| PNG、JPG如何转Dicom(dcm),那些年我踩过的坑(Python版) | 您所在的位置:网站首页 › 如何把png图片改成pg › PNG、JPG如何转Dicom(dcm),那些年我踩过的坑(Python版) |
PNG、JPG如何转Dicom(dcm),那些年我踩过的坑(Python版)
|
Dicom作为医学影像的常见数据格式,是每个深耕于医疗AI的同学无法跳过的一个坑。虽然我只是一名扎根于算法部署方面的小白。但是也不可避免地接触到这类数据。这不,最近接到算法同学给出的算法,需要我自己找公开数据集进行测试。可是Dicom数据集并不常见(PS:测了1000张还嫌不够,大无语),因此只能将目光聚焦于PNG、JPG类型的数据集(直接用PNG、JPG训练的除外)。 但是PNG、JPG类型的数据转Dicom并不容易,一不小心你就会收获“非标准Dicom”,网上的一些教程我也尝试了,很遗憾:转出来的Dicom不是黑不溜秋,就是无法识别。要么就是c++写的,编译来编译去,令人心烦。也尝试过用现成的Dicom数据,然后使用PNG、JPG的Data替换其中的Pixel Data。但是都无功而返! 于是乎,我潜心钻研(东Copy西Copy),完成了这份python版本的PNG、JPG转Dicom。 目录 1.Dicom数据格式简介 2.PNG、JPG转Dicom(以PNG为例) 3.进一步完善Dicom 4.结果展示 1.Dicom数据格式简介首先,在你尝试着将PNG、JPG类型的数据转换成Dicom数据之前,你可能需要浅浅了解一下Dicom数据的基本格式。
(1)preamble(前导):不重要,主要是为了向后兼容性和可扩展性而保留的若干个字节。 (2)prefix(前缀):不重要,主要是确认该文件是否符合DICOM标准。前导和前缀是可选的,对于DICOM文件来说,并不是必需的。 (3)File Meta Information(文件元信息头):重要!!!文件元信息头是DICOM文件的必要部分,其中包含了一些关键信息,如DICOM版本号、文件字节顺序、数据元素编码方式等。 (4)DataElements(数据元素):重要!!!是DICOM文件中包含的实际医学图像和相关信息的部分。 2.PNG、JPG转Dicom(以PNG为例)OK,知道了Dicom的数据结构,我们就能够针对主要的部分来转换我们的PNG、JPG。废话不多说,上代码!如果你不想看接下来的分析,你只需要修改main函数中的路径即可。 import os import pydicom from PIL import Image def png_to_dicom(input_png_path, output_dcm_path, patient_name="Anonymous", study_description="PNG to DICOM"): for fileNames in os.listdir(input_png_path): input_filename = os.path.basename(fileNames).split('.')[0] output_filename = input_filename + ".dcm" input_filepath = input_png_path + fileNames output_dcmpath = output_dcm_path + output_filename # 读取PNG图像 img = Image.open(input_filepath) # 将PNG图像转换为灰度图像(单通道) pixel_array = img.convert("L") # 创建一个空的FileDataset对象,并添加DICOM数据集元素 ds = pydicom.dataset.FileDataset(output_dcm_path, {}, file_meta=pydicom.dataset.Dataset()) # 创建文件元信息头对象 # 添加DICOM文件元信息头 ds.file_meta.FileMetaInformationGroupLength = 184 ds.file_meta.FileMetaInformationVersion = b'\x00\x01' ds.file_meta.MediaStorageSOPClassUID = '1.2.840.10008.5.1.4.1.1.1.1' ds.file_meta.MediaStorageSOPInstanceUID = '1.2.410.200048.2858.20230531153328.1.1.1' ds.file_meta.TransferSyntaxUID = '1.2.840.10008.1.2' ds.file_meta.ImplementationClassUID = '1.2.276.0.7230010.3.0.3.5.4' ds.file_meta.ImplementationVersionName = 'ANNET_DCMBK_100' # 添加DICOM数据集元素 ds.PatientName = patient_name ds.StudyDescription = study_description ds.Columns, ds.Rows = img.size ds.SamplesPerPixel = 1 ds.BitsAllocated = 8 ds.BitsStored = 8 ds.HighBit = 7 ds.PixelRepresentation = 0 # 数据显示格式 ds.PhotometricInterpretation = "MONOCHROME2" ds.PixelData = pixel_array.tobytes() # 直接使用灰度图像的字节数据 # 保存DICOM数据集到文件 ds.is_little_endian = True ds.is_implicit_VR = True # 使用隐式VR ds.save_as(output_dcmpath) print(output_dcmpath) if __name__ == "__main__": # 输入PNG图像路径和输出DICOM图像路径 input_png_path = "Your_Input_PNG_Path" output_dcm_path = "Your_Output_Dicom_Path" # 将PNG转换为DICOM png_to_dicom(input_png_path, output_dcm_path)让我们来详细分析一下这部分代码: (1)FileMetaInformationGroupLength:指定File Meta Information部分的长度,随意啦,别太离谱就行。 (2)FileMetaInformationVersion:表示File Meta Information部分的版本号。 (3)MediaStorageSOPClassUID:定义了影像的数据类型,每种类型有唯一的UID标识。如“1.2.840.10008.5.1.4.1.1.1.1”代表的是“Digital X-Ray Image Storage - For Presentation” (4)MediaStorageSOPClassUID:唯一标识一个特定的影像数据实例。 (5)TransferSyntaxUID:表示DICOM图像数据的传输语法,它指定了数据在网络传输中的编码方式。每种方式有唯一的UID标识,比如“1.2.840.10008.1.2”代表的是“Implicit VR Little Endian”。 (6)ImplementationClassUID :用于标识实现DICOM标准的应用程序或设备的唯一标识符。 (7)ImplementationVersionName: 实现DICOM标准的应用程序或设备的版本名称或标识。 看到这里你可能会问“你这乱七八糟的一堆数字,我怎么知道什么意思?” 聪明的我早就想到了,首先随便选一张标准的Dicom数据,然后执行如下代码: import pydicom dataset = pydicom.dcmread("Your_Dicom_Path", force=True) print(dataset.file_meta)然后你会看到下面一堆信息,如果你想更换MediaStorageSOPClassUID和TransferSyntaxUID,那你就要自己去查对应的UID喽,所以以下内容我不建议你自己换,除非你知道你要干嘛:
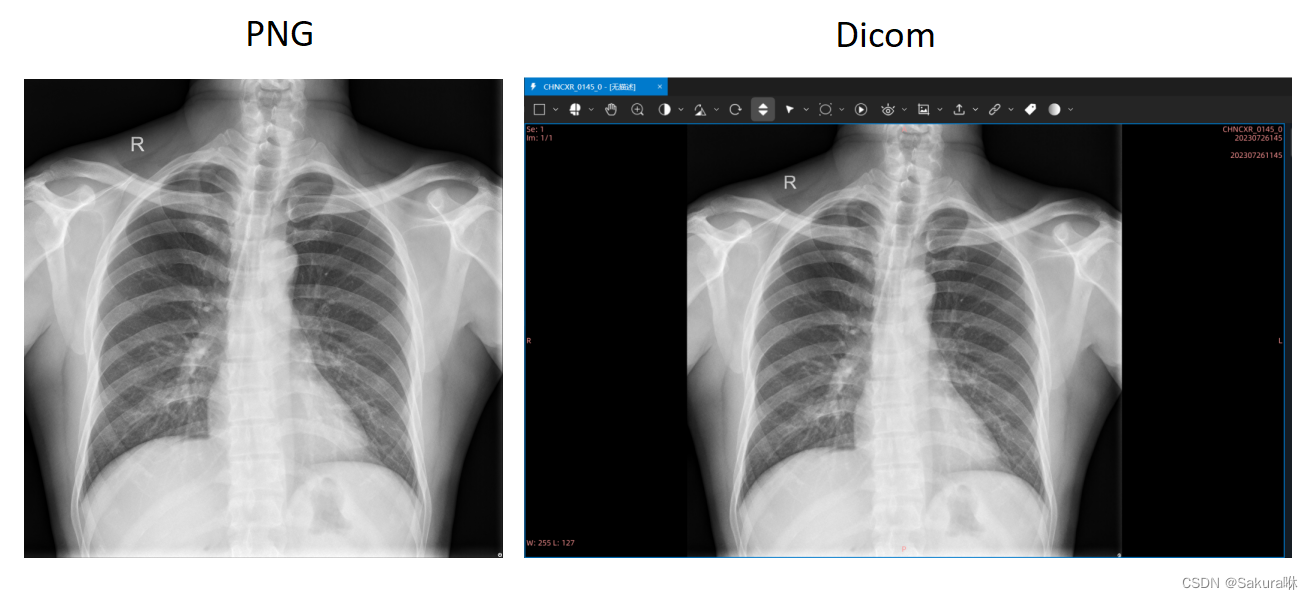
哈哈哈哈,没想到还有吧!实际上,通过第2步,你已经可以获得一张用于展示的Dicom数据格式了。但是仅此而已,如果你想要做算法或者跟我一样,去验证别人的算法。那么,这一步是必不可少的。 在第2步中,我们为新的Dicom添加了File Meta Information(文件元信息头)和部分DataElements(主要是Pixel Data)。因此这份Dicom是可以正常被读取、浏览的。但是,如果是用于算法训练或者验证算法,是需要确保这份Dicom数据的唯一性的。 为了便于理解,确保Dicom数据唯一性的代码,我另起了一个新的py文件: import os import pydicom # 源文件夹和目标文件夹路径 source_folder = 'Your_Input_Dicom_Path' target_folder = 'Your_Output_Dicom_Path' patient_pid = 20230726001 accession_number = 202307261001 study_uid = 2023072620001 seriesNumber = 1 seriesInstanceUID = "1.2.410.200048.2858.20230529094313.1" modality = "CR" pixelSpacing = [0.160145, 0.160114] instanceNumber = 1 bodyPartExamined = "CHEST" # 遍历源文件夹中的文件 for filename in os.listdir(source_folder): if filename.endswith('.dcm'): # 构建源文件路径和目标文件路径 source_file = os.path.join(source_folder, filename) target_file = os.path.join(target_folder, filename) # 加载源DCM文件 dcm_data = pydicom.dcmread(source_file, force=True) # 添加患者PID、Accession Number和Study UID等信息 dcm_data.PatientID = str(patient_pid) dcm_data.AccessionNumber = str(accession_number) dcm_data.StudyInstanceUID = str(study_uid) dcm_data.SeriesNumber = seriesNumber dcm_data.SeriesInstanceUID = seriesInstanceUID dcm_data.Modality = modality dcm_data.PixelSpacing = pixelSpacing dcm_data.BodyPartExamined = bodyPartExamined dcm_data.InstanceNumber = instanceNumber # 将文件名作为患者名 file_name_without_extension = os.path.splitext(filename)[0] dcm_data.PatientName = file_name_without_extension # 保存修改后的DCM文件到目标文件夹 dcm_data.save_as(target_file) # 递增计数器 patient_pid += 1 accession_number += 1 study_uid += 1 else: print("error!")同样的,我们来详细解析以下这部分代码 。 (1)patient_pid:患者的唯一标识符,你怎么开心怎么写。 (2)accession_numbe:分配给患者检查的唯一标识号码,唯一地标识特定的检查或一组医学影像,你怎么开心怎么写。 (3)study_uid:对应医学影像研究的ID,你怎么开心怎么写。 (4)seriesNumber:标识图像所属系列的编号,建议按照我这个来。 (5)seriesInstanceUID:唯一标识一个影像系列,建议按照我这个来,或者你找一张标准的Dicom,参考它怎么写。 (6)modality:用于获取图像的影像学模态,建议按照我这个来,或者你找一张标准的Dicom,参考它怎么写。 (7)pixelSpacing:像素在行和列方向上的物理间距,建议按照我这个来,或者你找一张标准的Dicom,参考它怎么写。 (8)instanceNumber:分配给图像中个别实例的唯一编号,通常用于区分一个系列中的不同图像,你怎么开心怎么写。 (9)bodyPartExamined:检查部位,根据实际写,你也可以不写。 4.结果展示需要说的是,PNG、JPG亦或是其它类型的数据,在转成Dicom的过程中不可避免地会出现一定的损失。如果在Dicom数据充足的情况下,无论是算法训练还是验证,都建议使用Dicom(直接用PNG训练的除外)。PNG、JPG转Dicom实属无奈之举啊!
|


【本文地址】