| python爬取天气后报网 | 您所在的位置:网站首页 › 天气后报查询 › python爬取天气后报网 |
python爬取天气后报网
|
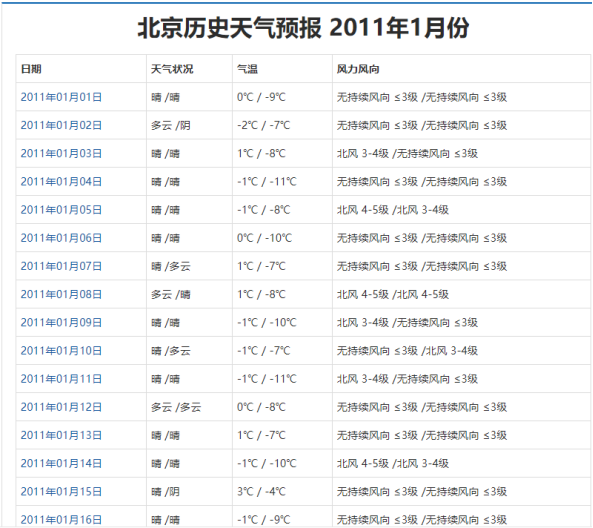
前言 大二下学期的大数据技术导论课上由于需要获取数据进行分析,我决定学习python爬虫来获取数据。由于对于数据需求量相对较大,我最终选择爬取 天气后报网,该网站可以查询到全国各地多年的数据,而且相对容易爬取。 需求分析: (1)需要得到全国各大城市的历史天气数据集。 (2)每条天气信息应该包含的内容包括城市名、日期、温度、天气、风向。 (3)以城市名分类,按日期存储在可读的文件中。 (4)存储信息类型应该为字符型。 整体解决方案: 第一步:选择适合进行信息爬虫的网页。 第二步:对该网页相关信息所在的url进行获取。 第三步:通过解析url对应的网页获取信息并存储。
详细解决方案: 第一步:选择适合进行信息爬虫的网页。 (1)由于要获取的是历史天气信息,我们不考虑常见的天气预报网页,最后选择了“天气后报网”作为目标网站。如下图,该网站天气信息按条分布,符合我们的爬虫需求。
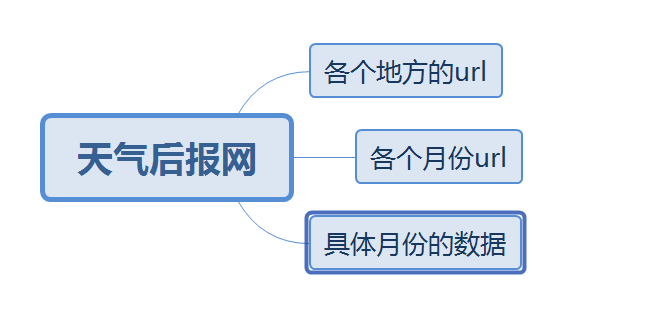
(2)我们查看了该网站的robots协议,通过输入相关网址,我们没有找到robots.txt的相关文件,说明该网站允许任何形式的网页爬虫。 (3)我们查看了该类网页的源代码,如下图所示,发现其标签较为清晰,不存在信息存储混乱情况,便于爬取。 第二步:对该网页相关信息所在的url进行获取。 (1)对网页的目录要清晰的解析 为了爬取到全年各地各个月份每一天的所有天气信息,我们小组首先先对网页的层次进行解析,发现网站大体可以分为三层,第一层是地名的链接,通向各个地名的月份链接页面,第二层是月份链接,对应各个网页具体天数,第三个层次则是具体每一天的天气信息,与是我们本着分而治之的原则,对应不同网页的不同层次依次解析对应的网页以获取我们想要的信息。
天气后报网的第一层层次-地名链接
天气后报网第二层次-时间链接
天气后报第三层次具体时间的信息
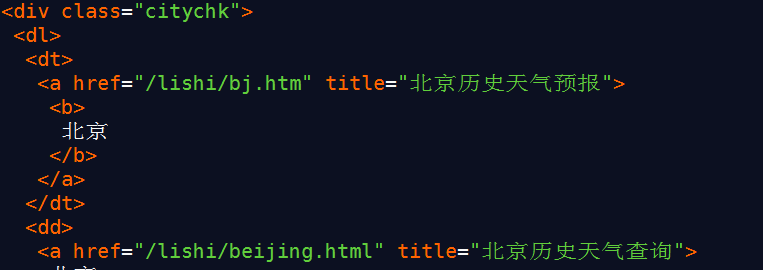
(1)解析地名网页层次结构-获取地名链接 第一个层次的网页代码 进过观察第一个层次的网页代码,我们发现我们要提取的地名链接在class=”citychk”的div标签的子孙节点标签的href的属性中,于是我们调用beutifulsoup库的findall()方法将a标签以及它的内容放到一个集合中,依次遍历将对应的链接写道web_link.txt文件中。 解析地名链接的核心代码 成功爬取的第一部分地名的链接 (2)解析地名网页层次结构-获取月份链接
进过我们观察发现,我们想要的月份链接存储在class=”box_pcity”的div标签下的li内的a标签的href属性内,于是我们采用同样的方法,依次遍历提取我们想要的月份链接,并按照不同的地名,保存在对应地名的文件中。
第三步:通过解析url对应的网页获取信息并存储。 (1)设置请求登录网页功能,根据不同的url按址访问网页,若请求不成功,抛出HTTPError异常。 (2)设置获取数据功能,按照网页源代码中的标签,设置遍历规则,获取每条数据。注意设置“encoding=‘gb18030’”,改变标准输出的默认编码, 防止控制台打印乱码。 (3)设置文件存储功能,将爬取的数据按年份和月份分类,分别存储在不同的CSV文件中。注意文件名的设置为城市名加日期,方便后期整理。
4. 程序流程图 5. 运行测试截图 (1)url获取
(2)解析网页
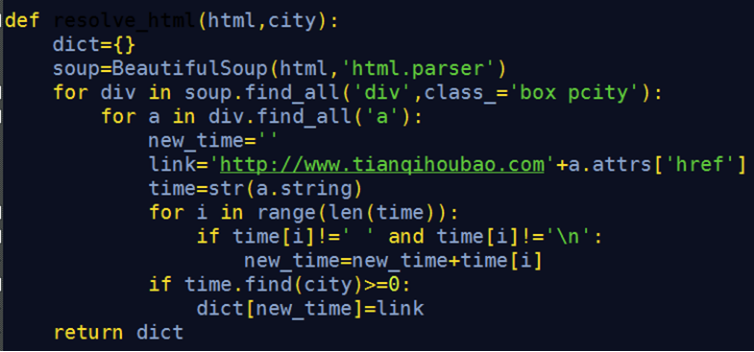
附录代码: 爬虫部分代码-------------------------------------------------------get_all_city_info.py文件是为了获取每个地方按照月份的链接的代码get_city_weather_link.py是为了获取地名连接的代码get_city_weather_content.py是为了获取具体信息的代码 get_all_city_info.py import urllib.request import urllib.parse from bs4 import BeautifulSoup import os def get_city_link():#将读取到的文件转化为字典 web_link={} f=open('web_link.txt') line=f.readline() while line: split_line=line.split(',') key=split_line[0] value=split_line[1] value=value.replace('\n','') web_link[key]=value line=f.readline() f.close() return web_link def get_place_name(web_link):#得到所有的地名 place=[] for key in web_link: place.append(key) return place def get_html(url):#依次访问这些网站得到这些网站的html代码 header = { 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)' } # 伪装浏览器 request = urllib.request.Request(url, headers=header) response = urllib.request.urlopen(request) html = response.read() soup=BeautifulSoup(html,'html.parser') pretty_html=soup.prettify() return pretty_html def resolve_html(html,city): dict={} soup=BeautifulSoup(html,'html.parser') for div in soup.find_all('div',class_='box pcity'): for a in div.find_all('a'): new_time='' link='http://www.tianqihoubao.com'+a.attrs['href'] time=str(a.string) for i in range(len(time)): if time[i]!=' ' and time[i]!='\n': new_time=new_time+time[i] if time.find(city)>=0: dict[new_time]=link return dict def trans_dict_to_file(dict,city,file_path):#将爬取到的网址依次存放到文件中 file_path=file_path+city+'.txt' for key in dict: with open(file_path,'a') as f: f.write(key+','+dict[key]+'\n') def main(): path='D:\\face\weatherspider\\time_link\\' web_link=get_city_link() citys=get_place_name(web_link) count=0 for city in citys: try: count=count+1 print("正在抓取第%d个页面..."%(count)) html=get_html(web_link[city])#获取该城市的页面 print("抓取第%d个页面成功!"%(count)) keyword=city+'天气' print('正在解析%d个网页...'%(count)) dict=resolve_html(html,keyword) trans_dict_to_file(dict,city,path) print('解析第%d个网页成功!'%(count)) except: continue main()get_city_weather_content.py # coding=utf-8 import io import sys import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd import csv import time import urllib sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') # 改变标准输出的默认编码, 防止控制台打印乱码 def get_soup(year, month): url = 'http://www.tianqihoubao.com/lishi/' + 'changzhou/' + 'month' + '/' + str(year) + str(month) + '.html' try: r = requests.get(url, timeout=30) r.raise_for_status() # 若请求不成功,抛出HTTPError 异常 # r.encoding = 'gbk' soup = BeautifulSoup(r.text, 'lxml') return soup except HTTPError: return "Request Error" def saveTocsv(data, fileName): ''' 将天气数据保存至csv文件 ''' result_weather = pd.DataFrame(data, columns=['date', 'tq', 'temp', 'wind']) result_weather.to_csv(fileName, index=False, encoding='gbk') print('Save all weather success!') def get_data(): soup = get_soup(year, month) all_weather = soup.find('div', class_="wdetail").find('table').find_all("tr") data = list() for tr in all_weather[1:]: td_li = tr.find_all("td") for td in td_li: s = td.get_text() data.append("".join(s.split())) res = np.array(data).reshape(-1, 4) return res if __name__ == '__main__': years = ['2011','2012','2013','2014','2015','2016','2017','2018','2019'] months = ['01','02','03','04','05','06','07','08','09','10','11','12'] for year in years: for month in months: data = get_data() saveTocsv(data, '常州'+str(year)+str(month)+'.csv')get_city_weather_link.py import urllib.request import urllib.parse from bs4 import BeautifulSoup def get_html(url): header = { 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)' } # 伪装浏览器 request = urllib.request.Request(url, headers=header) response = urllib.request.urlopen(request) html = response.read() return html def main(): url = 'http://www.tianqihoubao.com/lishi/index.htm' html = get_html(url) pretty_html=parse_home_page(html) get_city_link(pretty_html) def parse_home_page(html): #将网页熬成一锅汤 soup=BeautifulSoup(html,'html.parser') pretty_html=soup.prettify() return pretty_html def get_city_link(html): website={} url='http://www.tianqihoubao.com' soup=BeautifulSoup(html,'html.parser') div_city=soup.find_all('div',class_='citychk') city_html=str(div_city[0]) city_soup=BeautifulSoup(city_html,'html.parser') for k in city_soup.find_all('a'): index=return_index(k['title']) place=k['title'][0:index] website[place]=url+k['href'] for key in website:#将各地天气链接存到文件中 with open('web_link.txt','a') as f: f.write(key+','+website[key]+'\n') def return_index(s): for i in range(len(s)): if s[i]=='历': break return i main() |










【本文地址】