| 【机器学习】朴素贝叶斯实现垃圾邮件过滤 | 您所在的位置:网站首页 › 垃圾邮件分类的过程 › 【机器学习】朴素贝叶斯实现垃圾邮件过滤 |
【机器学习】朴素贝叶斯实现垃圾邮件过滤
|
朴素贝叶斯法概述
朴素贝叶斯法是基于贝叶斯定理与特征条件独立性假设的分类方法。对于给定的训练集,首先基于特征条件独立假设学习输入输出的联合概率分布(朴素贝叶斯法这种通过学习得到模型的机制,显然属于生成模型);然后基于此模型,对给定的输入 x,利用贝叶斯定理求出后验概率最大的输出 y。 贝叶斯公式我们要做的是计算在已知词向量w=(w1,w2,...,wn)w=(w1,w2,...,wn)的条件下求包含该词向量邮件是否为垃圾邮件的概率,即求(s为垃圾邮件): 根据贝叶斯公式和全概率公式有:
根据朴素贝叶斯的条件独立假设,并设先验概率 P(s)=P(s′)=0.5,上式可化为: 
接下来会用式2来计算概率 P(s|w) 准备邮件样本总共收集了正常邮件样本normal8000封,垃圾邮件样本spam8000封,然后取1至200的normal,7801至8000的spam,总共400封邮件作为测试集test,其余作为训练集。
实现步骤 (1)对训练集用结巴分词,并用停用表进行简单过滤,然后使用正则表达式过滤掉邮件中的非中文字符; (2)分别保存正常邮件与垃圾邮件中出现的词有多少邮件出现该词,得到两个词典。例如词”疯狂”在8000封正常邮件中出现了20次,在8000封垃圾邮件中出现了200次; (3)对测试集中的每一封邮件做同样的处理,并计算得到P(s|w)P(s|w)最高的15个词,在计算过程中,若该词只出现在垃圾邮件的词典中,则令 P(w|s′)=0.01P(w|s′)=0.01,反之亦然;若都未出现,则令 P(s|w)=0.4P(s|w)=0.4。 (4)对得到的每封邮件中重要的15个词利用式2计算概率,若概率 >>阈值α(设为0.9),则判为垃圾邮件,否则判为正常邮件。 实现代码先写一个方法类spamEmailBayes,用于对邮件样本进行分词,统计词频,计算贝叶斯概率,计算预测结果正确率。 分词处理 import jieba; import os; class spamEmailBayes: #获得停用词表 def getStopWords(self): stopList=[] for line in open("../data/中文停用词表.txt"): stopList.append(line[:len(line)-1]) return stopList; #获得词典 def get_word_list(self,content,wordsList,stopList): #分词结果放入res_list res_list = list(jieba.cut(content)) for i in res_list: if i not in stopList and i.strip()!='' and i!=None: if i not in wordsList: wordsList.append(i) #若列表中的词已在词典中,则加1,否则添加进去 def addToDict(self,wordsList,wordsDict): for item in wordsList: if item in wordsDict.keys(): wordsDict[item]+=1 else: wordsDict.setdefault(item,1) def get_File_List(self,filePath): filenames=os.listdir(filePath) return filenames获取对邮件分类影响最大的15个词 #通过计算每个文件中p(s|w)来得到对分类影响最大的15个词 def getTestWords(self,testDict,spamDict,normDict,normFilelen,spamFilelen): wordProbList={} for word,num in testDict.items(): if word in spamDict.keys() and word in normDict.keys(): #该文件中包含词个数 pw_s=spamDict[word]/spamFilelen pw_n=normDict[word]/normFilelen ps_w=pw_s/(pw_s+pw_n) wordProbList.setdefault(word,ps_w) if word in spamDict.keys() and word not in normDict.keys(): pw_s=spamDict[word]/spamFilelen pw_n=0.01 ps_w=pw_s/(pw_s+pw_n) wordProbList.setdefault(word,ps_w) if word not in spamDict.keys() and word in normDict.keys(): pw_s=0.01 pw_n=normDict[word]/normFilelen ps_w=pw_s/(pw_s+pw_n) wordProbList.setdefault(word,ps_w) if word not in spamDict.keys() and word not in normDict.keys(): #若该词不在脏词词典中,概率设为0.4 wordProbList.setdefault(word,0.4) sorted(wordProbList.items(),key=lambda d:d[1],reverse=True)[0:15] return (wordProbList)计算贝叶斯概率 #计算贝叶斯概率 def calBayes(self,wordList,spamdict,normdict): ps_w=1 ps_n=1 for word,prob in wordList.items() : print(word+"/"+str(prob)) ps_w*=(prob) ps_n*=(1-prob) p=ps_w/(ps_w+ps_n) # print(str(ps_w)+""+str(ps_n)) return p计算预测结果正确率 #计算预测结果正确率 def calAccuracy(self,testResult): rightCount=0 errorCount=0 for name ,catagory in testResult.items(): if (int(name)1000 and catagory==1): rightCount+=1 else: errorCount+=1 return rightCount/(rightCount+errorCount)接下来调用方法类spamEmailBayes中的方法具体实现邮件的分类 from spam.spamEmail import spamEmailBayes import re #spam类对象 spam=spamEmailBayes() #保存词频的词典 spamDict={} normDict={} testDict={} #保存每封邮件中出现的词 wordsList=[] wordsDict={} #保存预测结果,key为文件名,值为预测类别 testResult={} #分别获得正常邮件、垃圾邮件及测试文件名称列表 normFileList=spam.get_File_List(r"..\data\normal") spamFileList=spam.get_File_List(r"..\data\spam") testFileList=spam.get_File_List(r"..\data\test") #获取训练集中正常邮件与垃圾邮件的数量 normFilelen=len(normFileList) spamFilelen=len(spamFileList) #获得停用词表,用于对停用词过滤 stopList=spam.getStopWords() #获得正常邮件中的词频 for fileName in normFileList: wordsList.clear() for line in open("../data/normal/"+fileName): #过滤掉非中文字符 rule=re.compile(r"[^\u4e00-\u9fa5]") line=rule.sub("",line) #将每封邮件出现的词保存在wordsList中 spam.get_word_list(line,wordsList,stopList) #统计每个词在所有邮件中出现的次数 spam.addToDict(wordsList, wordsDict) normDict=wordsDict.copy() #获得垃圾邮件中的词频 wordsDict.clear() for fileName in spamFileList: wordsList.clear() for line in open("../data/spam/"+fileName): rule=re.compile(r"[^\u4e00-\u9fa5]") line=rule.sub("",line) spam.get_word_list(line,wordsList,stopList) spam.addToDict(wordsList, wordsDict) spamDict=wordsDict.copy() # 测试邮件 for fileName in testFileList: testDict.clear( ) wordsDict.clear() wordsList.clear() for line in open("../data/test/"+fileName): rule=re.compile(r"[^\u4e00-\u9fa5]") line=rule.sub("",line) spam.get_word_list(line,wordsList,stopList) spam.addToDict(wordsList, wordsDict) testDict=wordsDict.copy() #通过计算每个文件中p(s|w)来得到对分类影响最大的15个词 wordProbList=spam.getTestWords(testDict, spamDict,normDict,normFilelen,spamFilelen) #对每封邮件得到的15个词计算贝叶斯概率 p=spam.calBayes(wordProbList, spamDict, normDict) if(p>0.9): testResult.setdefault(fileName,1) else: testResult.setdefault(fileName,0) #计算分类准确率(测试集中文件名为1至200的为正常邮件,7801至8000的为垃圾邮件) testAccuracy=spam.calAccuracy(testResult) for i,ic in testResult.items(): print(i+"/"+str(ic)) print("正确率为:") print(testAccuracy) 代码运行结果影响每封邮件分类关键词的贝叶斯概率(概率大于0.9判为垃圾邮件,否则判为正常邮件)
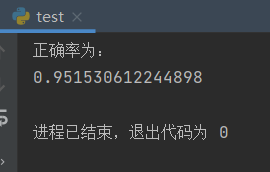
根据贝叶斯概率对测试集邮件判别情况(1为垃圾邮件,0为正常邮件) 邮件分类判别的正确率 可以看到,在400封邮件(正常邮件与垃圾邮件各一半)的测试集中测试结果为分类准确率95.15%,朴素贝叶斯分类器的分类结果还是相当好的。 总结 朴素贝叶斯的优点和缺点优点: 对待预测样本进行预测,过程简单速度快(想想邮件分类的问题,预测就是分词后进行概率乘积,在log域直接做加法更快)。对于多分类问题也同样很有效,复杂度也不会有大程度上升。在分布独立这个假设成立的情况下,贝叶斯分类器效果奇好,会略胜于逻辑回归,同时我们需要的样本量也更少一点。对于类别类的输入特征变量,效果非常好。对于数值型变量特征,我们是默认它符合正态分布的。缺点: 对于测试集中的一个类别变量特征,如果在训练集里没见过,直接算的话概率就是0了,预测功能就失效了。当然,我们前面的文章提过我们有一种技术叫做『平滑』操作,可以缓解这个问题,最常见的平滑技术是拉普拉斯估测。那个…咳咳,朴素贝叶斯算出的概率结果,比较大小还凑合,实际物理含义…恩,别太当真。朴素贝叶斯有分布独立的假设前提,而现实生活中这些predictor很难是完全独立的。 |




【本文地址】