| 为什么索引会加快查询速度?索引原理和使用原则 | 您所在的位置:网站首页 › 如何根据索引查询数据库表 › 为什么索引会加快查询速度?索引原理和使用原则 |
为什么索引会加快查询速度?索引原理和使用原则
|
索引是什么?
索引图解
定义:数据库索引,是数据库管理系统(DBMS)中一个排序的数据结构,以协助快速查询、 更新数据库表中数据。
在 InnoDB 里面,索引类型有三种,普通索引、唯一索引(主键索引是特殊的唯一 索引)、全文索引。 普通(Normal):也叫非唯一索引,是最普通的索引,没有任何的限制。唯一(Unique):唯一索引要求键值不能重复。另外需要注意的是,主键索引是一 种特殊的唯一索引,它还多了一个限制条件,要求键值不能为空。主键索引用 primay key 创建。全文(Fulltext):针对比较大的数据,比如我们存放的是消息内容,有几 KB 的数 据的这种情况,如果要解决 like 查询效率低的问题,可以创建全文索引。只有文本类型 的字段才可以创建全文索引,比如 char、varchar、text。 InnoDB 逻辑存储结构https://dev.mysql.com/doc/refman/5.7/en/innodb-disk-management.html https://dev.mysql.com/doc/refman/5.7/en/innodb-file-space.html MySQL 的存储结构分为 5 级:表空间、段、簇、页、行。
段 Segment 表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等,段是一个逻辑 的概念。一个 ibd 文件(独立表空间文件)里面会由很多个段组成。 创建一个索引会创建两个段,一个是索引段:leaf node segment,一个是数据段: non-leaf node segment。索引段管理非叶子节点的数据。数据段管理叶子节点的数据。 也就是说,一个表的段数,就是索引的个数乘以 2。 簇 Extent 一个段(Segment)又由很多的簇(也可以叫区)组成,每个区的大小是 1MB(64 个连续的页)。 每一个段至少会有一个簇,一个段所管理的空间大小是无限的,可以一直扩展下去, 但是扩展的最小单位就是簇。 页 Page 为了高效管理物理空间,对簇进一步细分,就得到了页。簇是由连续的页(Page) 组成的空间,一个簇中有 64 个连续的页。 (1MB/16KB=64)。这些页面在物理上和 逻辑上都是连续的。 跟大多数数据库一样,InnoDB 也有页的概念(也可以称为块),每个页默认 16KB。 页是 InnoDB 存储引擎磁盘管理的最小单位,通过 innodb_page_size 设置。 一个表空间最多拥有 2^32 个页,默认情况下一个页的大小为 16KB,也就是说一个 表空间最多存储 64TB 的数据。 注意,文件系统中,也有页的概念。 操作系统和内存打交道,最小的单位是页 Page。文件系统的内存页通常是 4K。
在 Navicat 的工具中,创建索引,索引方式有两种 Hash 和 B Tree。 HASH:以 KV 的形式检索数据,也就是说,它会根据索引字段生成哈希码和指针, 指针指向数据 |
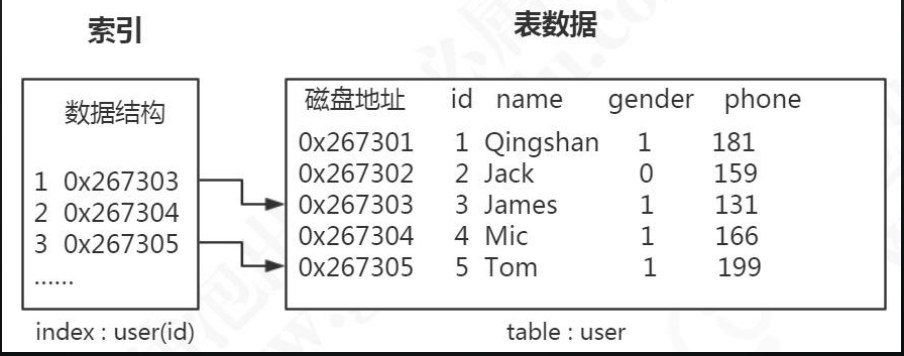 首先数据是以文件的形式存放在磁盘上面的,每一行数据都有它的磁盘地址。如果 没有索引的话,要从 500 万行数据里面检索一条数据,只能依次遍历这张表的全部数据, 直到找到这条数据。 但是有了索引之后,只需要在索引里面去检索这条数据就行了,因为它是一种特殊 的专门用来快速检索的数据结构,我们找到数据存放的磁盘地址以后,就可以拿到数据 了。就像我们从一本 500 页的书里面去找特定的一小节的内容,肯定不可能从第一页开 始翻。那么这本书有专门的目录,它可能只有几页的内容,它是按页码来组织的,可以 根据拼音或者偏旁部首来查找,只要确定内容对应的页码,就能很快地找到我们想要的 内容
首先数据是以文件的形式存放在磁盘上面的,每一行数据都有它的磁盘地址。如果 没有索引的话,要从 500 万行数据里面检索一条数据,只能依次遍历这张表的全部数据, 直到找到这条数据。 但是有了索引之后,只需要在索引里面去检索这条数据就行了,因为它是一种特殊 的专门用来快速检索的数据结构,我们找到数据存放的磁盘地址以后,就可以拿到数据 了。就像我们从一本 500 页的书里面去找特定的一小节的内容,肯定不可能从第一页开 始翻。那么这本书有专门的目录,它可能只有几页的内容,它是按页码来组织的,可以 根据拼音或者偏旁部首来查找,只要确定内容对应的页码,就能很快地找到我们想要的 内容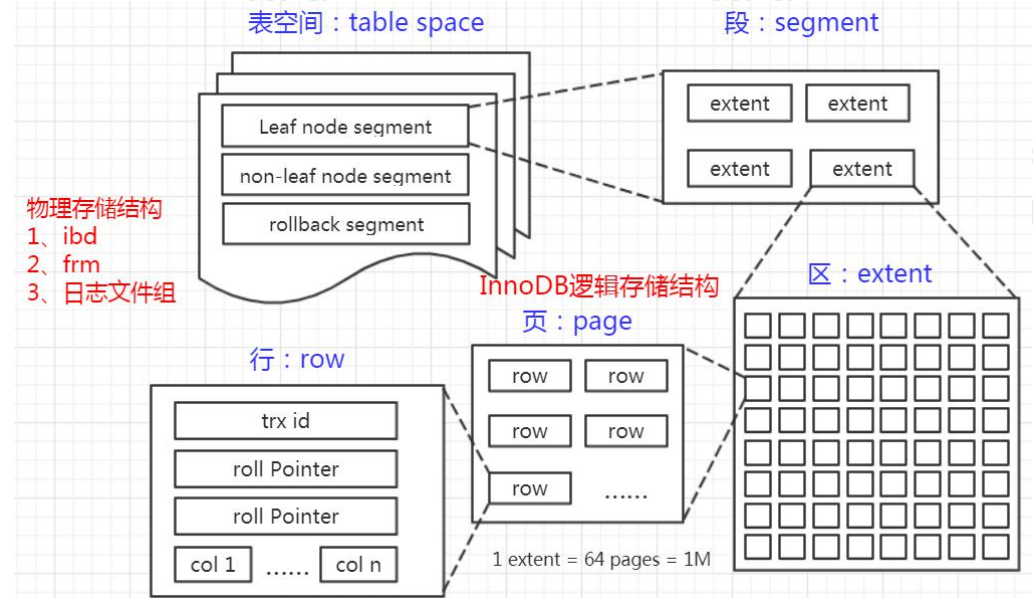 表空间 Table Space 上表空间可以看做是 InnoDB 存储引擎逻辑结构的 最高层,所有的数据都存放在表空间中。分为:系统表空间、独占表空间、通用表空间、 临时表空间、Undo 表空间。
表空间 Table Space 上表空间可以看做是 InnoDB 存储引擎逻辑结构的 最高层,所有的数据都存放在表空间中。分为:系统表空间、独占表空间、通用表空间、 临时表空间、Undo 表空间。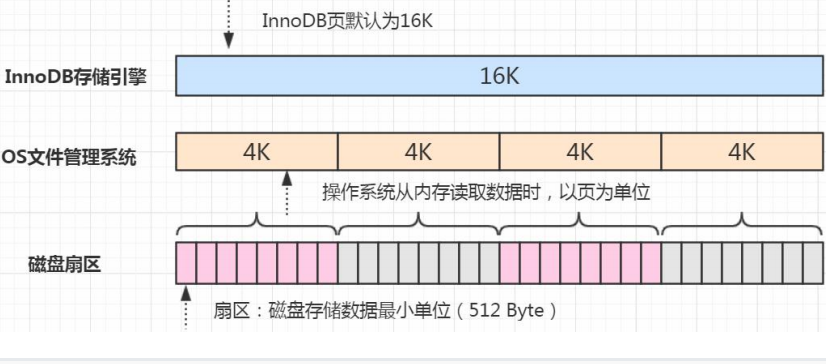
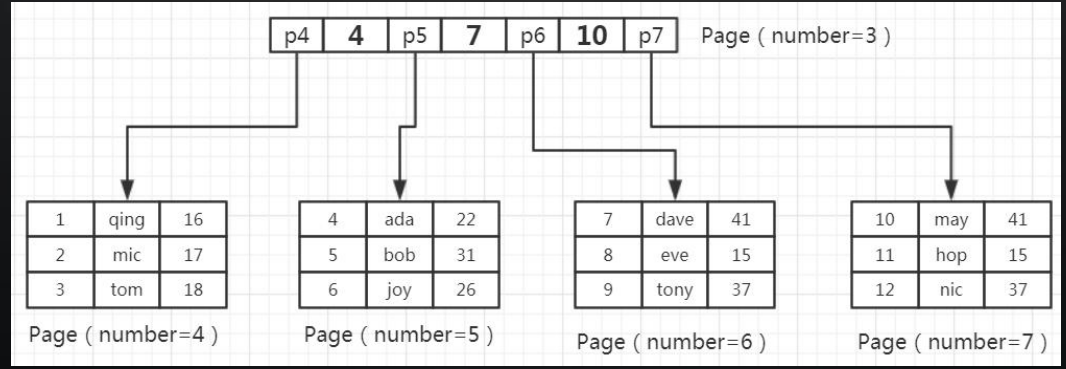 往表中插入数据时,如果一个页面已经写完,产生一个新的叶页面。如果一个簇的 所有的页面都被用完,会从当前页面所在段新分配一个簇。 如果数据不是连续的,往已经写满的页中插入数据,会导致叶页面分裂:
往表中插入数据时,如果一个页面已经写完,产生一个新的叶页面。如果一个簇的 所有的页面都被用完,会从当前页面所在段新分配一个簇。 如果数据不是连续的,往已经写满的页中插入数据,会导致叶页面分裂:  行 Row InnoDB 存储引擎是面向行的(row-oriented),也就是说数据的存放按行进行存 放 https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html
行 Row InnoDB 存储引擎是面向行的(row-oriented),也就是说数据的存放按行进行存 放 https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html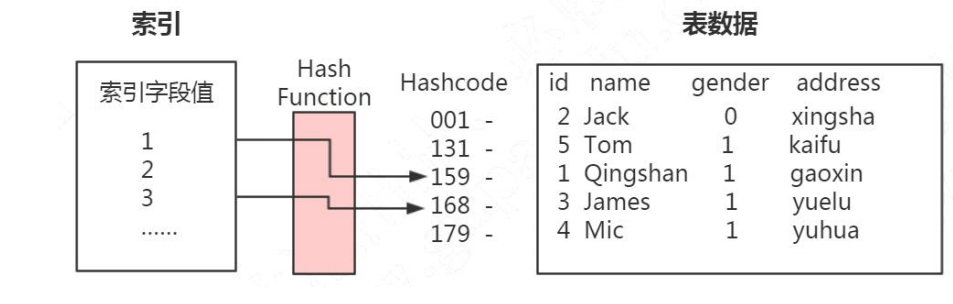 第一个,它的时间复杂度是 O(1),查询速度比较快。因为哈希索引里面的数据不是 按顺序存储的,所以不能用于排序。 第二个,我们在查询数据的时候要根据键值计算哈希码,所以它只能支持等值查询 (= IN),不支持范围查询(> < >=
第一个,它的时间复杂度是 O(1),查询速度比较快。因为哈希索引里面的数据不是 按顺序存储的,所以不能用于排序。 第二个,我们在查询数据的时候要根据键值计算哈希码,所以它只能支持等值查询 (= IN),不支持范围查询(> < >= 【本文地址】