| 对比学习正负例在干什么? | 您所在的位置:网站首页 › 困难补助申请书范文400 › 对比学习正负例在干什么? |
对比学习正负例在干什么?
|
对比学习正负例在干什么?
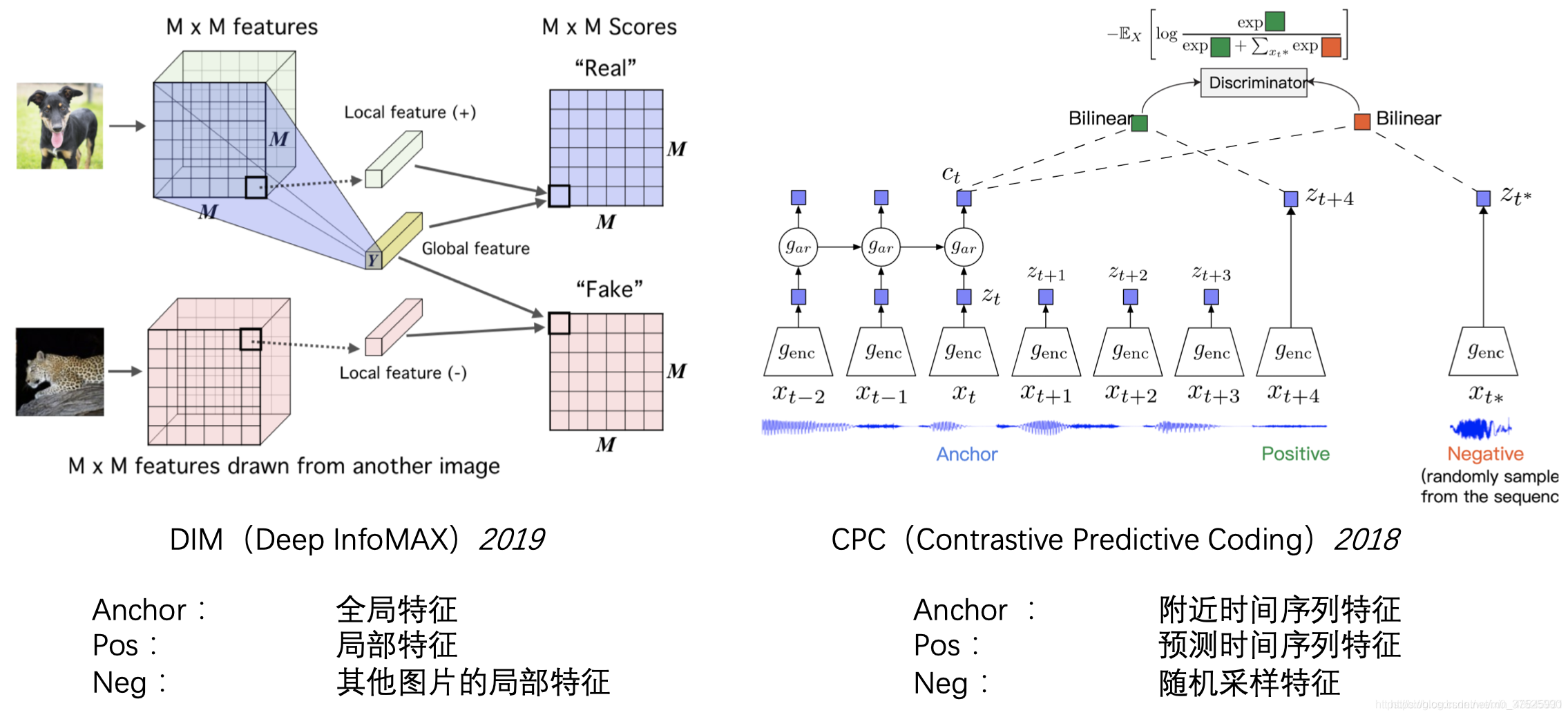
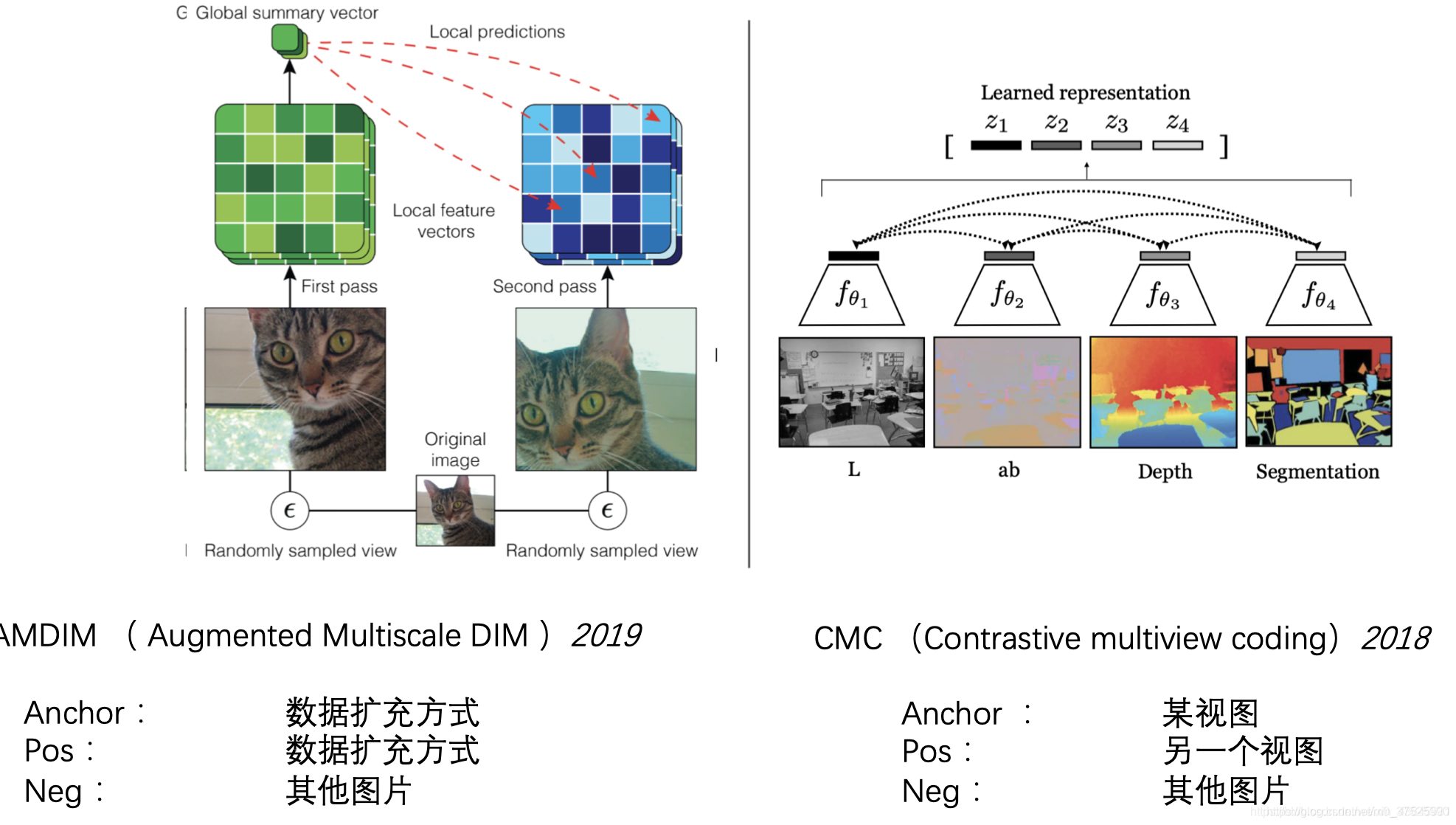
原始图片被当作一种anchor,其增强的图片被当作正样本(positive sample),然后其余的图片被当作负样本。 解决拼图问题是无监督学习中一个非常重要的部分。在对比学习中,原图被当作anchor,打乱后的图片被当作正样本,其余图片被当作负样本 上下文实例对比度主要有两种类型:预测相对位置(PRP)和最大化互信息(MI)。 它们之间的区别是: • PRP重点学习局部成分之间的相对位置。 全局上下文是预测这些关系的隐含要求(例如了解大象的长相对于预测其头尾之间的相对位置至关重要)。 • MI关注学习局部和全局内容之间关系的显式信息。 局部成分之间的相对位置将被忽略。
(b)使用一个Memory bank来存储和抽取负样本;Memory bank:的作用是在训练的时候维护大量的负样本表示。所以,创建一个字典来存储和更新这些样本的嵌入。Memory bank M M M 在数据集 D D D中对每一个样本 I I I存储一个表示 m i m_i mi。该机制可以更新负样本表示,而无需增大训练的batch size。 (c)使用一个momentum encoder当作一个动态的字典查询来处理负样本;momentum创建了一种特殊的字典,它把字典当作一个队列的keys,当前的batch进入队列,最老的batch退出队列。Momentum encoder 共享了encoder Q的参数。它不会在每次反向传播后更新, 而是依据query encoder的参数来更新: θ k ← m θ k + ( 1 − m ) θ q \theta_{k} \leftarrow m \theta_{k}+(1-m) \theta_{q} θk←mθk+(1−m)θq 在公式中, m ∈ [ 0 , 1 ) m \in[0,1) m∈[0,1) 是momentum系数。只有参数 θ q \theta_{q} θq 会被反向传播更新。 Momentum update使得 θ k \theta_{k} θk 缓慢、柔和地依据 θ q \theta_{q} θq 来更新, 使得两个encoders的区别并不会很大。 Momentum encoder的优点是不需要训练两个不一样的encoder, 而且维护memory bank会比较简单。 (d)额外使用一个聚类机制。两个共享参数的端到端架构,这种架构使用聚类算法来聚类相似样本表示。 Loss为了训练一个encoder, 需要一个前置任务来利用对比损失来进行反向传播。 对比学习最核心的观点是将相似样本靠近,不相似样本靠远。 所以需要一个相似度衡量指标来衡量两个表示的相近程度。 在对比学习中,最常用的指标是cosine similarity。 cos s i m ( A , B ) = A ⋅ B ∥ A ∥ ∥ B ∥ \cos _{s} i m(A, B)=\frac{A \cdot B}{\|A\|\|B\|} cossim(A,B)=∥A∥∥B∥A⋅B Noise Contrastive Estimation (NCE) 函数定义为: L N C E = − log exp ( sim ( q , k + ) / τ exp ( sim ( q , k + ) / τ ) + exp ( sim ( q , k − ) / τ ) L_{N C E}=-\log \frac{\exp \left(\operatorname{sim}\left(q, k_{+}\right) / \tau\right.}{\exp \left(\operatorname{sim}\left(q, k_{+}\right) / \tau\right)+\exp \left(\operatorname{sim}\left(q, k_{-}\right) / \tau\right)} LNCE=−logexp(sim(q,k+)/τ)+exp(sim(q,k−)/τ)exp(sim(q,k+)/τ 其中 q q q 是原样本, k + k_{+} k+ 是正样本, k − k_{-} k− 是负样本, τ \tau τ 是超参数,被称为温度系数。 sim ( ) \operatorname{sim}() sim() 可以是任何相似度函数,一般来说是cosines similarity 如果负样本的数量很多, NCE的一个变种 InfoNCE 定义为: L I n f o N C E = − log exp ( sim ( q , k + ) / τ exp ( sim ( q , k + ) / τ ) + ∑ i = 0 K exp ( sim ( q , k i ) / τ ) L_{I n f o N C E}=-\log \frac{\exp \left(\operatorname{sim}\left(q, k_{+}\right) / \tau\right.}{\exp \left(\operatorname{sim}\left(q, k_{+}\right) / \tau\right)+\sum_{i=0}^{K} \exp \left(\operatorname{sim}\left(q, k_{i}\right) / \tau\right)} LInfoNCE=−logexp(sim(q,k+)/τ)+∑i=0Kexp(sim(q,ki)/τ)exp(sim(q,k+)/τ k i k_{i} ki 表示负样本。 与其他深度学习模型类似, 对比学习应用了许多训练优化算法。训练的过程包括最小化损失函数来学习模型的参数。常见的优化算法包括 SGD 和 Adam 等。训练大的 batch 的网络有时需要特殊设计的优化算法,例如 LARS 引用 [1] https://blog.csdn.net/xovee/article/details/111622221 [2] https://www.jianshu.com/p/75e1f3a16812 [3] https://blog.csdn.net/weixin_43845931/article/details/109900906 |



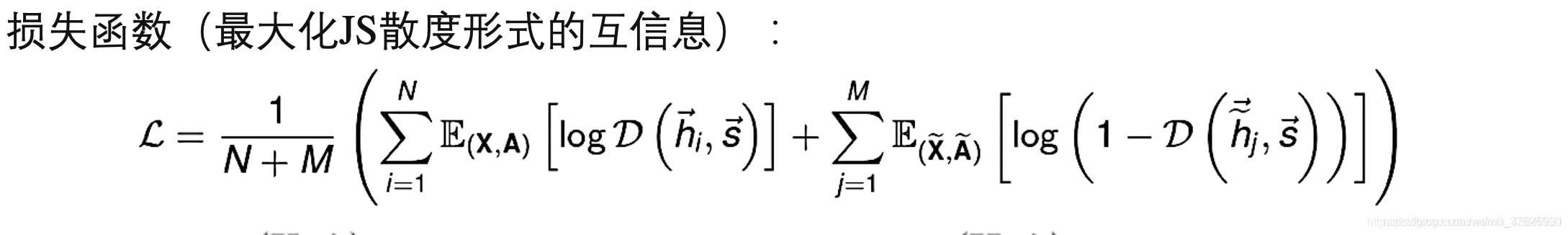


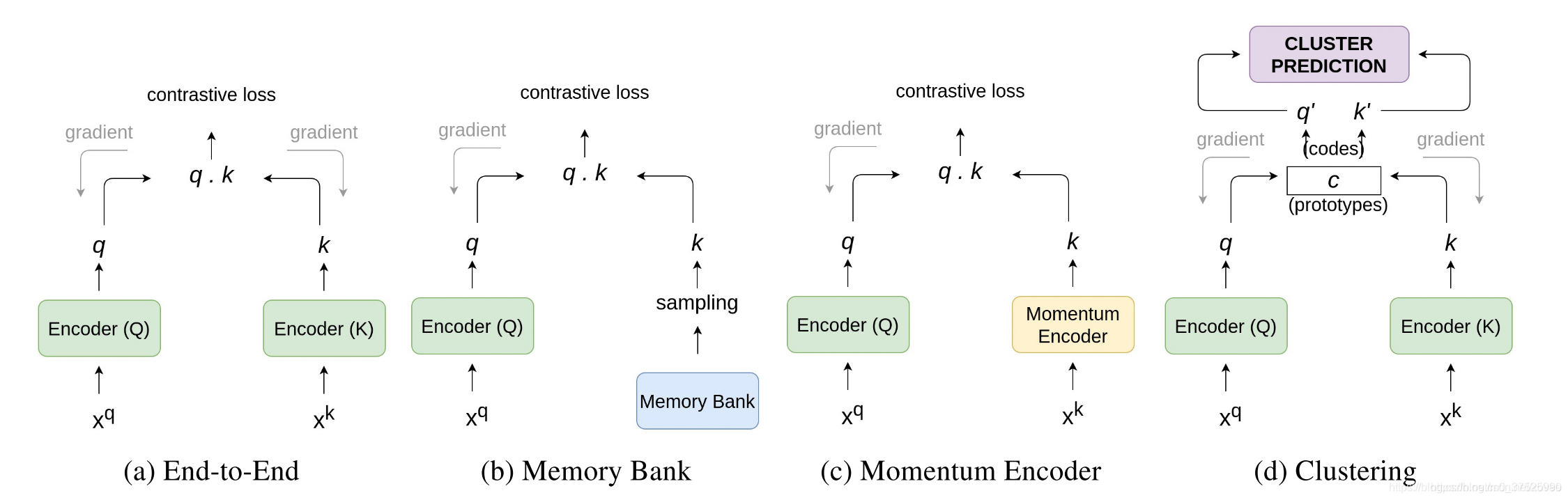 (a)端到端训练,一个encoder用来生成正样本的表示,一个encoder用来生成负样本的表示;大的batch size来存储更多的负样本,使用一个对比损失,模型会让正样本的表示相近,让负样本和正样本的表示相远。SimSLR
(a)端到端训练,一个encoder用来生成正样本的表示,一个encoder用来生成负样本的表示;大的batch size来存储更多的负样本,使用一个对比损失,模型会让正样本的表示相近,让负样本和正样本的表示相远。SimSLR【本文地址】