|
文章目录
0 前言1 什么是推荐系统2 毕业设计 - 能做哪些推荐系统?2.1 电商推荐系统2.3 电影推荐系统2.4 音乐推荐系统2.5 就业推荐系统2.6 图书推荐系统2.7 小说推荐系统
3 推荐系统的评价指标3.1 预测准确度3.2 马太效应3.3 信任度3.4 实时性3.5 健壮性
4 如何架构一个推荐系统4.1 数据
5 推荐系统架构6 搜索引擎上的推荐系统7 代码实现7.1 基于用户的协同过滤算法7.2 基于物品的协同过滤算法
8 最后
0 前言
Hi,大家好,这里是丹成学长,今天想同学们介绍如何构建一个推荐系统作为毕设,推荐系统的原理,推荐能做哪些题目
1 什么是推荐系统
场景:假如现在你要买一包花生米,你可以选择去便利店,找到货架,转一圈,比较花生米的几个牌子或价格,掏钱付款;当然了,你也可以去附近的大超市(沃尔玛),走进店里,按照分类指示牌走到食品楼层,再找到卖干果的货架,在货架上寻找你要的花生米,挑喜欢的牌子比较价格,掏钱付款;更懒点的方法是,打开手机淘宝,搜索框输入花生米,找到喜欢的牌子与价格,加入购物车,付款,等待送货上门。

在当今信息化的世界,信息过载的问题越来越明显,人每天头脑接受的信息越来越多,到最后只能筛选出自己所感兴趣的,对自己有用的信息。早先点的代表性的解决方案有分类目录和搜素引擎,雅虎和谷歌是这两个解决方案的代表。但是随着互联网规模的不断扩大,分类目录网站也只能覆盖少量的热门网站,并不能很好的满足用户的需求,so,搜索引擎诞生了,用户可以根据搜索引擎通过搜索关键字来找到自己所需要的信息。但,搜索引擎也不是万能的,当用户不能准确描述自己需求的关键词是,搜索引擎也无能为力。
相比现阶段,推荐系统是一种帮助用户快速发现有用信息的工具。推荐系统不需要用户提供明确的需求,而是通过分析用户的历史行为给用户的兴趣简历模型。从而主动给用户推荐能够满足他们兴趣和需求的信息。
2 毕业设计 - 能做哪些推荐系统?
个性化推荐系统需要依赖用户的行为数据,主要作用是通过分析大量用户行为日志,给不同用户提供不同的个性化页面展示,来提高网站的点击率喝转化率。
下面是学长做过的一些推荐系统,列举给大家
2.1 电商推荐系统
推荐结果的标题、缩略图及其它内容属性,推荐结果的平均分,推荐理由
相关推荐(用户经常购买的闪屏,浏览过的商品,所类似用户或关注用户购买、浏览过的商品)
 
2.3 电影推荐系统
包含,用户注册、登录系统,对看过的电影进行评分,点击提交评分按钮,再点击查看推荐按钮即可看见推荐的电影列表。项
目主页以及推荐结果,运行效果如下:
 
2.4 音乐推荐系统
个性化推荐的成功应用需要两个条件。第一是存在信息过载,如果用户可以很容易的从所有物品中找到喜欢的物品,就不需要个性化推荐了。第二是用户大部分时候如果没有特别明确的需求,因为用户如果有明确的需求,可以直接通过搜索引擎找到感兴趣的物品。
个性化网络音乐推荐系统正是使用到了这个原理。
这个系统学长主要通过隐式地收集用户对歌曲的播放,下载以及收藏行为记录,进而使用基于最近邻用户的协同过滤推荐算法为当前激活用户推荐歌曲;
对于有歌词信息的歌曲(英文),通过基于异构文本网络的词嵌入来计算歌曲之间的相似性,进而根据用户的历史记录为其推荐相似的歌曲。


2.5 就业推荐系统
该系统是学长使用Scrapy爬虫框架对招聘网站进行爬取,并使用ETL工具将数据存储到分布式文件系统;
利用大数据,机器学习等技术对求职者和职位信息进行画像建模,并通过推荐算法对求职者做出职位的智能推荐。


2.6 图书推荐系统
图书推荐系统,依托豆瓣的图书和评分信息,使用基于items的推荐算法,实现推荐

2.7 小说推荐系统
架构上和上面实习的图书推荐系统差不多 
3 推荐系统的评价指标
3.1 预测准确度
TopN推荐:准确率/召回率 度量覆盖率:推荐系统对物品长尾的发掘能力
3.2 马太效应
推荐系统是否有马太效应呢?推荐系统的初衷是希望消除马太效应,使得各种物品都能被展示给对它们感兴趣的某一类人群。但是,很多研究表明现在主流的推荐算法(比如协同过滤算法)是具有马太效应的。
评测推荐系统是否具有马太效应的简单办法就是使用基尼系数。如果G1是从初始用户行为中计算出的物品流行度的基尼系数, G2是从推荐列表中计算出的物品流行度的基尼系数,那么如果G2 > G1,就说明推荐算法具有马太效应
3.3 信任度
如果你有两个朋友,一个人你很信任,一个人经常满嘴跑火车,那么如果你信任的朋友推荐你去某个地方旅游,你很有可能听从他的推荐。如果你有两个朋友,一个人你很信任,一个人经常满嘴跑火车,那么如果你信任的朋友推荐你去某个地方旅游,你很有可能听从他的推荐
提高推荐系统的信任度主要有两种方法。首先需要增加推荐系统的透明度(transparency),而增加推荐系统透明度的主要办法是提供推荐解释。只有让用户了解推荐系统的运行机制,让用户认同推荐系统的运行机制,才会提高用户对推荐系统的信任度。
其次是考虑用户的社交网络信息,利用用户的好友信息给用户做推荐,并且用好友进行推荐解释
3.4 实时性
在新闻、微博等具有很强的时效性网站中,推今天的新闻往往比推昨天的新闻效果好。推荐系统需能够将新加入系统的物品推荐给用户。
3.5 健壮性
衡量了一个推荐系统抗击作弊的能力。算法健壮性的评测主要利用模拟攻击,尽量使用代价比较高的用户行为(付款),使用数据前,进行攻击检测,从而对数据进行清理
4 如何架构一个推荐系统
一般来说,每个网站都会有一个UI系统,UI系统负责给用户展示网页并和用户交 互。网站会通过日志系统将用户在UI上的各种各样的行为记录到用户行为日志中。日志可能存储 在内存缓存里,也可能存储在数据库中,也可能存储在文件系统中。而推荐系统通过分析用户的 行为日志,给用户生成推荐列表,最终展示到网站的界面上。下图便是这样的一个例子。
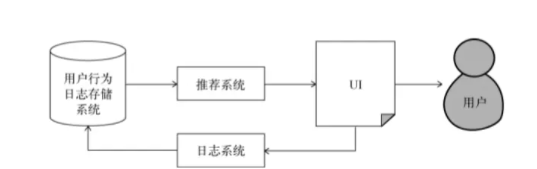
4.1 数据
数据是推荐系统的核心部分,学长以电商推荐系统为例

按照数据的规模和是否需要实时存取,不同的行为数据将被存储在不同的媒介中。一般 来说,需要实时存取的数据存储在数据库和缓存中,而大规模的非实时地存取数据存储在分布式 文件系统(如HDFS)中。 数据能否实时存取在推荐系统中非常重要,因为推荐系统的实时性主要依赖于能否实时拿到 用户的新行为。只有快速拿到大量用户的新行为,推荐系统才能够实时地适应用户当前的需求, 给用户进行实时推荐。
5 推荐系统架构
3种联系用户和物品的推荐系统
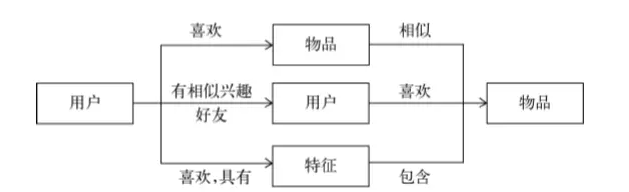 基于特征的推荐系统架构 基于特征的推荐系统架构
 用户的特征种类: 用户的特征种类:
人口统计学特征用户行为特征用户话题特征
如果要在一个系统中把上面提到的各种特征和任务都统筹考虑,那么系统将会非常复杂,而 且很难通过配置文件方便地配置不同特征和任务的权重。
6 搜索引擎上的推荐系统
推荐引擎的架构主要包括3部分
该部分负责从数据库或者缓存中拿到用户行为数据,通过分析不同行为,生成当前用户 的特征向量。不过如果是使用非行为特征,就不需要使用行为提取和分析模块了。该模 块的输出是用户特征向量。该部分负责将用户的特征向量通过特征-物品相关矩阵转化为初始推荐物品列表。该部分负责对初始的推荐列表进行过滤、排名等处理,从而生成最终的推荐结果。

7 代码实现
7.1 基于用户的协同过滤算法
#-*-coding:utf-8-*-
'''''
Created on 2016年5月2日
@author: Gamer Think
'''
from math import sqrt
fp = open("uid_score_bid","r")
users = {}
for line in open("uid_score_bid"):
lines = line.strip().split(",")
if lines[0] not in users:
users[lines[0]] = {}
users[lines[0]][lines[2]]=float(lines[1])
#----------------新增代码段END----------------------
class recommender:
#data:数据集,这里指users
#k:表示得出最相近的k的近邻
#metric:表示使用计算相似度的方法
#n:表示推荐book的个数
def __init__(self, data, k=3, metric='pearson', n=12):
self.k = k
self.n = n
self.username2id = {}
self.userid2name = {}
self.productid2name = {}
self.metric = metric
if self.metric == 'pearson':
self.fn = self.pearson
if type(data).__name__ == 'dict':
self.data = data
def convertProductID2name(self, id):
if id in self.productid2name:
return self.productid2name[id]
else:
return id
#定义的计算相似度的公式,用的是皮尔逊相关系数计算方法
def pearson(self, rating1, rating2):
sum_xy = 0
sum_x = 0
sum_y = 0
sum_x2 = 0
sum_y2 = 0
n = 0
for key in rating1:
if key in rating2:
n += 1
x = rating1[key]
y = rating2[key]
sum_xy += x * y
sum_x += x
sum_y += y
sum_x2 += pow(x, 2)
sum_y2 += pow(y, 2)
if n == 0:
return 0
#皮尔逊相关系数计算公式
denominator = sqrt(sum_x2 - pow(sum_x, 2) / n) * sqrt(sum_y2 - pow(sum_y, 2) / n)
if denominator == 0:
return 0
else:
return (sum_xy - (sum_x * sum_y) / n) / denominator
def computeNearestNeighbor(self, username):
distances = []
for instance in self.data:
if instance != username:
distance = self.fn(self.data[username],self.data[instance])
distances.append((instance, distance))
distances.sort(key=lambda artistTuple: artistTuple[1],reverse=True)
return distances
#推荐算法的主体函数
def recommend(self, user):
#定义一个字典,用来存储推荐的书单和分数
recommendations = {}
#计算出user与所有其他用户的相似度,返回一个list
nearest = self.computeNearestNeighbor(user)
# print nearest
userRatings = self.data[user]
# print userRatings
totalDistance = 0.0
#得住最近的k个近邻的总距离
for i in range(self.k):
totalDistance += nearest[i][1]
if totalDistance==0.0:
totalDistance=1.0
#将与user最相近的k个人中user没有看过的书推荐给user,并且这里又做了一个分数的计算排名
for i in range(self.k):
#第i个人的与user的相似度,转换到[0,1]之间
weight = nearest[i][1] / totalDistance
#第i个人的name
name = nearest[i][0]
#第i个用户看过的书和相应的打分
neighborRatings = self.data[name]
for artist in neighborRatings:
if not artist in userRatings:
if artist not in recommendations:
recommendations[artist] = (neighborRatings[artist] * weight)
else:
recommendations[artist] = (recommendations[artist]+ neighborRatings[artist] * weight)
recommendations = list(recommendations.items())
recommendations = [(self.convertProductID2name(k), v)for (k, v) in recommendations]
#做了一个排序
recommendations.sort(key=lambda artistTuple: artistTuple[1], reverse = True)
return recommendations[:self.n],nearest
def adjustrecommend(id):
bookid_list = []
r = recommender(users)
k,nearuser = r.recommend("%s" % id)
for i in range(len(k)):
bookid_list.append(k[i][0])
return bookid_list,nearuser[:15] #bookid_list推荐书籍的id,nearuser[:15]最近邻的15个用户
7.2 基于物品的协同过滤算法
#-*-coding:utf-8-*-
'''''
Created on 2016-5-30
@author: thinkgamer
'''
import math
class ItemBasedCF:
def __init__(self,train_file):
self.train_file = train_file
self.readData()
def readData(self):
#读取文件,并生成用户-物品的评分表和测试集
self.train = dict() #用户-物品的评分表
for line in open(self.train_file):
# user,item,score = line.strip().split(",")
user,score,item = line.strip().split(",")
self.train.setdefault(user,{})
self.train[user][item] = int(float(score))
def ItemSimilarity(self):
#建立物品-物品的共现矩阵
C = dict() #物品-物品的共现矩阵
N = dict() #物品被多少个不同用户购买
for user,items in self.train.items():
for i in items.keys():
N.setdefault(i,0)
N[i] += 1
C.setdefault(i,{})
for j in items.keys():
if i == j : continue
C[i].setdefault(j,0)
C[i][j] += 1
#计算相似度矩阵
self.W = dict()
for i,related_items in C.items():
self.W.setdefault(i,{})
for j,cij in related_items.items():
self.W[i][j] = cij / (math.sqrt(N[i] * N[j]))
return self.W
#给用户user推荐,前K个相关用户
def Recommend(self,user,K=3,N=10):
rank = dict()
action_item = self.train[user] #用户user产生过行为的item和评分
for item,score in action_item.items():
for j,wj in sorted(self.W[item].items(),key=lambda x:x[1],reverse=True)[0:K]:
if j in action_item.keys():
continue
rank.setdefault(j,0)
rank[j] += score * wj
return dict(sorted(rank.items(),key=lambda x:x[1],reverse=True)[0:N])
#声明一个ItemBased推荐的对象
Item = ItemBasedCF("uid_score_bid")
Item.ItemSimilarity()
recommedDic = Item.Recommend("xiyuweilan")
for k,v in recommedDic.iteritems():
print k,"\t",v
8 最后
|