| 机器学习中解决不平衡分类的10种技术 | 您所在的位置:网站首页 › 多分类问题用什么算法比较好 › 机器学习中解决不平衡分类的10种技术 |
机器学习中解决不平衡分类的10种技术
|
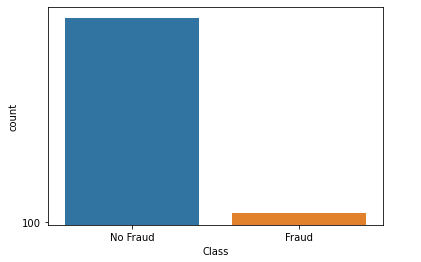
参考: 10 Techniques to Solve Imbalanced Classes in Machine Learning (Updated 2023)SMOTE for Imbalanced Classification with Python关键词: Classification Intermediate Machine Learning Python Structured Data Technique 引言(Introduction)作为一名数据科学家,二分类是最常见的分类模型之一。在解决这些问题时,一个常见的问题是类不平衡(class imbalance)。当一个类别的观察结果高于其他类别时,就会存在类别失衡。示例:检测欺诈性信用卡交易。如下图所示,欺诈性交易约为400笔,而非欺诈性交易为约90000笔。
类不平衡是机器学习中的一个常见问题,尤其是在分类问题中。不平衡的数据会严重影响我们的模型准确性。它出现在许多领域,包括欺诈检测、垃圾邮件过滤、疾病筛查、软件即服务(SaaS)订阅流失、广告点击等。让我们了解如何处理机器学习中的不平衡数据。 学习目标: 通过本文中包含代码的教程来熟悉类不平衡。了解处理不平衡数据的各种技术,如随机欠采样、随机过采样和NearMiss。目录: 文章目录 引言(Introduction)1. 机器学习中的类不平衡问题2. 信用卡欺诈检测示例2.1 样本数据集2.2 Python代码 3. 度量陷阱(The Metric Trap)4. 通过重采样来解决类不平衡问题4.1 方法1: 随机下采样4.2 方法2:随机过采样 5. 如何使用Imbalanced-Learn模块来平衡数据?5.1 方法3:使用Imblearn的随机下采样5.2 方法4:使用Imblearn的随机过采样5.3 方法5: Under-Sampling: Tomek Links5.4 方法6:Synthetic Minority Oversampling Technique (SMOTE)5.5 方法7:NearMiss5.6 方法8:Change the Performance Metric5.7 方法9:Penalize Algorithms (Cost-Sensitive Training)5.8 方法10: Change the Algorithm 6. 下采样的优点和缺点7. 过采样的优点和缺点8. 结论9. Frequently Asked Questions 1. 机器学习中的类不平衡问题当每个类中的样本数量大致相等时,大多数机器学习算法的效果最好。这是因为大多数算法都是为了最大限度地提高精度和减少误差而设计的。 然而,如果数据框具有不平衡的类,那么在这种情况下,仅通过预测多数类(majority class)就可以获得相当高的精度,但无法捕获少数类(minority),这通常是首先创建模型的关键。例如,如果类别分布显示99%的数据具有多数类别,那么任何基本分类模型(如逻辑回归或决策树)都将无法识别次要类别数据点。 2. 信用卡欺诈检测示例假设我们有一个信用卡公司的数据集(https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud),基于这个数据集我们想要查明信用卡交易是否存在欺诈行为, 从而保证消费者不会为他们没有购买的东西付费。 该数据集包含2013年9月欧洲信用卡持卡人通过信用卡进行的交易。 该数据集显示了两天内发生的交易,在284807笔交易中,我们有492笔欺诈。数据集高度不平衡,正类(欺诈)占所有交易的0.172%。【本博客中,作者选用了部分数据, 其中欺诈交易占6%。】 它只包含数值输入变量,这些变量是主成分分析变换的结果。不幸的是,由于保密问题,我们无法提供有关数据的原始功能和更多背景信息。特征V1、V2、…V28是用PCA获得的主要成分,唯一没有用PCA转换的特征是“时间”和“数量”。特征“Time”包含每个事务与数据集中第一个事务之间的秒数。特征“Amount”是交易金额,此功能可用于例如依赖成本敏感的学习。特征“Class”是响应变量,如果发生欺诈,它的值为1,否则为0。 考虑到类别不平衡率,我们建议使用精度召回曲线下面积(AUPRC)来测量精度。混淆矩阵的准确性对不平衡分类没有意义。
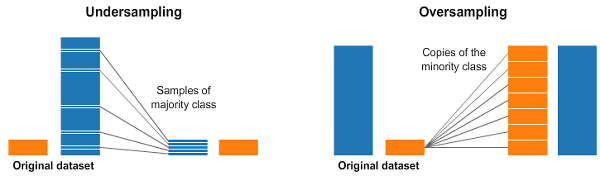
但问题是…欺诈交易相对罕见。只有6%的交易是欺诈性的。 现在,在你开始之前,你看到问题可能会如何解决吗?想象一下,如果你根本不去训练一个模特。相反,如果你只写了一行代码,总是预测“没有欺诈交易”,会怎么样: def transaction(transaction_data): return 'No fradulent transaction'你猜怎么着?您的“解决方案”将有94%的准确率! 不幸的是,这种准确性具有误导性: 对于所有这些**非欺诈性(non-fraudulent)**交易,您将拥有100%的准确性。对于那些**欺诈性(fraudulent)**交易,您的准确率为0%。你的整体准确性会很高(accuracy would be high),只是因为大多数交易都没有欺诈行为(而不是因为你的模型很好)。这显然是一个问题,因为许多机器学习算法都是为了最大限度地提高整体精度而设计的。在本文中,我们将看到处理不平衡数据的不同技术。 2.1 样本数据集我们将在本文中使用信用卡欺诈检测数据集。你可以在这里找到数据集。 加载数据后,显示数据集的前五行。 2.2 Python代码您可以清楚地看到,数据集之间存在着巨大的差异。9000笔非欺诈性交易和492笔欺诈性交易。 3. 度量陷阱(The Metric Trap)新开发人员用户在处理不平衡数据集时遇到的主要问题之一与用于评估其机器学习模型的评估指标有关。使用更简单的指标,如准确度得分(accuracy score),可能会产生误导。在具有高度不平衡类的数据集中,分类器总是“预测”最常见的类,而不执行任何特征分析,并且它的准确率很高,显然不是正确的。 让我们使用简单的XGBClassifier进行这个实验,而不使用特征工程: # import linrary from xgboost import XGBClassifier xgb_model = XGBClassifier().fit(x_train, y_train) # predict xgb_y_predict = xgb_model.predict(x_test) # accuracy score xgb_score = accuracy_score(xgb_y_predict, y_test) print('Accuracy score is:', xbg_score)输出为: Accuracy score is: 0.992我们可以看到99%的准确性,我们得到了非常高的准确性,因为它主要预测的是0(非欺诈)的大多数类别。 4. 通过重采样来解决类不平衡问题用于处理高度不平衡数据集的一种广泛采用的类不平衡技术称为重采样。它包括从多数类中删除样本(欠采样)和/或从少数类中添加更多样本(过采样)。
尽管平衡类别有好处,但这些技巧也有缺点(没有免费午餐定理)。 **过采样(over-sampling)**的最简单实现是复制少数类别的随机记录,这可能会导致过度捕捞(overfishing)。 在**欠采样(under-sampling)**中,最简单的技术包括从多数类中删除随机记录,这可能会导致信息丢失。 让我们以信用卡欺诈检测为例来实现这一点。 我们将从分离将为0和1的类开始。 # class count class_count_0, class_count_1 = data['Class'].value_counts() # Separate class class_0 = data[data['Class'] == 0] class_1 = data[data['Class'] == 1]# print the shape of the class print('class 0:', class_0.shape) print('class 1:', class_1.shape
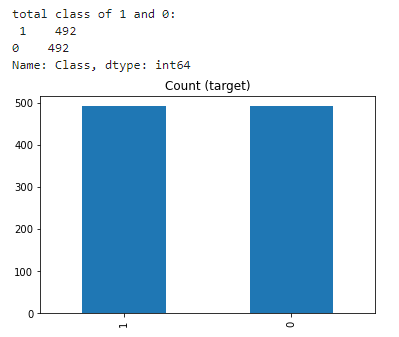
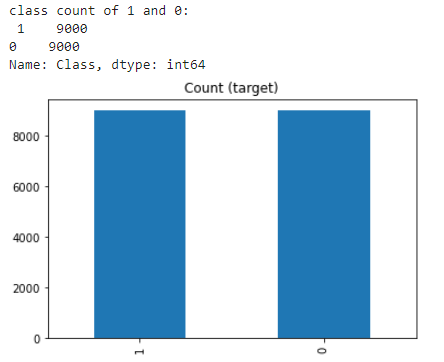
欠采样(Undersampling)可以定义为删除多数类的一些观测值(removing some observations of the majority class)。这样做直到多数类和少数类得到平衡。 当您有大量数据时,欠采样可能是一个不错的选择——想想数百万行。但欠采样的一个缺点是,我们正在删除可能有价值的信息。 class_0_under = class_0.sample(class_count_1) test_under = pd.concat([class_0_under, class_1], axis=0) print("total class of 1 and0:",test_under['Class'].value_counts()) # plot the count after under-sampeling test_under['Class'].value_counts().plot(kind='bar', title='count (target)')
**过采样(Oversampling)**可以定义为向少数类添加更多副本。当您没有大量数据可供处理时,过采样可能是一个不错的选择。 过采样时需要考虑的一个缺点是,它会导致过度拟合和测试集的泛化能力差。 class_1_over = class_1.sample(class_count_0, replace=True) test_over = pd.concat([class_1_over, class_0], axis=0) print("total class of 1 and 0:",test_under['Class'].value_counts()) # plot the count after under-sampeling test_over['Class'].value_counts().plot(kind='bar', title='count (target)')
科学文献中提出了许多更复杂的重新采样技术。 例如,我们可以对大多数类的记录进行聚类,并通过从每个聚类中删除记录来进行欠采样,从而寻求保留信息。在过度采样中,我们可以在这些副本中引入小的变化,从而创建更多样的合成样本,而不是创建少数类记录的精确副本。 让我们使用Python库imbalanced-learn来应用其中一些重采样技术。它与scikit-learn兼容,是scikit-learn-contrib项目的一部分。 import imblearn 5.1 方法3:使用Imblearn的随机下采样在学习数据科学时,您可能听说过pandas、numpy、matplotlib等。但还有另一个库:imblearn,它用于对不平衡的数据集进行采样,并提高模型性能。 RandomUnderSampler是一种快速而简单的方法,可以通过随机选择目标类的数据子集来平衡数据。通过随机抽取带有或不带有替换的样本,对大多数类别进行欠采样。 # import library from imblearn.under_sampling import RandomUnderSampler rus = RandomUnderSampler(random_state=42, replacement=True) # fit predictor and target variable x_rus, y_rus = rus.fit_resample(x, y) print('original dataset shape:', Counter(y)) print('Resample dataset shape', Counter(y_rus))
对抗不平衡数据的一种方法是在少数类中生成新的样本(generate new samples)。最幼稚的策略是通过随机采样生成新的样本,并替换当前可用的样本。RandomOverSampler提供了这样一个方案。 # import library from imblearn.over_sampling import RandomOverSampler ros = RandomOverSampler(random_state=42) # fit predictor and target variablex_ros, y_ros = ros.fit_resample(x, y) print('Original dataset shape', Counter(y)) print('Resample dataset shape', Counter(y_ros))
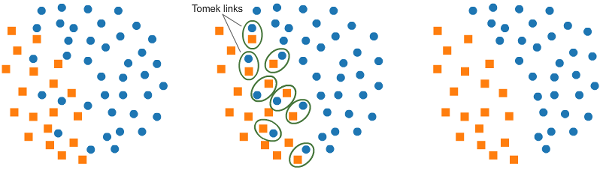
Tomek links是一对非常接近的实例,但属于相反的类。删除每对中大多数类的实例会增加两个类之间的空间,从而促进分类过程。 如果两个样本是彼此最近的邻居,则存在Tomek’s link。
在下面的代码中,我们使用ratio='majority'来重采样大多数类。 # import library from imblearn.under_sampling import TomekLinks tl = RandomOverSampler(sampling_strategy='majority') # fit predictor and target variable x_tl, y_tl = ros.fit_resample(x, y) print('Original dataset shape', Counter(y)) print('Resample dataset shape', Counter(y_ros))
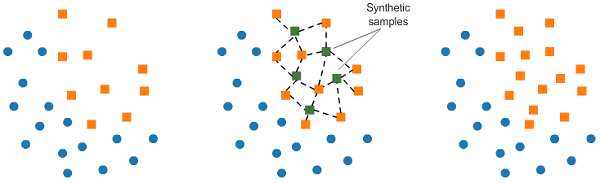
这项技术为少数类别生成合成数据。 SMOTE(合成少数过采样技术)通过从少数类中随机选择一个点并计算该点的k个最近邻居来工作。**合成点(synthetic points)**被添加到所选择的点及其相邻点之间。
SMOTE算法分为4个简单步骤: 选择一个少数类作为输入向量。查找其k个最近的邻居(在SMOTE()函数中将k_neighbors指定为参数)。选择这些邻居中的一个,并将合成点放置在连接所考虑的点及其所选邻居的线上的任何位置。重复这些步骤,直到数据达到平衡。 # import library from imblearn.over_sampling import SMOTE smote = SMOTE() # fit predictor and target variable x_smote, y_smote = smote.fit_resample(x, y) print('Original dataset shape', Counter(y)) print('Resample dataset shape', Counter(y_ros))
NearMiss是一种欠采样技术。使用距离将使多数类与少数类相等,而不是对少数类进行重新采样。 from imblearn.under_sampling import NearMiss nm = NearMiss() x_nm, y_nm = nm.fit_resample(x, y) print('Original dataset shape:', Counter(y)) print('Resample dataset shape:', Counter(y_nm))
在评估不平衡的数据集时,**准确性(Accuracy)**不是最好的衡量标准,因为它可能会产生误导。 可以提供更好见解的指标有: 混淆矩阵(Confusion Matrix):一个显示正确预测和错误预测类型的表格。精度(Precision):真阳性数除以所有阳性预测数。精度也称为正预测值。它是分类器精确性的一种衡量标准。精度低表示误报率高。召回率(Recall):真阳性的数量除以测试数据中阳性值的数量。召回也称为敏感性或真阳性率。它是分类器完整性的度量。低召回率表示大量假阴性。F1:得分:准确率和召回率的加权平均值。ROC曲线下面积(AUROC):AUROC表示您的模型区分两类观测结果的可能性。换句话说,如果你从每一类中随机选择一个观察结果,那么你的模型能够正确地对它们进行“排序”的概率是多少? 5.7 方法9:Penalize Algorithms (Cost-Sensitive Training)下一个策略是使用惩罚学习算法,增加少数类分类错误的成本。 该技术的一个流行算法是惩罚支持向量机(Penalized-SVM)。 在训练过程中,我们可以使用参数class_weight='balanced'来惩罚少数类的错误,惩罚量与它的代表性不足程度成比例。 如果我们想启用SVM算法的概率估计,我们还想包括自变量probability=True。 让我们在原始不平衡数据集上使用Penalized-SVM训练模型: # load library from sklearn.svm import SVC # we can add class_weight='balanced' to add panalize mistake svc_model = SVC(class_weight='balanced', probability=True) svc_model.fit(x_train, y_train) svc_predict = svc_model.predict(x_test)# check performance print('ROCAUC score:',roc_auc_score(y_test, svc_predict)) print('Accuracy score:',accuracy_score(y_test, svc_predict)) print('F1 score:',f1_score(y_test, svc_predict))
虽然在每一个机器学习问题中,尝试各种算法都是一个很好的经验法则,但对于不平衡的数据集来说,这尤其有益。 决策树通常在不平衡的数据上表现良好。在现代机器学习中,树集成(随机森林、梯度增强树等)几乎总是优于单个决策树,所以我们将直接进入这些:基于树的算法通过学习if/else问题的层次结构来工作。这可能会强制处理这两个类。 # load library from sklearn.ensemble import RandomForestClassifier rfc = RandomForestClassifier() # fit the predictor and target rfc.fit(x_train, y_train) # predict rfc_predict = rfc.predict(x_test)# check performance print('ROCAUC score:',roc_auc_score(y_test, rfc_predict)) print('Accuracy score:',accuracy_score(y_test, rfc_predict)) print('F1 score:',f1_score(y_test, rfc_predict))
优点: 当训练数据集很大时,它可以通过减少训练数据样本的数量来帮助改善运行时间和存储问题。缺点: 它可能会丢弃可能对构建规则分类器很重要的潜在有用信息。通过随机欠采样选择的样本可以是偏置样本。而且这并不能准确地代表整体情况。从而导致实际测试数据集的结果不准确。 7. 过采样的优点和缺点优点: 与欠采样(under-sampling)不同,过采样不会导致信息丢失。性能优于下采样。缺点: 由于它复制了少数类事件,因此增加了过拟合的可能性。 8. 结论总之,在本文中,我们看到了处理数据集中类不平衡的各种技术。在处理不平衡的数据时,实际上有很多方法可以尝试。您可以在我的GitHub存储库(https://github.com/benai9916/Handle-imbalanced-data)中查看这些代码的实现情况。 关键收获 在本文中,我们了解了可以用来处理类不平衡的不同技术。一些最广泛使用的技术是SMOTE、imblearn oversampling, and undersampling.没有处理不平衡的“最佳”方法,这取决于您的用例。 9. Frequently Asked QuestionsQ1.如何在Python中对不平衡的数据进行采样? 答:有多种方法可以对不平衡数据进行采样,您可以将过采样方法应用于多数类,也可以将欠采样方法用于解决不平衡分类问题。 Q2.数据中类别的比例是多少?你如何才能发现你的数据是否平衡? 答:数据集中类的比例是一个类与其他类的比例。应用采样技术的阈值根据您的问题陈述而有所不同,但通常情况下,如果一个类占数据集的比例小于10%,则该类被视为少数。 Q3.如何对不平衡数据进行分类? 答:我们在本文中讨论的所有方法都可以用于不平衡数据集的分类问题。这就是为什么对数据科学家来说,了解像imblearn库这样的采样库是有利的。 |








【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |