| 基于BiLstm | 您所在的位置:网站首页 › 基于bert的实体关系抽取 › 基于BiLstm |
基于BiLstm
|
实体抽取
实体抽取主要任务就是给定一段文本,从中抽取出实体类单词,实体类单词如人名、地名、组织名、时间等名词性单词,在具体的代码实现中,我们都是事先定义抽取哪几类实体单词,这个根据具体的训练数据集而定,比如人民日报数据集中,定义了人名、地点名、组织名三类实体,在模型训练完成之后,我们的任务就是对输入的句子进行三类实体单词的抽取,并识别出单词具体属于那一类实体。 只有一个词才属于一个实体类别,一个字怎么分类呢。首先我们要对文本中每个字进行标注,标注法有BIO、BMEO等标注法。BIO标注法中,B代表每个实体类单词的开始字,I代表此实体的其它字部分,O代表非实体字部分,这样每个字就可以进行分类了。 示例如下: 我 O 爱 O 北 B 京 I 天 I 安 I 门 I 。 O但这样无法区分每个单词具体属于哪个实体,所以通常我们标注时会更加具体一点,如下: 我 O 爱 O 北 B-LOC 京 I-LOC 天 I-LOC 安 I-LOC 门 I-LOC 。 O这样就表明这个词属于地点类实体。 实现思路既然是分类问题,并且是文本数据,我们可能首先会采用RNN网络后接softmax层来进行分类,模型结构如下图所示: 此种方法能得到一定准确率,但未考虑一个问题,当某一个字被分为某一类时一定概率上会基于前一个字被分为哪一类,比如类别B-PER后被分为I-LOC类的概率明显很小。 而CRF(条件随机场)就会具备这个功能。在代码实现上,会有一个转移(transition)矩阵,如下图所示: 令此矩阵为 t r a n tran tran, t r a n [ i ] [ j ] tran[i][j] tran[i][j]代表第i个标签之后为第j个标签的概率。此转移矩阵值作为模型参数,首先会被随机初始化,然后进行训练优化。 有了转移矩阵后,最终标注方法为:首先通过排列组合的方式获取每种标注序列的得分,取最大标注序列得分为最终结果,若句子长度为m,共有n种标注类型,此种做法就要计算
n
m
n^{m}
nm种标注序列得分。在具体实现时,是采用动态规划算法——维特比算法进行计算的。 转移矩阵发挥的作用就是,对每组标注序列得分,除每个标注自身得分外,提供标签转移过程中的转移加分。BiLstm-Crf模型结构如下图: Bidirectional LSTM-CRF Models for Sequence Tagging-2015 https://www.cnblogs.com/ltolstar/p/11975937.html https://zhuanlan.zhihu.com/p/97676647 |
 通过上面的介绍,我们会发现这个任务就是一个分类任务,对于中文,在代码实现上,我们是对每个字进行分类。
通过上面的介绍,我们会发现这个任务就是一个分类任务,对于中文,在代码实现上,我们是对每个字进行分类。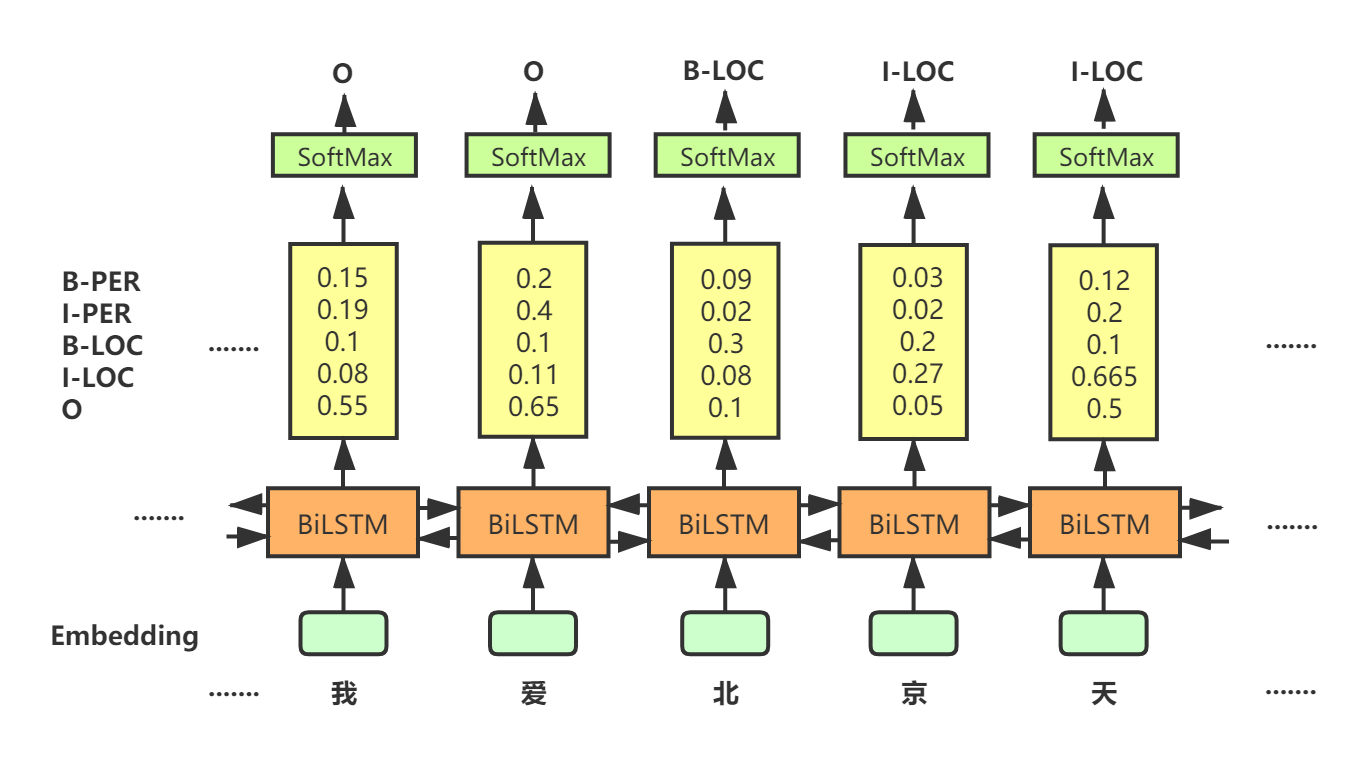 注:若文本数据输入不熟悉,可参考句子文本数据如何作为深度学习模型的输入
注:若文本数据输入不熟悉,可参考句子文本数据如何作为深度学习模型的输入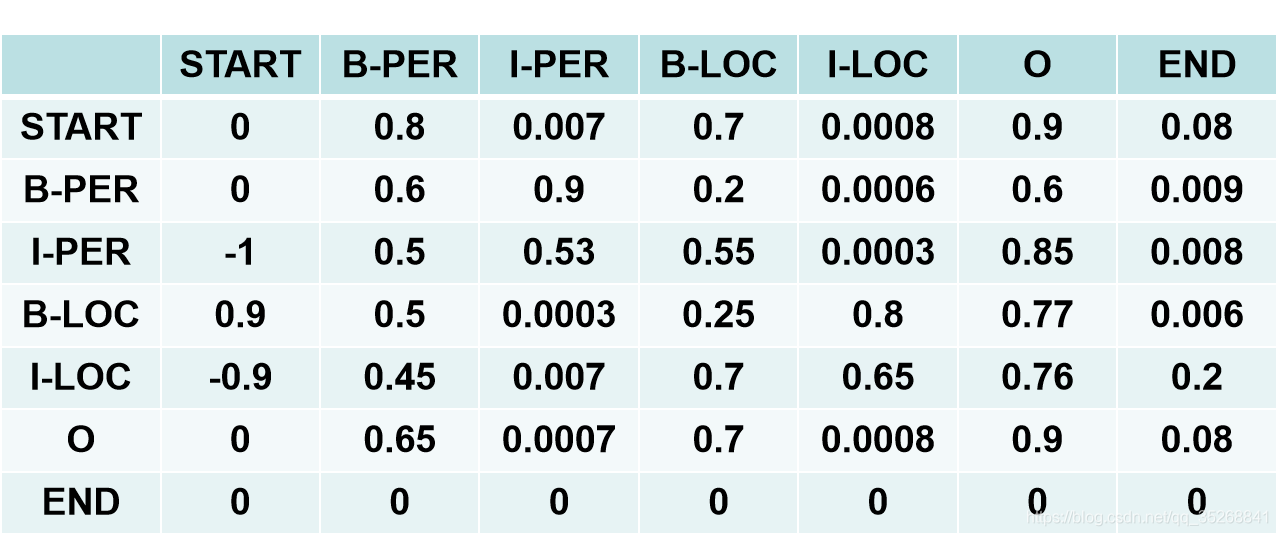 START为句子开始标签,END为句子结束标签。
START为句子开始标签,END为句子结束标签。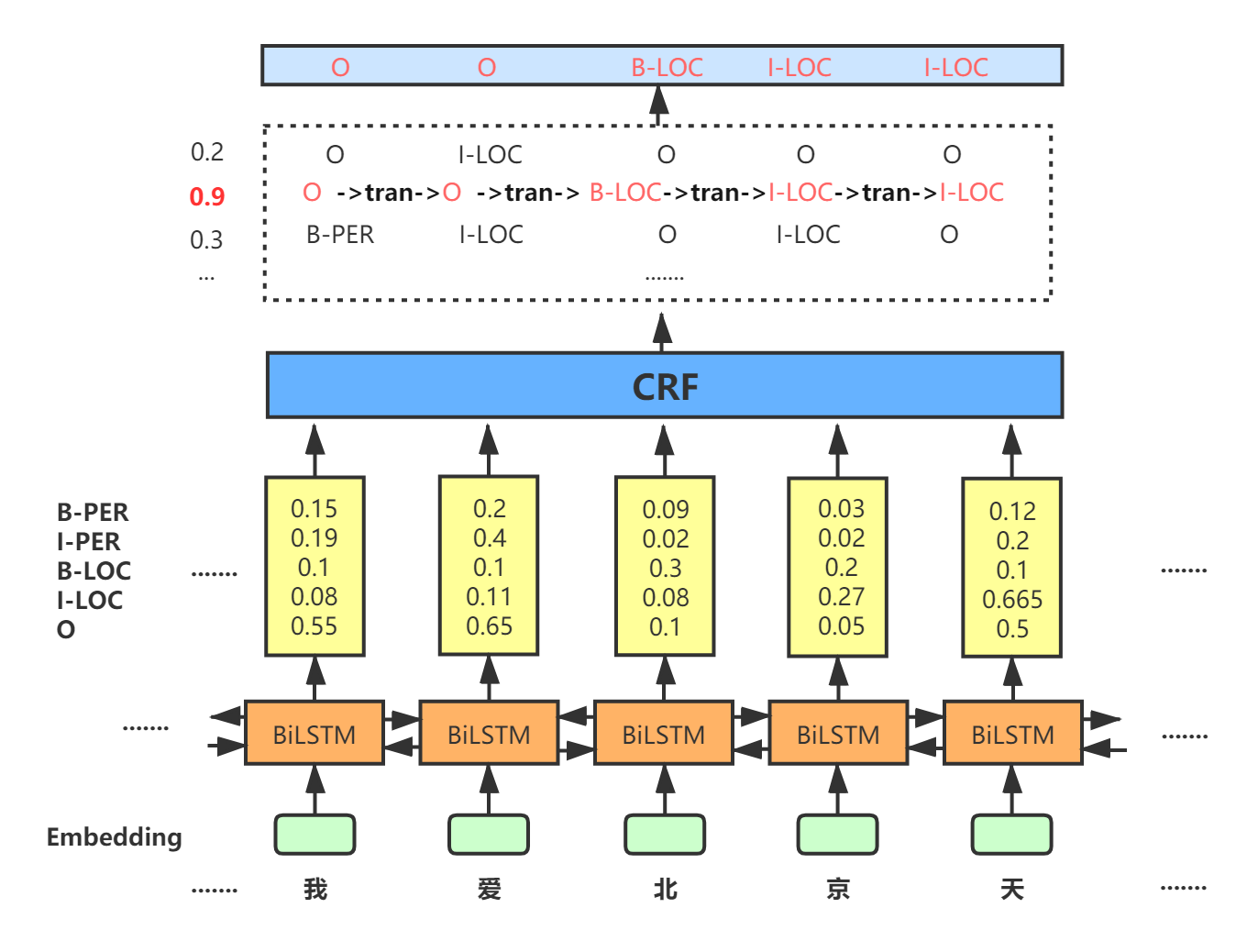 参考代码: https://github.com/buppt/ChineseNER
参考代码: https://github.com/buppt/ChineseNER【本文地址】