| python对json格式原文件追加内容 | 您所在的位置:网站首页 › 好就业的热门专业 › python对json格式原文件追加内容 |
python对json格式原文件追加内容
|
python对json格式原文件追加内容
之前有个需求: 要求爬取的数据是json格式的;json格式在 网络数据传输中使用很广泛; 类似于python的字典格式;其本质是字符串 但是呢,如果稍微不注意我们会发现我们保存的格式 不是特别正确会出现如下格式: {"a": {"password": "123", "status": false, "timeout": 1555380013.9477446}} {"b": {"password": "123", "status": false, "timeout": 1555380013.9477446}} {"c": {"password": "123", "status": false, "timeout": 1555380013.9477446}} {"d": {"password": "123", "status": false, "timeout": 1555380013.9477446}}这样的话 使用json格式去加载文件的话就会报错 从网上找了很多例子 但是没有成功; 今天自己偶然的机会,又看了下python操作文件基础;这个方法或许可以解决: 直接上代码:(方便以后要读取该json文件的人,减少代码量) import json with open('test2.json','a+',encoding="utf-8") as f: f.seek(0) # 因为是追加方式打开,默认偏移量再最后面,我们调整到开头 if f.read() =='': # 判断是否为空,如果为空的话创建一个新的字典格式 print('执行了吗') data = {} else: f.seek(0) data = json.load(f) print(data) data['a']="我爸是赵四" data['b']="我爸是李刚" # 可以在第二遍运行时修改一下看看效果 data['e']="我爸是李刚" data['f'] = {'a':'嵌套啊'} print(data) f.seek(0)# 设置文件当前位置 0代表开始处 其实有两个参数 offset,whence (whence常用有三个参数0,1,2;0 代表从文件开头开始算起,1 代表从当前位置开始算起,2 代表从文件末尾算起。) # 如果操作成功,则返回新的文件位置,如果操作失败,则函数返回 -1。 f.truncate() # 从开头截断,截断文件为size个字符,无参代表 从当前位置截断,截断之后后面的所有字符都被删除 json.dump(data,f,indent=2,ensure_ascii=False)第一次运行: |
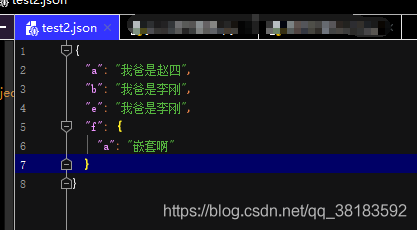 修改后第二次运行:添加内容
修改后第二次运行:添加内容 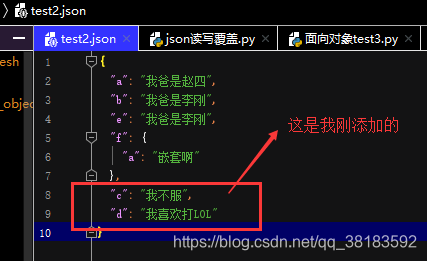
【本文地址】
公司简介
联系我们