| 《Attention Is All You Need》注意力机制公式中Q,K,V的理解 | 您所在的位置:网站首页 › 大v含义是什么 › 《Attention Is All You Need》注意力机制公式中Q,K,V的理解 |
《Attention Is All You Need》注意力机制公式中Q,K,V的理解
|
一、概述
《Attention Is All You Need》是一篇关于注意力机制里程碑的文章,从2017年发表至今2020年7月已经获得了上万的引用。该文的两大亮点一是提出了一个几乎仅依靠注意力来完成机器翻译的模型Transformer,推动了NLP的发展,另外一个亮点是改进了点积注意力(Dot-Product Attention),加入了一个缩放因子,提出了可伸缩点积注意力(Scaled Dot-Product Attention)。本人在阅读了《Attention Is All You Need》和《Illustrate the Trasformer》两篇文章后,发现文中对点积注意力的解释都不够具体,让很多读者难以理解。Q(一组query集合组成的矩阵),K(一组key集合组成的矩阵),V(一组value集合组成的矩阵)具体含义是什么,如何去理解。本人在经过思考以后,有一些自己的想法和见解在此提出,希望能对有相同困惑的同学一些帮助,如果有理解不对的地方,也希望大家在评论区提出指正共同探讨。 二、向量相关性为了对点积注意力机制有一个比较好的理解,首先需要理解如何度量两个向量之间的相关性。由线性代数相关的知识我们可以知道,对于相同维度的两个向量,可以通过点积的方法来获得其相关性。 在论文中作者提到的注意力公式如下图: 自注意力机制即自己注意自己,在论文给出的机器翻译例子中,即是寻找一句话中各个单词之间的关系。我这里先说结论:在自注意力机制中,Q=K 实际上,在自注意力机制中,q与k,Q与K都是对应的同一个单词或者同一个句子,因此有qi=ki,Q=K, Q与KT相乘的结果,经过缩放因子与softmax函数之后,对应的就是各个词之间的相互关联程度,最后再与自身V相乘,就是送入下一层的加权后的结果。 2、编解码注意力机制(Encoder-Decoder Attention)中的Q,K,V在Transformer的解码器中有一个层为Encoder-Decoder Attention,其用到的注意力机制也是Dot-product Attention。不过,这里的Q,K,V的内容和self-attention不同。在解码器中,我们希望找到的是从一种语言到另一种语言对应的翻译关系,所以,在Encoder-Decoder Attention中,K是需要被翻译的语言经过Encoders之后的词向量表示。Q是目标语言的所有单词的特征向量对应的矩阵(假设目标语言有5000个单词参加训练,那么矩阵Q就有5000行),此时Q与KT作点乘运算,可以计算出每个源单词翻译到目标单词对应的权重。最后再经过softmax和与目标单词的V矩阵作加权求和,经过一个分类器就能翻译出每一个源单词对应的目标单词。由于计算过程与self-attention一致,只是Q和K所代表的含义不同,这里不再赘述。 参考文献https://arxiv.org/abs/1706.03762 https://jalammar.github.io/illustrated-transformer/ |
 上图中的两个向量,点积就是对应位置相乘再相加,所得结果为0,可以说这两个向量是线性无关的,也就是垂直的。如果点积不为0,则是相关的,如下图点积结果为3。
上图中的两个向量,点积就是对应位置相乘再相加,所得结果为0,可以说这两个向量是线性无关的,也就是垂直的。如果点积不为0,则是相关的,如下图点积结果为3。 
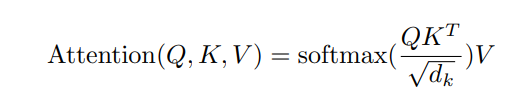 作者并未明确说明Q,K,V的具体含义。在论文中提到了self-attention和Encoder-Decoder Attention两种注意力层,笔者认为在这两种注意力机制中,Q,K,V代表的内容各不相同。
作者并未明确说明Q,K,V的具体含义。在论文中提到了self-attention和Encoder-Decoder Attention两种注意力层,笔者认为在这两种注意力机制中,Q,K,V代表的内容各不相同。 在上图中,就是寻找it_这个单词与本句话中其他单词的联系。上图中我们把左边的内容记作k1,k2…k14(每一个都是词向量),右边的内容记作q1,q2…q14。这些向量是对应单词的词向量表示(可以理解为该向量就是这个单词的特征),所以,根据我们上面提到的向量之间的相关性度量方法,我们可以用q10(即右边的it_)与左边的k1(The_)作点积,得出单词The_与it_的相关性。即The_与it_的相关性为q10·k1。
在上图中,就是寻找it_这个单词与本句话中其他单词的联系。上图中我们把左边的内容记作k1,k2…k14(每一个都是词向量),右边的内容记作q1,q2…q14。这些向量是对应单词的词向量表示(可以理解为该向量就是这个单词的特征),所以,根据我们上面提到的向量之间的相关性度量方法,我们可以用q10(即右边的it_)与左边的k1(The_)作点积,得出单词The_与it_的相关性。即The_与it_的相关性为q10·k1。  为了度量animal_与it_的关系,可以使用q10与k2作点积,以此类推……
为了度量animal_与it_的关系,可以使用q10与k2作点积,以此类推……  为了得出it_与整句话中所有词之间的相关性,q10要和k1到k14分别做点积,这一过程可以通过矩阵进行表示。我们把k1到k14按照行排列进行组合成为一个矩阵K,则K就是整个句子中各个单词的特征向量的拼接
为了得出it_与整句话中所有词之间的相关性,q10要和k1到k14分别做点积,这一过程可以通过矩阵进行表示。我们把k1到k14按照行排列进行组合成为一个矩阵K,则K就是整个句子中各个单词的特征向量的拼接  所以,为了寻找it_(q10)与整句话(K)之间的联系,需要将q10与KT做点积,所得结果如下为一个向量,记录的是it_与整句话各个单词之间的相关性:
所以,为了寻找it_(q10)与整句话(K)之间的联系,需要将q10与KT做点积,所得结果如下为一个向量,记录的是it_与整句话各个单词之间的相关性:  上面只找了q10(It_)一个单词和整句话的关系,我们需要找出这句话中所有单词分别和整句话的关系,于是,我们把q1,q2…q14也组成一个大的矩阵Q,用于表示整句话。Q与KT相乘,得出的下图中灰色的矩阵,即是一句话中的每个单词两两之间的相互关系。
上面只找了q10(It_)一个单词和整句话的关系,我们需要找出这句话中所有单词分别和整句话的关系,于是,我们把q1,q2…q14也组成一个大的矩阵Q,用于表示整句话。Q与KT相乘,得出的下图中灰色的矩阵,即是一句话中的每个单词两两之间的相互关系。 
【本文地址】