| 从0到1实践MLPerf | 您所在的位置:网站首页 › 天翼云盘搭建教程下载 › 从0到1实践MLPerf |
从0到1实践MLPerf
|
1 前言
当前,AI的应用场景日益复杂化、多样化。一方面,厂商纷纷给出不同的衡量标准,印证其产品在计算性能、单位能耗算力等方面处于行业领先水平。而与此同时,用户关心如何能判断出AI算力是否能实际满足其真实场景的需求。2018年5月,全球AI基准测试组织MLperf推出了MLperf基准测试,是业内首套衡量机器学习软硬件性能的通用基准。MLPerf由图灵奖得主大卫•帕特森联合谷歌、斯坦福、哈佛大学等顶尖学术机构发起成立,是权威性最大、影响力最广的国际AI性能基准测试。每年定期发布基准测试数据,结果被国际社会广泛认可。 2 两种测试基准MLPerf分为训练和推理: MLPerf 训练测试的评价标准:用特定数据集训练一个模型达到指定精度所花费的时间。由于机器学习任务的训练时间差异很大,所以,MLPerf 的最终训练结果是指定次数的基准测试时间的平均值,去掉最高和最低的数字,通常是运行5次取平均值,训练测试时间包括了模型构建,数据预处理,训练和质量测试等时间。 MLPerf 推理测试的评价标准:用特定数据集测量模型的推理性能,包括时延和吞吐量。 3 Benchmark设计 3.1 选取有代表性,使用场景多的模型每个基准由一个数据集和质量目标定义。下表总结了v2.1这个版本的套件中的基准。
 3.3.1 SingleStream
3.3.1 SingleStream
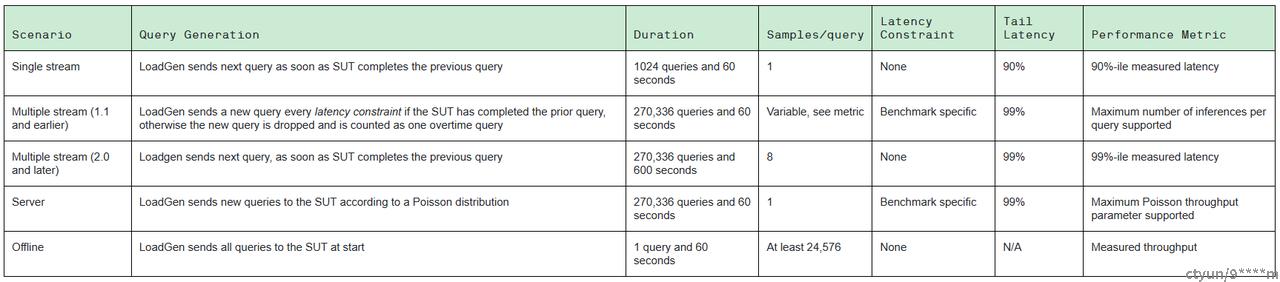
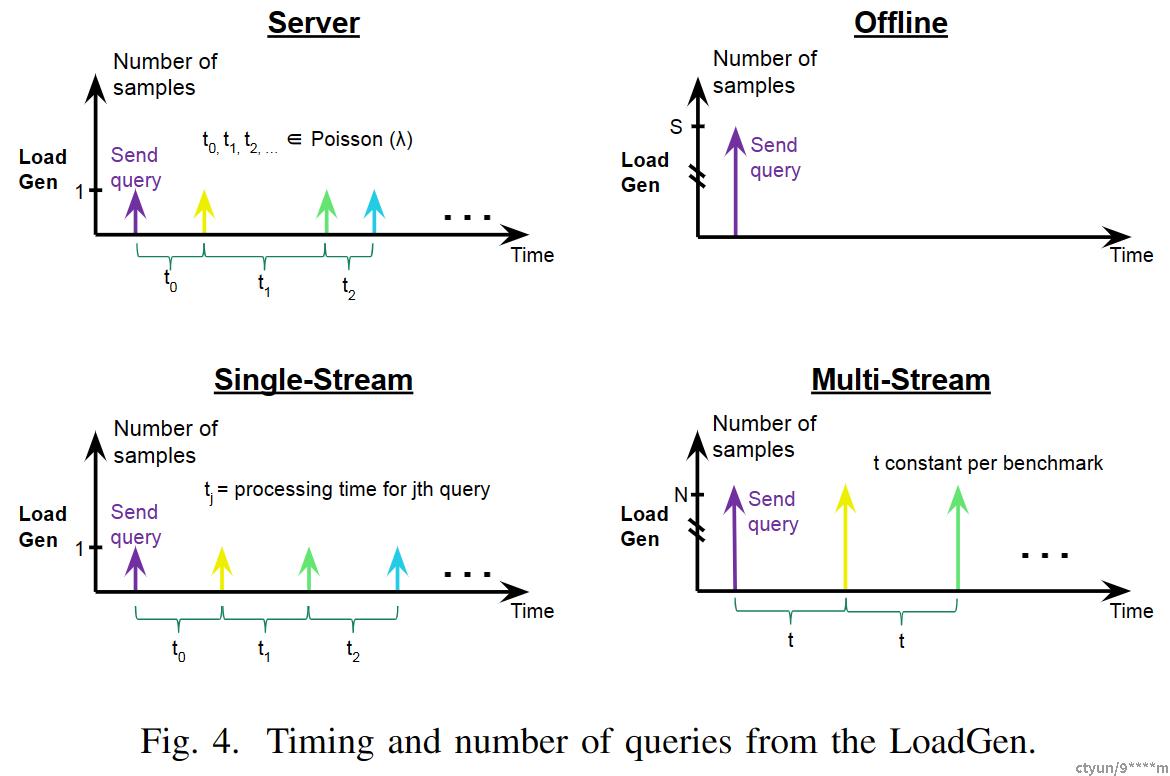
在测试中LoadGen发送初始查询,一次查询送入系统一个样本(可以理解为batchsize=1),到上个请求的响应之前不会发送下一个请求,single stream度量标准是第90百分位延迟(90%的延迟),衡量的结果是Tail Latency。 3.3.2 MultiStream 以固定的时间间隔发送请求,一个请求中含有N个样本,当所有查询的(latency)延时都在延迟边界中时,这时每个请求中包含的样本数N就是系统的性能指标。 3.3.3 Server为了模拟现实生活中的随机事件,请求将以泊松分布送入被测试系统中。每个请求只有一个样本,系统的性能指标是在延迟边界(latency bound)内每秒查询次数(QPS)。 3.3.4 Offline 一次请求将所有的测试样本送入到被测试系统中,被测试系统可以一次或多次以任何顺序返回测试结果,Offline场景的性能评判标准是每秒推理的样本数。 4 整体使用流程
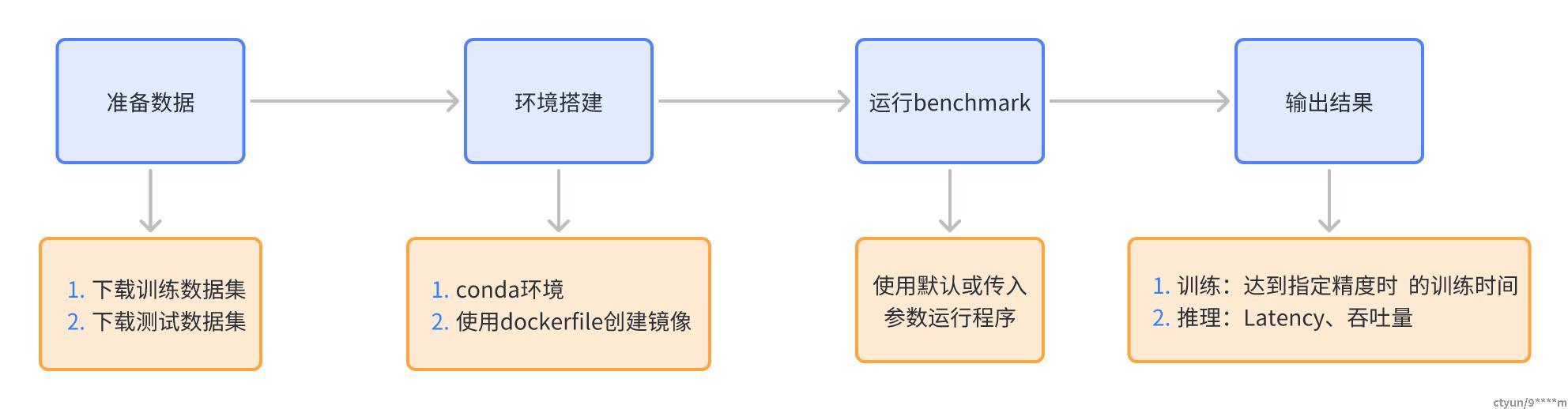
以目标检测模型mask-rcnn为例 (1)准备数据,下载COCO2017 source download_dataset.sh(2)环境搭建 # dockerfile创建镜像 cd training/object_detection/ nvidia-docker build . -t mlperf/object_detection #启动镜像 sudo nvidia-docker run --name train-od -v /home/:/workspace -t -i --rm --ipc=host mlperf/object_detection cd mlperf/training/object_detection python setup.py clean build develop --user(3)运行benckmark 单机单卡直接运行即可,单机多卡修改 run_and_time.sh, --nproc_per_node=GPU数量 ./run_and_time.sh(4)输出结果 输出训练总时间、GPU的吞吐量 6 MLPerf推理以分类模型resnet50为例 (1)准备数据,下载小型数据集替代ImageNet,网上拉取下载图像并制作标签 ./tools/make_fake_imagenet.sh(2)环境搭建 dockerfile创建镜像,运行benckmark ./run_and_time.sh backend model device backend is one of [tf|onnxruntime|pytorch|tflite|tvm-onnx|tvm-pytorch] model is one of [resnet50|retinanet|mobilenet|ssd-mobilenet|ssd-resnet34] device is one of [cpu|gpu] For example: ./run_and_time.sh onnxruntime resnet50 gpu(3)输出结果 # SingleStream ./run_local.sh onnxruntime resnet50 gpu # MultiStream ./run_local.sh onnxruntime resnet50 gpu --scenario MultiStream # Offline ./run_local.sh onnxruntime resnet50 gpu --scenario Offline # tune for example Server mode ./run_local.sh onnxruntime resnet50 gpu --count 100 --time 60 --scenario Server --qps 200 --max-latency 0.1
|

【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |