| 案例分享:使用 Python 批量处理统计年鉴数据(下) | 您所在的位置:网站首页 › 如何下载统计年鉴中的表格文件 › 案例分享:使用 Python 批量处理统计年鉴数据(下) |
案例分享:使用 Python 批量处理统计年鉴数据(下)
|
引言
上期文章我们向大家分享了一个使用 Python 批量处理统计年鉴表的案例,文章中我们以一个实际案例为背景向大家展示了使用 Python 处理(知网提供的)统计年鉴表的流程,并提供了一套处理思路。整个流程中,处理与清洗表格内容是最难实现的一步,这是因为统计年鉴表的内容形式非常多样,有的年鉴表中存放了多个续表,这些续表的分布没有绝对的规律,有的则存放了多个 Sheet 表。上期文章的案例中,我们在已知全部年鉴表的表结构的情况下对案例中的年鉴表做了针对性处理,也就是说,案例中的代码只能处理案例中的年鉴表。如果处理其他统计年鉴表,还要重新编写代码,这样就太麻烦了。 那有没有这样一种可能,无论当一份年鉴中是否包含续表,包含多少个续表,无论表头多么散乱,我们都可以用同一份代码将这些表格提取、清洗出来,并且根据表格内容合并为一张大表?当然可以!下面我们就将代码和处理思路分享给大家。 一、处理思路 (1)提取所有子表处理年鉴表较为关键的一步就是从包含续表的年鉴表中提取出所有的子表。以笔者处理过几千份统计年鉴表的经验来看,含有续表的年鉴表都有一个特点,即续表的左上方都含有关键词“续表”,如下图所示。 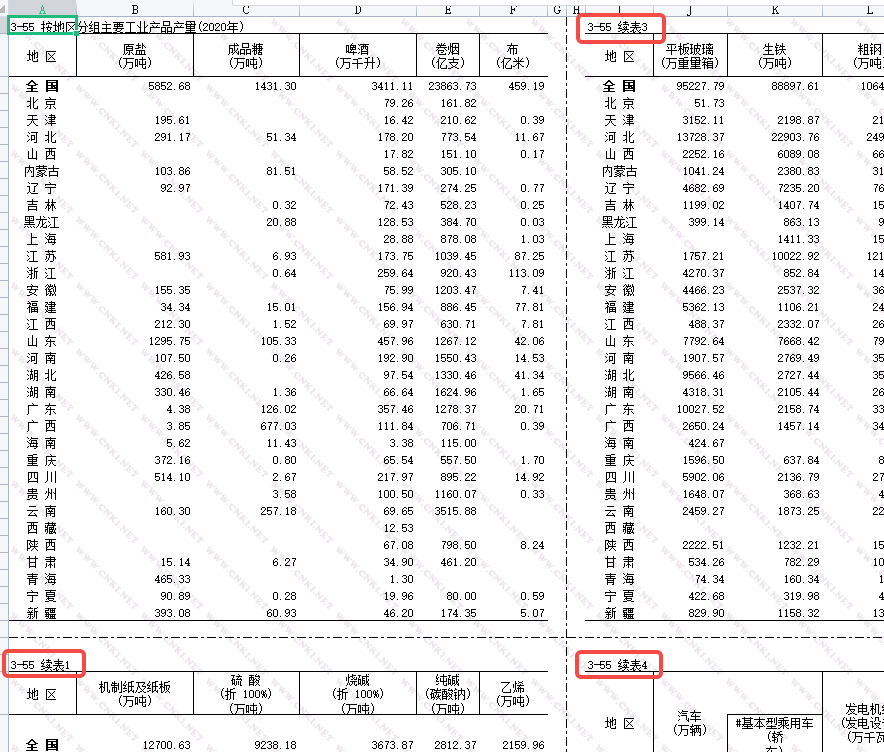

这个特点就是我们使用 Python 提取所有子表的的突破口,我们可以根据这些关键词出现的位置将每一个子表都找出来。提取子表之前我们还要判断待处理的年鉴表是否含有多个 Sheet 表,如果有,则要对每个 Sheet 表都要做提取子表操作。当然,如果一个年鉴表或者年鉴表中的某个 Sheet 表只有一个表格,不含有续表,那只读取这张表即可,最后再将一份年鉴表中的所有子表提取出来并存放在一个列表中。 (2)清洗所有子表提取出所有子表后,需要对每一个子表做清洗,主要是删除不需要的行、列;对表格的表头(字段名)做处理。由于年鉴表中表头处常常使用合并单元格,导致使用 Python 等工具读取表格后表头极其不规范,如下图所示。 
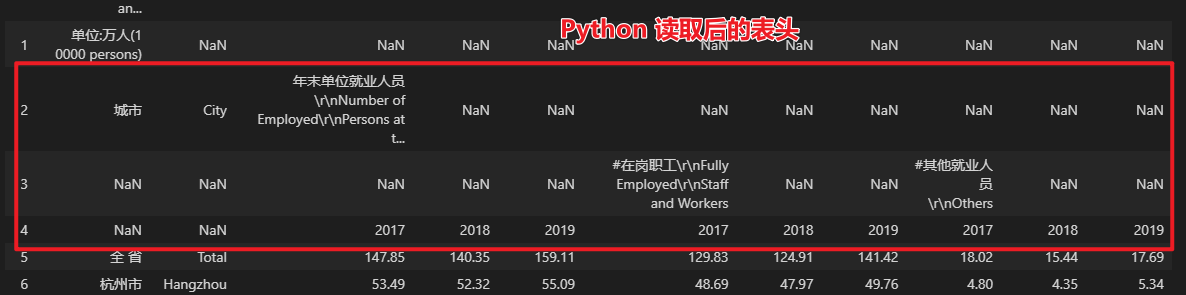
这一步需要将散乱的字段名规范化,去除字段名中的换行符等空字符,不过为了不影响字段名中的英文语句,处理字段名时还得保留英文单词之间的空格。 同时,一些年鉴表的下方还含有一些注释信息,这些注释同样也需要删除,如下图所示。  (3)分情况合并所有子表
(3)分情况合并所有子表
清洗所有子表后,已经搞清楚字段名,接下来需要根据字段名判断这些子表是需要纵向拼接为一张表,还是需要横向匹配为一张表,又或者不需要拼接匹配。最后根据子表的情况做合并处理并返回合并结果。如果没有要合并的表,那么返回清洗后的所有子表即可(这种情况下处理的结果是包含所有已清洗子表的列表)。 二、代码温馨提示:代码太宽看不全?微信公众号内代码框可以左右滑动哦~ (1)定义提取所有子表的函数 # 导入使用到的库 import re import pandas as pd import numpy as np # 下面是用于提取所有子表的函数 def Find_XuBiao_index(df): '''找到年鉴中所有包含关键词【“续表”】的单元格的位置''' XB_index = [] # 输入的表的表头 df = df.fillna('') for row_ind, Row in df.iterrows(): row_xb_ind = [] # row_ind 是行索引, Row 第 row_ind 行的内容 for col_ind, Val in zip(Row.index, Row.values): if bool(re.search('续\s*?表', Val)): row_xb_ind.append((row_ind, col_ind)) if row_xb_ind: # 如果在某一行中找到“续表”,那么将续表出现的位置列表收集起来 XB_index.append(row_xb_ind) if not XB_index or (len(XB_index)==1 and XB_index[0][0] in [(0,0), (1,0), (2,0)]): # 如果整表都没有出现“续表”,或者“续表”仅出现一次,且是在前三行首列出现的, # 那么说明该年鉴只有一个表, 那么处理结果等于输入的表 return df if XB_index[0][0] in [(0,0), (1,0), (2,0)]: # 第一张表也有出现“续表”,直接返回即可 ALL_XB_IND = pd.DataFrame(XB_index) return [ALL_XB_IND] df_ind = pd.DataFrame(XB_index) if df_ind.shape[1] > 1: # 横向、纵向都有续表 R1 = XB_index[0] R1.insert(0, (0,0)) XB_index[0] = R1 else: if XB_index[0][0][1] > 1: # 横向有续表 R1 = XB_index[0] R1.insert(0, (0,0)) XB_index[0] = R1 else: # 纵向有续表 XB_index.insert(0, [(0,0)]) ALL_XB_IND = pd.DataFrame(XB_index) return [ALL_XB_IND] # 放在列表中,在返回值的类型与上一步区别开来 def Split_table(DF, indf): ''' 根据“续表”出现的位置,提取出所有子表,存放在一个列表中返回 DF : Python 读取后的原始年鉴表 indf: 续表出现的位置,从自定义函数 Find_XuBiao_index 中得到 ''' Datas_list = [] # 处理纵向单层续表 if indf.shape[1] == 1: for row_ind, INDS in zip(indf[0].index, indf[0].values): if indf.shape[0]-1 > row_ind: # 当前续表下方还有续表 Datas_list.append(DF.loc[INDS[0]:indf[0].values[row_ind+1][0]-1, :]) else: # 当前续表下方就是表底 Datas_list.append(DF.loc[INDS[0]:, :]) return Datas_list # 处理横向单层续表 elif indf.shape[0] == 1: first_row = indf.T[0] for col_ind, INDS in zip(first_row.index, first_row.values): if indf.shape[1]-1 > col_ind: # 当前续表右侧还有续表 Datas_list.append(DF.loc[:, INDS[1]:first_row[col_ind+1][1]-1]) else: # 当前续表右侧就是表底 Datas_list.append(DF.loc[:, INDS[1]:]) return Datas_list # 处理横向、纵向都有续表的情况 else: # 一行一行处理 for row_ind, row in indf.iterrows(): if indf.shape[0]-1 > row_ind: # 当前续表下方还有续表 for col_ind, INDS in zip(row.index, row.values): if indf.shape[1]-1 > col_ind: # 当前续表右侧还有续表 downINDS = indf[col_ind][row_ind+1] rightINDS = indf[col_ind+1][row_ind] Datas_list.append(DF.loc[INDS[0]:downINDS[0]-1, INDS[1]:rightINDS[1]-1]) else: # 当前续表右侧就是表底 downINDS = indf[col_ind][row_ind+1] if downINDS: # 当前续表正下方还有续表 Datas_list.append(DF.loc[INDS[0]:downINDS[0]-1, INDS[1]:]) else: # 当前续表左下方还有续表,但正下方没有续表 leftdown = indf[col_ind-1][row_ind+1] Datas_list.append(DF.loc[INDS[0]:leftdown[0]-1, INDS[1]:]) else: # 当前续表下方就是表底 for col_ind, INDS in zip(row.index, row.values): if indf.shape[1]-1 > col_ind: # 当前续表右侧可能还有续表 rightINDS = indf[col_ind+1][row_ind] if rightINDS: # 最后一行有多个续表 Datas_list.append(DF.loc[INDS[0]:, INDS[1]:rightINDS[1]-1]) else: # 最后一行仅有一个续表 Datas_list.append(DF.loc[INDS[0]:, INDS[1]:]) else: # 当前续表右侧就是表底 if INDS: # 当前存在续表 Datas_list.append(DF.loc[INDS[0]:, INDS[1]:]) else: # 当前已经没有续表 pass return Datas_list # 返回的结果是一个列表 (2)定义清洗所有子表的函数 def Clean_single_table(table): ''' 对拆分后的子表做清洗 table : 提取后,待清洗的单个子表 ''' # 先重置索引 table = table.reset_index(drop=True) table.columns = list(range(table.shape[1])) # 去除所有单元格中的空格和换行符 table = table.applymap(lambda x: re.sub('\n|\t|\r', ' ', x)) # 去除非英文字母前/后面的空格换行符,这样可以保留英文字母之间的空格 table = table.applymap(lambda x: re.sub('\s+', ' ', x)) # 多个空格变成一个空格,为了下一步服务 table = table.applymap(lambda x: re.sub('(? |
【本文地址】