| 《城市群视角下的产业共聚与产业空间治理:机器学习算法的测度》评阅书及作者修改说明 | 您所在的位置:网站首页 › 如何计算EG指数 › 《城市群视角下的产业共聚与产业空间治理:机器学习算法的测度》评阅书及作者修改说明 |
《城市群视角下的产业共聚与产业空间治理:机器学习算法的测度》评阅书及作者修改说明
|
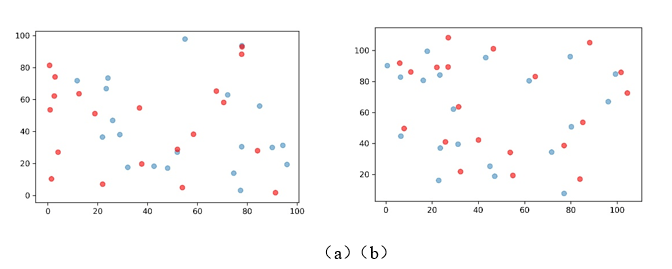
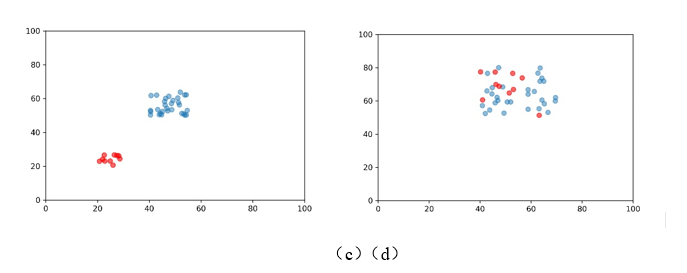
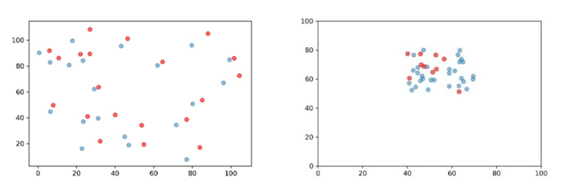
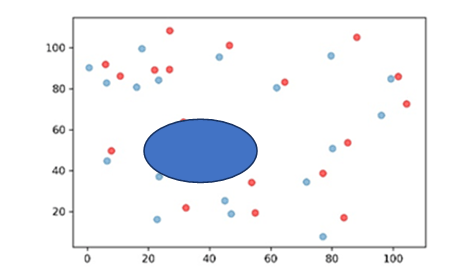
我们需要讨论的是究竟在哪一空间尺度下进行测度是较为合适的问题。Duranton 和Overman (2005 ,2008 )的DO 指数测度数据和产业共聚指数的测度数据均来自于英国,其使用Kernel 密度函数而产生的距离分布的中位数为180 公里。关于产业共聚的测度目前国内学者只使用EG 指数进行测度,尚未见到运用DO 指数或者本文使用的指数进行产业共聚测度的研究。近些年来,国内学者对基于DO 指数的产业集聚测度是随着地理信息系统的不断发展而逐渐开始应用,较为典型的是何玉梅等(2012 )、袁海红(2014 )、陈柯等(2018 )、邵朝对等(2018 )的研究,这些研究均是基于企业的微观地理信息而进行的一定区域范围内单个产业DO 指数的测度。这其中,大部分是基于全国空间尺度下进行的测度(何玉梅等,2012 ;陈柯,2018 ;邵朝对等,2018 ),其距离分布的中位数分别为2000 公里、3000 公里与1100 公里,很明显,如此大的空间尺度下,产业集聚指数可能会捕获产业集群之间的距离。也有基于单个城市(北京)空间尺度下进行的测度(袁海红,2014 ),其距离分布中位数为35 公里,实际上在这城市行政空间尺度下的克服MAUP 问题并没有意义。需要指出的是这些空间尺度的选择都是机械照搬DO 指数的结果,并不能体现这一指数的本意。英国有其独特的地理特征:一是四面环海且国土面积不大,二是地理与城市分布均匀。显然,这两点对于中国这么广袤且复杂的地理环境的国家来说并不符合。综上并结合中国的实际,本文选择城市群这一空间尺度下进行产业空间分布的测度,主要理由如下:一是新时代下产业空间新形态正在不断突破传统行政边界,逐步形成以核心城市为枢纽、多城市产业协同发展的产业空间新格局,因而基于城市群尺度的产业共聚测度具有一定的现实意义;二是城市群可以模拟出“ 四面环海” 的相对隔绝的地理空间特征,在城市群之间的非城市群城市可以作为产业分布的缓冲区域,克服MAUP 问题的同时使得研究产业共聚具有实际经济意义;三是同一城市群的地理特征与城市分布相对均质,土地面积适中,不存在较大的差异。因而城市群是一个较为合适的空间尺度。 (2)将各个独立整体的城市群分开进行测算后再进行横向比较是否具有可比性?正如论文方法所介绍,反事实比较需要基于整体内部的信息随机生成模拟产业区位集,作者在各自具有不同区位分布信息特征的城市群进行相应的反事实判断可能存在相应的问题。如果要使各个城市群之间的比较有意义,审稿人以为,各个城市群比较的随机生成模拟产业区位集需要是一样,即基准的尺子需要保持一致,对此论文是如何处理的。 回复:第二个问题是关于基于蒙特卡洛模拟的反事实检验的样本选定标准问题。首先感谢审稿专家提出的这一问题,我们的回答是本文的产业共聚指数的在各个城市群之间是可比的。对此解释如下:本文的反事实样本的选取标准为:“产业区位集k必须满足两个条件,第一个条件是产业k的企业数量与产业k的数量应当相同;第二个条件是选取随机产业区位集策略是从空间上所有已知的企业所在点的集合中进行抽取”。如果是DO指数的测度思想,各个城市群必须基于相同的距离尺度进行对比,这是因为该指数基于距离的核密度分布,通过反事实样本构建全局与局部距离置信区间带,因而各个行政区域规模的大小会导致各个城市群产业集聚结果存在比较偏差。但是,本文的产业共聚指数是并不是基于距离测度的,构建反事实样本的目的是为了验证该指数的原假设:在基于产业j空间分布既定的情况下,产业j和产业k之间不存在空间分布相似性。因此各个城市群下通过反事实样本回答这样一个问题:产业j和产业k在该空间尺度下分布相似可能性有多少,该可能性与城市群的特征并无关联,是一个与企业距离和城市群规模无关的无量纲数,因此该指数在城市群间可以直接对比。 (3)目前论文还未体现出该最新方法的矢量独特性,运用该方法探讨共聚的必要性,应该发更大篇幅对其独特性及其呈现出来的事实特征进行分析和解读。同时,在与其他共聚指标具有可比的维度上进行必要的测度比较。上述内容应该作为论文的重点分析。 回复:第三个问题是关于产业共聚指数的矢量性运用问题。我们作出如下回复: 第一,关于体现该方法的矢量独特性,本文在文章中第四部分进行了一定篇幅的阐述。一是对产业共聚的总体水平分析中,针对产业间双向共聚、单向共聚的数量、比例都进行了分析;二是城市群共聚水平的差异分析中,对不同城市群的双向共聚特征进行了重点讨论;三是城市群产业结构差异分析方面就完全基于产业共聚的方向性进行区域支柱产业的分析,本文还使用这一特性对长三角产业集群的结构进行了描绘。为了突出本文对该方法矢量特性的使用,本文修改了文章中这一方面的阐述方式。 第二,针对运用该方法探讨共聚的必要性,对此本文解释如下:产业共聚与产业集聚有本质差别,产业空间共聚强调跨产业空间分布的依赖、联结与互动关系,而产业空间集聚侧重产业总体或者单个产业的空间分布形态。产业共聚能够更好的描绘出某一区域内的相近或相关联产业的空间结构关系。产业共聚与产业集聚的重要的差别是产业共聚具有方向性,产业共聚可以与生态学中的群落的相互关系进行类比,生态学家指出,两个群落的关系如果是为了某种正向的关系而彼此依赖被称为群落间的正相互关系,在群落的正相互关系中有偏利共生(Commensalism)、原始共生(Protocooperation)和互惠共生(Mutualism)的区别,偏利共生指两个群落接触时一方有利,一方无影响,分开时一方有害,一方无影响;原始共生是指接触时彼此有利,分开时彼此无影响;互惠共生是指接触时彼此有利,分开时对彼此都有害(Odum,2004)。这种群落之间共生的方向性在总结产业群体行为特征时也有一定的适用性,这体现在跨产业企业群体的彼此接近都是为了获取某些正向利益,例如马歇尔外部性或者雅各布外部性,而这种产业群体的靠近是存在明显的方向性的,这一特征在企业选址过程中得到充分的体现,举例来说,A行业中企业的地址选择会考虑特定的B行业中企业的位置,但是B行业的企业在选址时是否会考虑A行业内企业位置是不确定的。在传统的产业共聚研究中,通过上述的EG或者DO指数进行的产业共聚测度都认为两个产业是共同集聚的(陈国亮和陈建军,2012),或者说是所谓协同集聚的(陈曦等,2018),这显然不太符合产业共聚存在单向共聚的实际情况。 为了更直观的表现产业集聚与产业共聚的差别,我们利用图像进行进一步说明,如图所示,本文通过随机模拟举出四种特殊的例子,图(a)中的两个产业在空间上均为分散,且两者间不存在依赖关系;图(b)中两个产业虽然也为分散,但是每一个蓝色产业点的附近均有红色产业点,反之亦然,因此我们可以认为虽然两个产业都分散,但是两个产业互为相互依赖,可以直观粗略的发现两者之间存在空间相互依赖关系;图(c)中两个产业从单个产业来说都为集聚,但是在两个产业间的空间分布毫无关联;图(d)中两个产业均为集聚,但是红色产业点更依赖蓝色产业点,反之则不是,因此可以看出这种依赖的方向性特征。这种两个产业间的依赖关系通过EG指数和DO指数都是无法测度的。我们十分认同审稿人提出的与其他如DO指数、EG指数等测度指标间进行比较研究的必要性,但一方面是通过DO指数进行21个城市群的测度工作量十分浩大,且由于篇幅所限,本文并没有针对其他指标的测度比较进行研究,后续可以另文讨论。
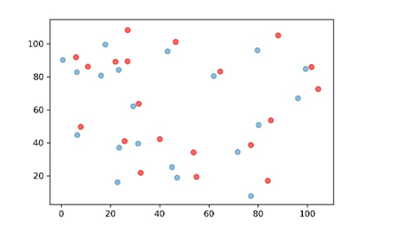
(4)现象解释上。在各个城市群产业共聚水平差异上,关于经济发展的关系与理论和现实并不太一致,可能需要进一步解读。 回复:第四个问题是关于产业共聚指数的矢量性运用问题。首先感谢审稿专家提出的这一问题和建议。我们也认同专家提出的意见,另外一位审稿专家也提出的“东部沿海城市群尤其是长三角和珠三角城市群的产业共聚指数相对较低,可能和上述地区企业竞争相对激烈有关”的建议。我们对原文进行了修改,在实证部分加入了行业竞争效应的考察,结果发现行业竞争程度从两个方向均对产业共聚产生抑制,支持了经济发达地区产业共聚偏低可能是由于行业竞争导致的假设。当然,这一现象背后可能包含着区域规模经济集聚力与竞争效应分散力多重作用的结果,类似于一些学者发现的中国产业集聚在2004年前后呈现“先集聚后分散”的特征(文东伟和冼国明,2014),产业共聚可能也存在着“先共聚后分散”的周期特征。 (5)数据上。2013年工企是2000万以上较大规模企业,代表性较弱。 回复:第五个问题是关于数据使用的问题。我们对此表示认同。工业企业数据的数据可得性使得本文只能局限于研究这些样本,我们使用2007年的数据进行测度并与2013年的结果进行比对,对比结果来看,两年的共聚水平结果基本一致且稳定。 (6)第五部分进行影响因素分析的必要性并不充足,因为作者指标的突出特征在于共聚的矢量性,但构造的各个影响因素与现有文献一致并没有明显的矢量特征,目前数据还较难构造与本文指标相匹配的影响因素,建议剔除。作者可以选取时间跨度较长的两年进行事实特征比较,集中篇幅回答本文指标显现出来的矢量特征,看能不能有较为新颖的发现,也能够丰富论文的分析层次。 回复:第六个问题关于实证的必要性以及对动态结果的展示问题。对此,我们对实证部分进行了重大修改,一是通过2012年139部门投入产出表得到了具备方向性的投入产出指标,全面验证了马歇尔外部性;二是加入行业竞争指标;三是使用滞后三期的数据消除数据的内生性问题。同时,本文测度了2007年的产业共聚结果进行时间演变的分析,一方面测算的时间将近一个多月,另一方面两年共有100万个结果的规律总结的难度较大,本文只是在原文基础上做了一些比较粗略的定性比较分析,文章重点侧重于对这一指数的应用介绍上。我们认为通过实证的定量分析可以有效弥补定性分析的不足,互为补充。本文也在未来的研究展望中提出了进一步发掘产业共聚指数方向性特征的问题,在本文中由于篇幅与时间所限,只进行了这些内容的讨论。 (7)关于反事实检验的样本选定标准问题。作者回答了本文选择的反事实的标准是“产业区位集必须满足两个条件,第一个条件是产业的企业数量与产业k的数量应当相同;第二个条件是选取随机产业区位集策略是从空间上所有已知的企业所在点的集合中进行抽取”。但审稿人更关心的是,作者测度了21个城市群,是不是基于这21个城市群内部各自的反事实进行模拟的?。比如长三角的反事实模拟是基于长三角已知所有企业的空间分布集合,珠三角的反事实模拟是基于珠三角所有已知企业的空间分布集合,因为“第二个条件是选取随机产业区位集策略是从空间上所有已知的企业所在点的集合中进行抽取”,长三角和珠三角两个所有已知的企业所在点的集合特征应该是不同,那如何可比?作者需要详细厘清比较的过程? 回复:由于上次的回复中都没有全面对这一问题进行详细解释,给审稿人带来了困惑,我们深表歉意,在此我们对这一问题进行进一步解释和说明,希望能为您释疑。 1. 从计算原理角度对指数可比性的解释 我们认同您的观点:不同城市群由于地理与人文社会环境的差异,产业空间分布会有所差异。但这对本文测度的共聚指数的可比性影响不是很大。这是因为本文的产业共聚指数Coagg是回答了一个假设检验问题——原假设:在基于产业j空间分布既定的情况下,产业j和产业k之间不存在空间分布相似性。 为了验证这个假设是否成立,我们通过蒙特卡洛模拟进行验证,观察1000次模拟中发生原假设的频率,譬如1000次模拟中发生原假设的次数是50次,则我们可以说在95%的置信度下拒绝原假设,接受备择假设:在基于产业j空间分布既定的情况下,产业j和产业k之间存在显著的空间分布相似性。而此时我们定义共聚指数Coagg(j,k)为0.95,这是蒙特卡洛模拟时违背原假设的发生频率,这样的定义决定该指数是一个连续函数,我们通过这个频率发生的高低来近似代表两个产业间方向性共聚发生的可能概率。 本文反事实样本的第二个条件所说的反事实样本就是当前所测度空间上的全体样本,就是您所理解的21个城市群各自基于各自的总体样本。例如长三角城市群2013年一共有约10万家企业,这10万家企业就是在计算长三角共聚指数时的反事实样本全集。本文在介绍方法时采取了一般性的数学论述,在整个方法介绍过程中复平面是统一的。 关于蒙特卡洛模拟次数的问题,理论上模拟的次数越多,这个数值会越精确,但是次数达到一定的数量后,结果就会趋于稳定。根据数学学科前人研究的经验,1000次是一个较为恰当的模拟次数。虽然各个城市群的总体样本规模存在一定差异,应当采取各自的模拟次数,但是本文为了统一标准,所有城市群均采用1000次的模拟方式,1000次模拟对于样本量最多的长三角来说都是适用的,因此对于其它城市群来说结果只会更稳定。 我们举一个通俗的例子来解释计算原理:假设我们通过长相的相似性来判断小王是不是小王的父亲亲生的?我们要回答这个问题也可以通过本文的方法来计算,首先我们计算小王与小王的父亲的面部相似距离(可以通过Wasserstein距离实现),然后我们假设随机找来的路人应该与小王没有血缘关系因而面部特征应当差别更大,进行1000次蒙特卡洛模拟抽样后,如果950个人都比小王的父亲与小王的面部差别更大,那么我们可以说在95%的置信度下,小王是小王的父亲亲生的,我们定义父子俩有血缘关系的可能性近似是0.95。问题是,这1000个随机的路人应当如何抽取?为了保证结果的科学性,我们要控制这些路人与小王父亲的一致性,比如年龄等要素,特别是应当要在小王出身地来进行随机抽样。这是因为对这一细节的处理会引申出下一个问题:中国小王与小王的父亲是否比美国人Jack与Jack的父亲更有可能是亲生父子?首先这个问题应该可以称之为是一个问题,同时这种判断是可比的,那么在随机抽样时小王的反事实样本应当在中国抽,Jack的反事实样本应当在美国抽。当然,我们是考虑中美之间巨大的差异,中国的广东与东北的差异会不会比这个小?为了避免不受到“其他不可观测到的因素的影响”,我们认为抽样应当在各自研究空间下抽样。 进一步通过举例说明来解释这一指数的含义,2013年机织服装制造(181)对棉纺织及印染精加工(171)的计算结果中,长三角城市群的Coagg(181,171)结果是1,珠三角城市群的Coagg(181,171)结果是0.279。我们可以理解为,基于蒙特卡洛模拟的结果,长三角城市群在95%的置信度下可以拒绝原假设H0,产业181向产业171在长三角空间下是显著共聚的,这一单向共聚发生的概率(频率)近似为1;同理,珠三角城市群在95%的置信度下不可以拒绝原假设H0,181产业向171产业是不显著共聚,这一单向共聚发生的概率(频率)近似为0.279。不管181与171这两个产业或者总体产业在两个城市群之间有多大的差别,我们只是考察181与171的分布相似性以及与171的模拟样本集之间的相似,譬如说,181产业在长三角是集聚的,在珠三角是分散的,这完全不影响测算在各自空间下181与171的分布相似性,这就是本文利用Wasserstein距离测算两个离散分布相似性的巨大优势。 综上,通过本文提出的共聚指数可以获得两个结论:1、在一定的置信度下,两个产业在指定空间下是否显著共聚;2、某一空间下两个产业间共聚的可能性(违背原假设的发生频率)大小,属于无量纲量。这两个结论在不同城市群之间应当是可比的。 (8)共聚指的是不同行业间的集聚形态,很多都是上下游关联,作者从行业竞争效应解释尚缺乏说服力,审稿人以为,这是否与作者将本是不同的、独立的城市群测度结果对比有关? 回复:关于竞争效应问题。坦白的说,竞争效应变量在开始我们并未关注,后来是应另外一位审稿专家要求加入的。为了考察竞争效应对本文实证结果的影响,我在剔除这一变量后重新进行了回归,如下表所示。可以看到,竞争指标加入前后并不影响其他指标的稳健性,鉴于该竞争指标在一定程度上解释了一些沿海发达城市群产业共聚程度较低的问题,同时也尊重两位审稿人的建设性意见和建议,我们在正文中汇报了加入这一指标的结果并以附注的形式对剔除后的结果进行了说明。
(9)关于指标可比性的问题,作者既然承认“不同城市群由于地理与人文社会环境的差异,产业空间分布有所差异”,那测度的各自整体城市群内部情况就不应该进行横向比较。作者指出原假设是“产业j空间分布既定的情况下,产业j和产业k之间是否存在空间分布相似性”,这意味着测度共聚时,其中有一个产业j空间分布是既定的,那么长三角、珠三角等等独立整体的城市群产业j的空间分布是不同的,这又何来可比呢?另外,作者指出“本文反事实样本的第二个条件所说的就是当前所测度空间上的全体样本,就是您所理解的21个城市群各自基于各自的总体样本”,既然每个城市群内部的原有企业是作为全体样本,被视作总体,那要比较的是总体内部的分样本特征,所谓总体是研究对象的全部样本,研究中怎么可能存在两个甚至多个总体样本。拿作者举的中国人和美国人来说,既然已经视中国人是一个总体样本,美国人是一个总体样本,那我们还有何意义比较这两个总体,如果要比较那应该视中国人和美国人为一个总体,把他们放一起作为一个总体然后再比较才有意义。 作者的测度是先将21个城市视为独立的21个总体,然后再基于这21个独立总体内部的企业分布特征模拟得到各自独立城市群内部的产业共聚情况,最后将已经视作各自总体的测度结果当成分样本属性来比较。这种理解可以在最后一部分实证回归得到非常明显的验证,既然每个城市群在测度模拟时当成了总体样本,那么回归就应该基于21个各自城市群进行。 回复:首先,对于您这次的意见和建议,我们团队进行了在线讨论与学习,并且就您提出这一抽样方法的可比性问题专门请教多位数学、统计学背景的博士、老师和相关参考文献原作者。我们得到的答复是本文的指数是可比的。 我们进一步就这一问题进行了文献查阅和方法模拟,最后我们团队对您提出的问题表示认同,这一方法的抽样总体的差异确实会引发对比标准的不一致,进而产生一定的统计学瑕疵。我们对此进行深入的思考,对产业集聚以及共聚领域采用蒙特卡洛模拟构建反事实的样本的做法进行了追根溯源,我们对此进行了总结。 请您先看下图:
在这个复平面空间上,我们随机生成了20个红色点(产业j)与20个蓝色点(产业k),我们生成的时候设置了一个要求,即红点必须随机出现在蓝点半径10单元的周围,也就是说从上帝视角来看,产业j(红点)是向产业k(蓝点)共聚的。现在不知道这个设置一个人,他如何判断产业j是不是向产业k共聚呢?那么他提出原假设:“产业j空间分布既定的情况下,产业j和产业k之间不存在空间分布相似性”。在红点固定的情况下,随机生成20个蓝点,我们认为红点是不会向这随机生成的20个蓝点靠近的,即符合原假设,我们通过1000次模拟去构建原假设集。请注意,当前复平面空间下目前没有其他的点,我们如何抽取这20个点呢?最行之有效的方法就是生成随机生成0-120之间的横纵坐标来确定点,而这个时候的抽样总体是无穷大的。 接下来我们再来讨论,下面这两张图,左边还是刚刚那张,右边这张的复平面大小有所减少,红蓝点的数量也与左边图不一样,两个产业的分布也是不一样的,但是我们事实上也进行了红点必须随机出现在蓝点附近的设置。如果我们继续通过这个抽样方式,左右两边的抽样总体是一致的,也就是均是无穷大。通过我们的测度方法模拟,我们测得左侧图的=1,且10次模拟结果均为1,非常稳定;右侧图的也等于1,结果也非常稳定。
如果就这两张图来说,这两个复平面空间下进行我们方法的测度结果可以认为是不存在统计瑕疵的,是完全可比的。 但是,我们实际情况下实现这种完美抽样并不那么轻松,请看下图:
还是刚刚第一张图,这个空间中央有个湖,如果我们仍然采用原先的抽样方法,那么就会对估计的无偏性产生影响,因为这个湖里的点是永远不会有企业的,如果仍然使用上面的做法,这会使得抽样总体被扩大化了,这会导致我们的测度结果出现虚假的显著性。那么我们如果仍然要进行完美抽样的话,那就需要把这个湖去掉,用剩下的区域进行随机抽样。 扣去上图中的湖是容易实现的,但是实际上,我们在研究产业空间分布的地图上不仅有湖泊,还有山川、森林、道路、农田和商业区等等这些都永远不可能有制造业企业的地方,这些分布的形状没有规则,要把这些区域完全从地图上剔除,这是非常困难的,如何解决这一问题呢?最早提出采用蒙特卡洛空间模拟反事实样本是Duranton和Overman(2005)提出DO指数的文章,文章中关于这一问题的解决方案如下,Manufacturing cannot locate in many areas of the country (e.g. the Lake District,London’s green belt, etc.). Hence, to control for overall agglomeration and theregulatory framework, we consider that the set of all existing “sites”。产业在一个区域内可以选址的地方是有限的,为了控制总体的集聚和研究框架的稳定性,考虑将已经存在的样本点替代为“总体”。 因此,我们可以得出以下几个结论:1.Duranton他们的抽样也不是完美抽样,这一方式抽样会使得抽样总样本的缩小,使得出现伪不显著的情况,使得产业集聚显著的门槛提高了;2.这一方式明显是两害相权取其轻的做法,在实际“完美总体”无法获取的情况下,使用的相对损害较轻的替代抽样方案;3.这一方案被Billings和Johnson的2016年产业共聚的文章直接采纳,是一种采取“惯例”的做法。 那么,这样相对存在一定统计瑕疵的指标能不能进行一定程度上的跨区域对比呢?我们提出了一点看法,仅供审稿人参考。我们团队的判断是:各个城市群之间全部产业的总体分布的差异可能主要来自不可开发土地的分布的影响,总体来说,这些不可开发土地本身就是应当是被剔除的,当城市群的企业样本比较大的时候,城市群企业的总体样本与“完美样本”之间的差异应当是在一个比较小的可以控制的范围内,因此进行一定程度的跨区域比较也许在某种程度上可以提供一些研究价值。因为一旦否认了这种相对的可比性,不仅跨区域的比较是不科学的,跨时间的比较也是不合理的(抽样总体也发生了变化),这会极大的压缩现有整个产业集聚与共聚的研究空间,因为从目前的文献检索来看,国内外使用DO指数进行同一空间下跨时间的比较的文章的数量也是非常多的。 我们的结论是:必须承认,该方法下的产业共聚的总体样本是存在一定的统计学瑕疵的,但是就补充目前的研究空白的紧迫性来说,我们是否可以忽略这样的统计意义上的瑕疵呢?我们的理解,很多经济学指标在理论上是可以比较的,但实践中也会因统计误差带来一定的不可性,即使像人均GDP这样常用的指标,在不同区域比较时,也会因各地区市场经济的发展水平不同,所产生的统计遗漏不一样(市场化低的地区遗漏的非市场活动创造的价值愈多),也无法成为完美的对比指标。但为了研究的需要,我们很多情况下退而求其次,只能在目前的水平和手段下追求“次优”的结果。 当然,我们完全承认,您提出的在全国层面或者在一个城市群层面进行产业共聚指数测度的修改方案是十分严谨的。但是如果进行全国层面的测度,由于我们的计算能力所限,三位数产业分类下的产业规模较大,这会极大增加产业共聚指数的计算复杂度,我们将要计算超过35000个结果,以我们目前的计算水平,每个结果的计算时间预计均需要12个小时以上的时间,这也意味着虽然理论上可以在全国层面上测度,但实践上受我们自己能力的限制几乎不可能。 外审意见2及作者修改说明 该文基于微观企业地理数据,运用矩阵扩张Sinkhorn算法与熵正则化项约束法改进Wasserstein距离算法与求解方式,测算了中国21个城市群内产业共聚水平;从总体水平、区域特征和行业特征描述城市群产业共聚的总体概况,并探讨影响产业共聚的影响因素。综合来看,该文最大的创新在于,从微观企业层面构建产业共聚指数,为测度中国城市群空间尺度下的产业共聚水平提供可靠的算法支持,并基于此对跨区域产业共聚影响因素的实证研究提供证据支持。 具体而言,该文仍然存在一些不足之处: (1)作者在论述基于Wasserstein距离的产业分布距离测算的过程中,并未详细阐述作者是如何将Wasserstein距离测算运用到产业空间共聚的。对尚未接触过该方法的读者而言,如何运用此方法进行产业空间分布距离测算仍然是不明晰的。在此基础上,进一步阐述图1表达的含义也是必要的。 (2)在文章第四部分,作者将产业共聚划分为双向共聚和单向共聚,那么,影响这两种产业共聚的因素是否完全相同?作者认为产业共聚的方向性是有意义的,但作者在文章的后续分析中尚未探讨和回答该问题,这也是文章的一个遗憾;与此同时,在经典的产业集聚研究中,产业共聚的一个重要作用是通过集聚获得上下游的关联效应,而这也可以认为是文章中提及的同行业产业共聚水平高于跨行业产业共聚的佐证。那么,产业双向或者单向共聚,是否与产业所处的生产链环节有关?这也是作者需要回答的重要问题。 回复:第二个问题是关于双向共聚与单向共聚行业特征的问题。匿名审稿专家具体指出:“进一步阐述产业双向共聚和单向共聚的行业特征,可结合文章产业结构差异部分的相关内容,进一步探讨产业关联与产业共聚的关系。”此我们表示认同和感谢。对此我们在实证部分已经加入了投入产出关系变量,全面验证马歇尔效应。实证结果证明产业关联与产业共聚为正相关。而具体行业特征上的分析,由于文章的篇幅所限,不在这篇文章中展开讨论。 (3)根据新经济地理学的理论研究,产业在空间上共聚与否实际上是竞争效应和集聚效应相互作用的结果。东部沿海城市群尤其是长三角和珠三角城市群的产业共聚指数相对较低,可能和上述地区企业竞争相对激烈有关。作者在第五部分影响因素的分析中,着重考虑城市群内集聚效应,而并未考虑区域内企业之间的竞争效应,这也是需要进一步思考的。 回复:第三个问题是关于竞争效应问题。匿名审稿专家具体指出:“在实证模型中考虑竞争效应的影响。”对此我们表示认同和感谢,非常感谢审稿专家提出的宝贵建议。我们在模型中从共聚产业与被共聚产业两个方向加入行业竞争变量,结果显示从两个方向上竞争效应都显著抑制了产业共聚的发生,与审稿专家关于经济发达地区的竞争效应导致的空间共聚降低的论断不谋而合。 (4)结合表3、附录表2和附录表3,产业共聚水平较高的晋中城市群、长株潭城市群等,其结构性主导产业分别为金属制品业、通用设备和专用设备制造业等。相比纺织业和计算机设备行业,这些重工业生产链相对较长,生产工序相对复杂,与之关联的行业也更多。这一点,从文章图5中,通用设备制造业与其他行业的互动较多也可以看出。那么,这可能也是主导产业结构导致城市产业共聚指数较高的原因,而并非完全是作者解释的城市经济发展水平。 回复:第四个问题关于“加入金属制品业、通用设备和专用设备制造业等行业的特征分析”的建议,对此我们表示认同和感谢,非常感谢您提出的宝贵建议。本文在结构性支柱产业部分加入了这些产业成为主导产业是由其行业特征引致的表述。 (5)作者仅用一年的截面数据解释产业共聚的影响因素,可能存在互为因果问题。作者在研究展望中也提及产业共聚测算难度导致无法展示动态演变过程,建议作者在影响因素分析中尽量采用历史数据或者滞后年份数据克服互为因果问题。 回复:第五个问题关于实证数据内生性的问题。匿名审稿专家具体指出:“考虑并处理截面数据可能存在的互为因果问题。”对此我们表示认同和感谢。本文遵从审稿专家的建议,使用2012年的投入产出指标,其余指标滞后三期使用2010年的数据。实证结果表明与原结果一致。 (6)作者在特征分析中一再强调政府产业政策对产业共聚的影响,在实证分析中也考虑了政府规模的影响。但是,仅仅从政府规模的视角讨论空间集聚往往是不够的,且作者对实证结果的解释也缺乏充足的说服力。因此,如果从政府主导产业政策等视角来考察,可能更为贴切。 回复:关于更换政府政策指标的建议。对此我们表示认同和感谢。由于政府政策指标的可获得较差,本文对这一方面暂时没有很好的解决方案,由于本文着重验证马歇尔效应与行业竞争效应对产业共聚的影响,因此这一问题我们放入了研究展望中。感谢匿名审稿人提出的宝贵意见,本研究团队会进一步认真思考,另文专题讨论政府政策对产业空间共聚的影响。 外审意见3及作者修改说明 (1)本文意图探讨两大问题,一是运用新方法刻画城市群产业共聚的相关特征;二是实证研究了产业间共聚的影响因素。不过,相对而言,无论是从内容丰富程度与研究深度等方面,有关产业共聚影响因素的实证显得较为欠缺,这是该文章的一大主要不足。 第一,本文实证的框架基本还是立足于探讨产业集聚的基本机制(共享、匹配、学习等),创新在于被解释变量是新方法测度的,但是,结论也是类似的,而且,其中劳动力池、知识溢出等变量实际上是值得商榷的,如果说产业共聚影响因素的探索是本文的核心内容之一,那么,目前的实证策略和深度是不够的。 第二,有关一些建议。本文采用的新方法测度产业共聚,相比于以往的方法,具有很多的优势。那么,是否可以在做产业共聚影响因素的实证中,针对新方法测度的新内容做一些实证,比如,产业共聚的方向性,可以探索为何不同产业间共聚的依赖程度不一样等等。总体上而言,建议实证可以针对新方法获取的新内容进行,如果仅仅把新方法测度的产业共聚程度当作一个老问题的新变量,然后基于传统的理论进行一下实证,有点浪费了作者大量工作后获得的新资源。 回复:第一个问题有关文章结构与实证部分的问题。匿名审稿专家具体指出:“相对而言,无论是从内容丰富程度与研究深度等方面,有关产业共聚影响因素的实证显得较为欠缺,这是该文章的一大主要不足。”我们团队非常感谢审稿人提出的文章结构的不平衡问题,对此我们表示认同。本文的主要工作量是通过机器学习算法对Wasserstein距离进行改进,通过蒙特卡洛模拟构建产业共聚指数,同时基于这一指数做了很多创新性的拓展:比如通过生态学概念进行类比、进行城市群基于描述性统计层面的产业共聚总体水平的比较、不同城市群产业共聚指数分布的模式归类、单个城市群内部产业集群结构的刻画等等。文章的前半部分耗费了我们大量的精力与时间,而且从篇幅上来说,文章的大量篇幅都在讨论对于产业共聚方法改进与中国21个城市群测度的结果展示,实证上确实有所偏废。对此我们做出了如下调整: 第一,结合匿名审稿专家第二个问题的建议:“建议作者不要强调城市群,仅以城市群为视角展开研究”。我们首先调整了文章的题目,将原题目改为:“城市群视角下的产业共聚与产业空间治理:基于机器学习算法测度研究”,即我们不再将测度与影响因素在题目中表现为对等的位置,而是突出表现测度。不过我们对实证部分仍然于以保留,坦率的说,我们主要的参照文献是Ellison et al.(2010)和Billings and Johnson(2016)的两篇文章,本文的文章结构大体与这两篇文章相似,采用这一结构是想通过实证结果验证本文测度结果与这两篇文章的一致性。 ,而对于实证的深度与广度的拓展,我们进行了改动与调整。匿名审稿专家提出:“总体上而言,建议实证可以针对新方法获取的新内容进行,如果仅仅把新方法测度的产业共聚程度当作一个老问题的新变量,然后基于传统的理论进行一下实证,有点浪费了作者大量工作后获得的新资源。”我们非常认同您提出的这一观点,我们承认在实证处理上,囿于参考国外文献的结构框架,以及数据方面的局限,我们被提出这一产业共聚指数理念的Billings and Johnson(2016)的文章“画地为牢”了。在Billings and Johnson(2016)的文章中,共聚指数的影响指标均从马歇尔外部性出发,实际验证时也只有投入产出一个指标具有方向性,加之该文章只测度了一个区域,因此缺乏对于区域差异的考察,本文的原意在于对其在区域差异的研究补充。 对于该新方法开发的新指标的应用,我们团队已经开展了一定的研究,也初步得到了一些研究成果。对于产业共聚指标方向性的研究拓展,我们团队主要从两个方面展开,一是保持被解释变量不变,开发解释变量的方向性;二是针对被解释变量分离出共聚与被共聚两个方向的衍生指标,譬如一个产业被多少个产业显著共聚和向多少个产业显著共聚两个维度构建指标。 我们对本文的实证修改采用第一种策略即进一步开发解释变量的方向性。通过大量的文献查阅,我们发现Hidalgo et al.(2007)提出的产品临近度指标可供借鉴,该指标计算公式如下:
为c国家(或城市)产业j的显性比较优势。该指标将产业k具备比较优势的条件下产业j具备比较优势的条件概率与产业j具备比较优势的条件下产业k具备比较优势的条件概率中的较小值用来衡量产品邻近度。Guo and He(2016)和贺灿飞和胡绪千(2019)对这指标进一步拓展和引申,将其用于度量产业间的技术关联,可以理解为“产品邻近”是由于产业间的技术关联引致的。不过从这一指标的定义中我们可以发现,通过取较小值使得该指标原本可以具备的方向性消失了。Hidalgo et al.(2007)在文中并没有具体解释为何要取两者之间的较小值表示两个产业间的邻近度,而毛琦梁和王菲(2017)在应用该指标时提出了如下解释:“由于两种产品相互间的条件概率未必相等,但两种产品之间邻近度应该是定值,考虑到同时生产两种产品所需条件相对严苛,故取条件概率最小值作为产品邻近度的衡量标准。”我们对此进行了深入思考,认为如果从产业技术关联而引致产品邻近的角度出发,应当不存在两个产品的邻近度应当是定值的硬性标准,这是因为生产两种产品的技术优势如果彼此依赖,那么这种技术依赖不一定是对称的,因此,我们在本文中借鉴该指标的思想,直接定义产业j对产业k产生技术关联(依赖)的概率为:
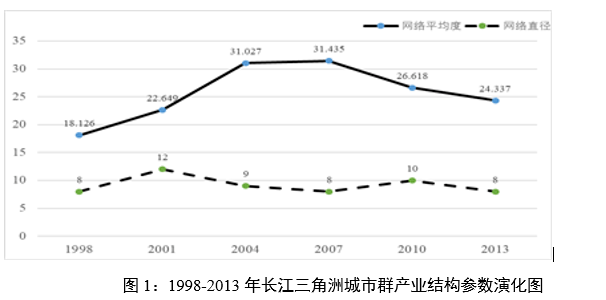
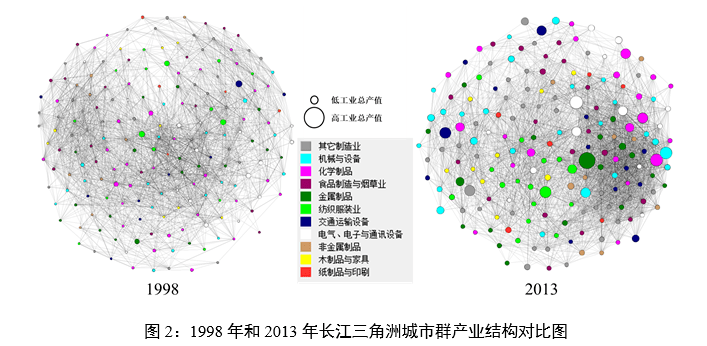
即产业k具备比较优势的条件下产业j具备比较优势的条件概率,这一定义既符合一定的经济直觉,同时也与本文的产业共聚指数的方向性能够匹配。我们团队测度了2010年全国层面191个三位数产业间的双向技术关联概率,共测度了36290个结果,并与产业共聚指数进行匹配。实证结果表明,产业间的技术依赖正向影响产业间的共聚发生可能性,这一结论符合经济直觉。 匿名审稿专家同时指出:“其中劳动力池、知识溢出等变量实际上是值得商榷的。”对此,我们进一步删除了劳动力池、知识溢出、技术差距等具有测度争议的指标,从前后结果看,删除这些指标后不影响其他指标的结论,说明本文的实证结果是稳健的。删除这些指标后,我们将本文的主要实证重心调整为针对方向性的投入产出依赖与技术依赖的检验上,并兼顾讨论区域差异,我们也调整了文章摘要、引言等处的表述。 回复:感谢审稿人的意见。关于城市群的空间选择,我们团队在最初也比较纠结,我们的选项有:全国、省域、地级市与城市群。坦率的说,全国这一尺度的计算复杂度非常高,当时对于这一算法结果未知的情况下,计算的成本很大,因此我们放弃了全国尺度;而选择省域与地级市尺度我们担心被诟病克服MAUP 问题没有意义。而Billings and Johnson (2016 )的产业共聚指数正是基于“丹佛- 奥罗拉- 莱克伍德”大都市功能区数据进行测度的,而美国大都市功能区与中国的城市群的概念与规模较为接近,基于城市群尺度的产业共聚指数的测度结果更具国际可比性。综合之下,我们最终选择了城市群这一空间尺度。 同时,在文章几易其稿的过程中,编辑部对我们也有拔高文章立意的期许。实际上,由于城市群内部一体化水平较高,城市群正在成为中国产业空间发展的主要载体,对此我们着重在文章的引言与最后的结论中突出了城市群空间尺度下的产业空间治理的重要性。 (3)本文有些结论有待值得商榷,本文目前更多的工作是利用一种新方法刻画了或者说发现了一些现象,但是对于这些现象的解释并不深入。或者,如第一条意见所言,作者可以就新方法发现的现象做针对性的实证以探索影响机制。比如本文研究发现“经济发展水平较高的城市群产业共聚水平反而较低”,在政策启示中提出“经济发展水平较高的城市群产业共聚水平反而较低,可能是由其较高的土地、税收等一系列经营成本的激增导致了产业空间分布的提前分散化,这种趋势并非是在完全市场机制下的产业合理布局,因此发达城市群的地方政府应该合理管控土地、税收成本,减轻企业负担,促进其产业合理有效的空间共聚”。又比如,研究结果表明“当前技术密集型行业整体共聚水平不高的现状”,作者针对这个结论在政策启示中论述“地方政府应当进一步为高技术产业的共聚提供良好的外部条件,一方面要尊重技术差距对产业共聚影响的客观规律,……;另一方面是经济落后地区应当进一步发挥市场的自发力量……,但是产业间能否实现合理的产业配置,发挥共聚效应,仍然需要进一步借助市场力量优化当前技术密集型产业的空间布局。”诸如此类的结论,实际上隐含着作者认为产业共聚水平应该很高的结论,但事实上,产业共聚作为一种多维因素共同决定的产业生态系统,究竟何种共聚程度比较合适是很难定论的。比如,针对“经济发展水平较高的城市群产业共聚水平反而较低”,城市群之间也是分工的,不同城市群的产业结构并不一致,因此,产业共聚水平肯定也是不一样,那么究竟这和城市群经济发展水平有没有关系,是需要也是值得进一步去探索的,并不能就认为“经济发展水平较高的城市群产业共聚水平反而较低,这种趋势并非是在完全市场机制下的产业合理布局”。有关技术密集型产业结论的解读也是类似。作者创新性地开发了刻画产业共聚的新方法,据此通过大量的工作也发现了很多现象和特征,但是,欠缺对于这些产业共聚特征的解释,目前更多的停留在展示现象的阶段,建议作者在这方面加强。 回复:匿名审稿专家指出:“本文有些结论有待值得商榷,本文目前更多的工作是利用一种新方法刻画了或者说发现了一些现象,但是对于这些现象的解释并不深入。”我们非常认同您的批评,对您提出的这一问题表示非常的感谢。我们极为认同您的论断:“产业共聚作为一种多维因素共同决定的产业生态系统,究竟何种共聚程度比较合适是很难定论的。”我们团队非常钦佩您对这一问题的深刻认识,事实上,我们也在目前开展的后续研究中找到了您这一观点的佐证。我们团队在最新的研究中着重研究了长江三角洲城市群1998-2013年的产业共聚的演变,我们发现长三角城市群经历了共聚水平升高后逐步降低的趋势(图1),且产业网络结构中也表现出明显的结构优化特征(图2)。
我们团队对于这一指标的认识也是一个逐步发展的过程,在最开始只计算了一年结果的时候,对“经济落后地区的产业共聚水平较低”这一问题也存在一定的困惑,我们当时也将其与产业集聚的先趋于集聚后趋于分散的特征联系起来,因此才会有“经济发展水平较高的城市群产业共聚水平反而较低,可能是由其较高的土地、税收等一系列经营成本的激增导致了产业空间分布的提前分散化,这种趋势并非是在完全市场机制下的产业合理布局…”这样的政策建议。 对此,我们作出如下修改:一是修改文章中对于产业共聚带有主观态度的表述,以更为客观中立的态度看待产业的共聚水平;二是修改本文的政策建议,强调本文的测度结果对产业空间分布、产业共聚关联与产业空间结构认识的帮助,对于产业空间治理作为一个工具来使用,使得本文的结论更具备一定的客观性。 当然我们也承认我们的研究是初步的也是启发式的,很多的表述和研究内容存在一定的不足,本文的很多结果在中国应当都是首次进行测度和研究,与传统产业集聚的结论有所不同我们认为也是可以进一步思考与讨论的。当然,我们也深切的希望我们基于此文章来吸引更多的同行来关注这类研究。 (4)该文作者对于有待商榷之处做出了比较好的解答以及较好的改进,不过,仍有一个方面想和作者进行深入的交流和探讨。 该文将原题目改为:“城市群视角下的产业共聚与产业空间治理:基于机器学习算法的测度”,即不再将测度与影响因素在题目中表现为对等的位置,而是突出表现测度。不过,又形成了新的结构平衡问题。诚如本文所言,致力于解决两个方面的问题:一是如何科学准确的测度区域产业间的共聚关系,以及如何通过产业间共聚的方向性进一步刻画产业体系结构的问题;二是从产业共聚的角度出发,政府可以从哪些方面入手实施产业空间治理?本文对于第一个问题的研究非常出色,而且也非常认可这是未来的研究提升方向,相信会成为后续研究的重要参考。相对而言,有关第二个问题的研究有点不足,虽然能够理解本文希望在产业共聚刻画以及影响因素实证检验的基础上,提出实施产业空间治理的科学依据。但最终有关产业空间治理的内容是作为政策建议在结论部分出现,如此处理,显得有点薄弱了,而且内容结构对应于题目而言,有点不平衡。 回复:感谢审稿专家的意见,我们非常认同您的观点。按照审稿人专家的意见,我们在最后一节提出从静态与动态特征全面描绘区域内部产业空间,并进一步分析产业空间共聚的影响因素,为城市群决策者开展产业空间治理提供了一个分析框架。 具体来说,我们做出了如下修改,分别从静态、动态和影响因素三个维度考察区域内的产业共聚。从静态角度看,中国城市群层面同二位数产业共聚水平显著高于全部产业共聚水平与跨二位数产业共聚水平,不同城市群的产业共聚分布存在显著差异,产业空间核心产业各具特色,初步形成了全国范围内的产业分工格局。从动态角度看,中国城市群产业空间共聚水平总体呈下降态势,不同城市群之间表现出具有产业共聚总体两极分化与局部产业合作纵深发展等特征的差异化演化模式。从产业共聚与产业空间的影响因素看,产业层面上投入产出关联与技术关联对产业间的共聚发生的影响显著,产业间规模差距产生了跨产业的学习效应;在城市群层面上的政府规模、经济水平、交通基础设施与开放程度都不同程度的与产业共聚负相关。 囿于文章篇幅的限制,未能将这一部分展开自成一节进行深入的讨论。在未来的研究中,我们会按照您的建议进一步探讨这一问题,形成一个比较严谨的、系统的认知框架或体系,讨论怎么基于产业共聚来认识和实施产业空间治理。关于产业共聚的影响因素分析,我们研究团队会在现有研究的基础上进一步深入探讨,也希望在未来能够与审稿人能进一步交流与合作。再次感谢审稿人的宝贵意见与建议! 参考文献 [1] 陈国亮,陈建军. 产业关联、空间地理与二三产业共同集聚——来自中国212个城市的经验考察[J]. 管理世界. 2012,(4): 82-100. [2] 陈柯,张晓嘉,韩清. 中国工业产业空间集聚的测量及特征研究[J]. 上海经济研究. 2018(07):30-42. [3] 陈曦,朱建华,李国平. 中国制造业产业间协同集聚的区域差异及其影响因素[J]. 经济地理. 2018, (12): 104-110. [4] 何玉梅,刘修岩,李锐. 基于连续距离的制造业空间集聚演变及其驱动因素研究[J]. 财经研究. 2012,38(10): 36-46. [5] 毛琦梁,王菲.比较优势、可达性与产业升级路径——基于中国地区产品空间的实证分析[J].经济科学,2017(01):48-62. [6] 邵朝对,苏丹妮,李坤望. 跨越边界的集聚:空间特征与驱动因素[J]. 财贸经济. 2018, (4): 99-113. [7]文东伟,冼国明. 中国制造业产业集聚的程度及其演变趋势:1998—2009年[J]. 世界经济.2014, (3): 3-31. [8] 袁海红,张华,曾洪勇. 产业集聚的测度及其动态变化——基于北京企业微观数据的研究[J]. 中国工业经济. 2014,(9):38-50. [9] Billings, S. B., and E. B. Johnson. Agglomeration within an UrbanArea[J]. Journal of Urban Economics, 2016, (91): 13-25. [10] Delgado, M., M. E. Porter, and S. Stern.Defining Clusters of Related Industries[J]. Journal of Economic Geography,2016, 16(1): 1-38. [11] Duranton, G., and H. G. Overman. Testing for Localization UsingMicro-Geographic Data[J]. The Review of Economic Studies, 2005, 72(4):1077-1106. [12] Ellison, G., and E. L. Glaeser. Geographic Concentration in USManufacturing Industries: A Dartboard Approach[J]. Journal of PoliticalEconomy, 1997, 105(5): 889-927. [13] Ellison, G., and E. L. Glaeser, W. R. Kerr. What Causes IndustryAgglomeration? Evidence from Coagglomeration Patterns[J]. American EconomicReview, 2010, 100(3): 1195-1213. [14] Guo, Q., C. He. Production Space and Regional Industrial Evolutionin China[J]. Geo Journal, 2017, 82(2): 379-396. [15] Hidalgo, C. A., B. Klinger, A. L. Barabási, and R. Hausmann. TheProduct Space Conditions the Development of Nations[J]. Science, 2007,317(5837): 482-487. [16] Odum, E. P.Fundamentals of Ecology[M]. Stanford, CT: Cengage Learning, 2004. 推文主编:覃毅 推文编辑:王普鹤返回搜狐,查看更多 |
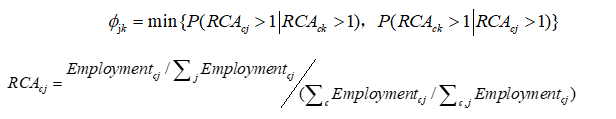
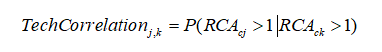
【本文地址】