f i , r e f i + k ) − b ( h y p i , h y p i + k ) ∣ > 0 ) WindowDiff (ref , hyp) = \frac{1}{N-k}\sum_{i=1}^{N-k}(|b(ref_i, ref_{i+k} ) − b(hyp_i, hyp_{i+k} )| > 0 ) WindowDiff(ref,hyp)=N−k1i=1∑N−k(∣b(refi,refi+k)−b(hypi,hypi+k)∣>0) 这个就比较直观,就是直接判别两个区域内的分割线数量的异同即可,其中K的定义与之前 P k P_k Pk的一样。 Segmentation Similarity(S) 到了10年后,2012年Segmentation Similarity and Agreement使用编辑距离来更好的获取一些那种微小的错误(near misses)所带来的性能偏差。 S ( s a , s b , n t ) = 1 − ∣ e d i t s ( s a , s b , n t ) ∣ ∣ p b ( D ) ∣ S(s_a,s_b,n_t)=1- \frac{|edits(s_a,s_b,n_t)|}{|pb(D)|} S(sa,sb,nt)=1−∣pb(D)∣∣edits(sa,sb,nt)∣ 学过编辑距离的,就知道如何计算 s a s_a sa和 s b s_b sb序列的编辑距离,pb(D)是潜在的边界数量,不知道的话,这里有传送门。 Boundary Similarity (B) 然而就在1年以后,更先进的计算方法又出现了。在2013年的论文Evaluating Text Segmentation using Boundary Edit Distance中说,之前的3种方法都是具有偏见性的,并列举了4个例子(我们将会在下一部分见到)来说明新的评估方法的优势,下面是它的计算公式。 B ( s 1 , s 2 , n t ) = 1 − ∣ A e ∣ + w t _ s p a n ( T e , n t ) + w s _ o r d ( S e , T b ) ∣ A e ∣ + ∣ T e ∣ + ∣ S e ∣ + ∣ B m ∣ B(s_1,s_2,n_t)=1-\frac{|A_e|+w_t\_span(T_e,n_t)+w_s\_ord(S_e,T_b)}{|A_e|+|T_e|+|S_e|+|B_m|} B(s1,s2,nt)=1−∣Ae∣+∣Te∣+∣Se∣+∣Bm∣∣Ae∣+wt_span(Te,nt)+ws_ord(Se,Tb) 公式的具体细节可以看一下论文,论文里将的比较细,因为这不是重点,我们不再这重复讲解了。当然,我们也会在下面的示例中展示。从公式中,我们可以看到很多来源于S的想法,没错,其实这篇文章与2012的文章是同一个作者所写,他在之前的工作中进一步的进行了研究,并提出了一个更好的办法,但这并不能说明之前的工作没有意义。 尽管有6个评估方法,而且越来越客观了,最新的研究仍然使用 P k P_k Pk和 W D WD WD两个经典的计算方法进行评估其文本分割的性能。例如IJCAI18的SEGBOT: A Generic Neural Text Segmentation Model with Pointer Network等。 实例说明我们这里以2013年的论文里的例子,来讲解一下刚才的后4种专门用在文本分割的指标的性能之间的差异。其中,m为标准分割,a为预测分割,每个灰色方块表示一个篇章单元,单元间黑线为划分位置。那么此时有11个篇章单元,2个划分位置。 从这里可以看出,Pk和WD的指标对于是完全错误还是少许错误等同看待了,当有小片段错误时,PK和WD以及S都不敏感,而B是其中最严格的,也是能够衡量出时错一点还是完全错误。(这是作者的分析思路,看看你是否和他分析的大致相同,还是有更好的见解?) 你会问,这些指标具体怎么计算?上面的公式太复杂,没关系,下面将介绍已经完成的库,直接就可以开箱即用! 代码实现正所谓别人的成果,必然有人实现过这些了。有轮子一定要用轮子,这样才能够站在巨人的肩膀上,而且通过对于源码的解读,你会对很多细节有更加深入的了解。正如《看论文看不懂时该怎么办》中讲的那样,看代码也是除了论文、PPT、视频、博文、课程之外很好的一个途径,而且是非常重要的途径,但其实也是最难的一种。2013年的论文有着相应的代码,而这个代码也是偶然通过另一个论文代码中发现的,它是一个已经封装好的python库,只需要执行pip install segeval就可以安装完成,如果你想研读其源码,传送门在此,如果你想看其文档,这里也提供。 在开始我们的实验前,我们先介绍一下对于文本分割的结果的表示形式有哪几种。就像我们刚开始讲述的任务一样,当我们对一个包含有若干个段落的文章进行一个潜在划分时,主要有以下3种形式: mass 聚类的形式,一个列表包含每个部分的篇章单元的数目。postion 这就是一个连续的序列,并将每一个主题都进行了标号划分。boundary_string 这是一个连续篇章单元的二值化的结果,值得注意的是,这个结果虽然使用1表示该篇章单元为分割边界,但是并不在最后一个篇章单元上标志为1。 # mass format [2, 3, 6] masses = [2, 3, 6] # position format (1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 3) positions = convert_masses_to_positions(masses) # boundary_string ({0},{1},{0},{0},{1},{0},{0},{0},{0},{0}) boundary_string = boundary_string_from_masses(masses)还有一种兼容NLTK形式的,如果我们要使用这种的话,可以根据传送门查看详情。 我们下面贴出代码,这个实验样例是2013年论文中的,除了一个0.95与论文中汇报不同以外(可能是论文笔误),其他全部对的上: from segeval.window.pk import pk from segeval.window.windowdiff import window_diff as WD from segeval.similarity.boundary import boundary_similarity as B from segeval.similarity.segmentation import segmentation_similarity as S if __name__ == '__main__': gold = [2, 3, 6] h_list = [[5, 6], [2, 2, 7], [2, 3, 3, 3], [1, 1, 3, 1, 5]] for n, h in enumerate(h_list): print("第%d次实验" % int(n + 1)) print("1-Pk=%.3f, 1-WD=%.3f, B=%.3f, S=%.3f" % (pk(h, gold, one_minus=True), WD(h, gold, one_minus=True, window_size=2), B(h, gold), S(h, gold)))可以得出下面的结果: 第1次实验 1-Pk=0.778, 1-WD=0.778, B=0.500, S=0.900 第2次实验 1-Pk=0.778, 1-WD=0.778, B=0.750, S=0.950 第3次实验 1-Pk=0.778, 1-WD=0.778, B=0.667, S=0.900 第4次实验 1-Pk=0.889, 1-WD=0.667, B=0.500, S=0.800就是这么简单,我们以后的文本分割的任务都可以使用这些指标进行评判了。 PS: 对于完整的评估代码,我已经开源至Github中,代码链接。 日后补充鉴于有同学提出,上述代码只是进行一个样例的评估,那么如何对测试集进行整体评估?不着急,原始的segeval也提供了相应的接口,我在此基础上又增加了两个类:seg_file.py和convert_seg_file.py,分别用于切分文件类和将结果转换为切分文件类。 在之前的evaluate_test.py中,我们也使用以下代码提供两种测试集的评估方法,一种为json格式,一种为文件夹格式。 def load_dataset_example(method=1): """ An example for loading dataset. :param method: 1 (by fold including tsv files) or 2 (by json) :return: gold_dataset, test_dataset """ # method 1: load by file fold if method == 1: gold_dataset = load_dataset(path="./data/golden", load_type=LoadTypeEnum.fold) test_dataset = load_dataset(path="./data/test", load_type=LoadTypeEnum.fold) else: gold_dataset = load_dataset(path="./data/golden.json", load_type=LoadTypeEnum.json) test_dataset = load_dataset(path="./data/test.json", load_type=LoadTypeEnum.json) return gold_dataset, test_dataset我们这里主要介绍第一种,文件夹格式,文件夹格式比较简单,我们只需要将每一个文章的结果以Mass的形式存储为每一个文件在我们的目标文件夹中,然后使用上述代码就可以以字典的形式构建出标准结果和测试结果,然后就可以的出评估结果了。 存储的形式大致如下: 通过上面的理论+样例+代码的形式,我们较为系统的理解、知道并且能够实现关于文本分割的评估过程了,在接下来,我们将会介绍几种常见的文本分割的模型以及其性能表现情况。 |
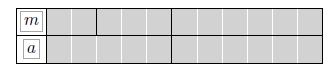 第一种情况:1-Pk=0.778,1- WD=0.778, B=0.500, S=0.900
第一种情况:1-Pk=0.778,1- WD=0.778, B=0.500, S=0.900 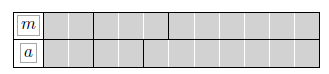 第二种情况:1-Pk=0.778,1- WD=0.778, B=0.750, S=0.950
第二种情况:1-Pk=0.778,1- WD=0.778, B=0.750, S=0.950 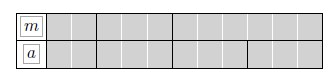 第三种情况:1-Pk=0.778, 1-WD=0.778, B=0.667, S=0.900
第三种情况:1-Pk=0.778, 1-WD=0.778, B=0.667, S=0.900 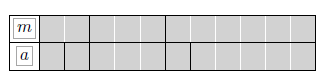 第四种情况:1-Pk=0.889, 1-WD=0.667, B=0.500, S=0.800
第四种情况:1-Pk=0.889, 1-WD=0.667, B=0.500, S=0.800 例如data/golden/test1.tsv内的形式如下(示例),其他文件内容也类似:
例如data/golden/test1.tsv内的形式如下(示例),其他文件内容也类似: 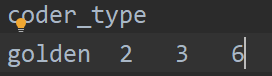 而新增加的内容主要是为了将我们的评估结果转换为这种目标形式,因此我们重点看一下新增加的两个文件内容。主要分为两步: 第一步在第一个SegFile类,就是我们内存中存储的样例形式,它主要保存3个部分:文件名,标准结果,预测结果。因此,我们只需要填充self.file_name,self.golden_masses和self.predict_masses就可以了。
而新增加的内容主要是为了将我们的评估结果转换为这种目标形式,因此我们重点看一下新增加的两个文件内容。主要分为两步: 第一步在第一个SegFile类,就是我们内存中存储的样例形式,它主要保存3个部分:文件名,标准结果,预测结果。因此,我们只需要填充self.file_name,self.golden_masses和self.predict_masses就可以了。  然后第二步主要执行convert_seg_file.py,此部分只需要完善下面这个函数即可。这个函数的功能主要是将我们预测的结果转换称实例对象SegFile的形式,并存储起来,为我们下面的执行打好基础。
然后第二步主要执行convert_seg_file.py,此部分只需要完善下面这个函数即可。这个函数的功能主要是将我们预测的结果转换称实例对象SegFile的形式,并存储起来,为我们下面的执行打好基础。  其他的部分都不重要,如果你不关心,完成上述两步后,直接点击执行即可展示出最终结果!
其他的部分都不重要,如果你不关心,完成上述两步后,直接点击执行即可展示出最终结果!【本文地址】