|
一、逻辑回归
1、有监督机器学习 线性回归:预测一个连续的值 逻辑回归:预测一个离散的值 例:阶跃函数:不连续的 2、 良性肿瘤 and 恶性肿瘤。 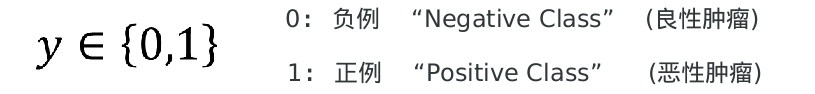 如果想要模型的y值坐落在[0,1]的区间上那么就需要使用sigmoid函数。 如果想要模型的y值坐落在[0,1]的区间上那么就需要使用sigmoid函数。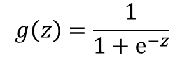
线性回归模型: 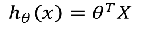 带入之后得: 带入之后得: 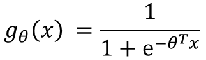  如果: 如果: 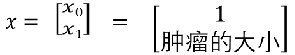 g(x) = 0.7 g(x) = 0.7   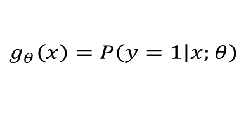 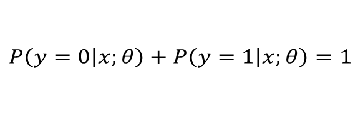 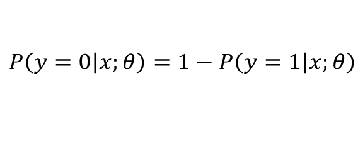 3、sigmoid函数的作用 3、sigmoid函数的作用
数学上,是根据广义线性回归的模型推导所得的结果。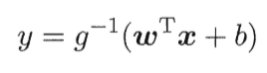 直观上, (1)输出范围有限,数据在传递中不容易发散 (2)抑制两头,对中间细微变化敏感,对分类有利 (3)性质优秀,方便使用(Sigmoid函数是平滑的,而且任意阶可到,一阶二阶导数可以直接由函数得到,不用求导,这在做梯度下降的时候很实用。 直观上, (1)输出范围有限,数据在传递中不容易发散 (2)抑制两头,对中间细微变化敏感,对分类有利 (3)性质优秀,方便使用(Sigmoid函数是平滑的,而且任意阶可到,一阶二阶导数可以直接由函数得到,不用求导,这在做梯度下降的时候很实用。
4、怎样解决比线性和非线性的决策边界? 训练集: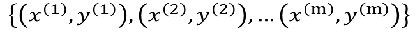 样本: 样本: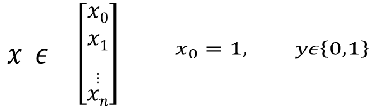 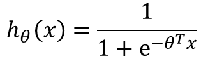 怎样选择θ? 线性回归的方法是:损失函数 怎样选择θ? 线性回归的方法是:损失函数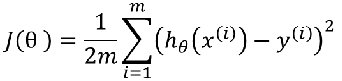 引入熵,熵的意义:热力学上:熵是一种测量分子不稳定的指标,分子运动越不稳定,熵就越大 信息论(香农):熵是一种测量信息量的单位,信息熵,包含的信息越多,熵就越大。 机器学习:熵是一种测量不确定性的单位,不确定性越大,概率越小,熵就越大! 注:信息量:越不可能发生的事情发发生了,我们获取的信息量就越大。 引入熵,熵的意义:热力学上:熵是一种测量分子不稳定的指标,分子运动越不稳定,熵就越大 信息论(香农):熵是一种测量信息量的单位,信息熵,包含的信息越多,熵就越大。 机器学习:熵是一种测量不确定性的单位,不确定性越大,概率越小,熵就越大! 注:信息量:越不可能发生的事情发发生了,我们获取的信息量就越大。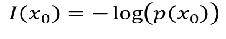 熵:表示所有信息量的期望。 熵:表示所有信息量的期望。 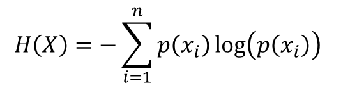 交叉熵:用来衡量两个样本分布差异的,也可以说是用来衡量两个样本的相似性 在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布。 交叉熵:用来衡量两个样本分布差异的,也可以说是用来衡量两个样本的相似性 在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布。
逻辑回归的损失函数与线性回归相似! 4、SolfMax回归 有一种逻辑回归的一般形式,叫做Softmax回归,能让你在试图识别某一分类中做出预测,或者说多分类的一种,不只是识别两个分类。 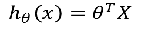 然后在做非线性变化的时候:不用 然后在做非线性变化的时候:不用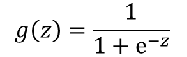 取而代之的是: 取而代之的是: 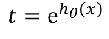 对于t求和: 对于t求和:  然后每个特征处于总和: 然后每个特征处于总和: 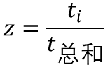 逻辑回归与SoftMax的区别 逻辑回归主要是用来做二分类的 Softmax主要是用来做多分类的;SoftMax回归将logistic激活函数推广到C类,而不仅仅是两类,如果C=2,那么softmax实际上就是逻辑回归 例1: 项目音乐分类器 逻辑回归与SoftMax的区别 逻辑回归主要是用来做二分类的 Softmax主要是用来做多分类的;SoftMax回归将logistic激活函数推广到C类,而不仅仅是两类,如果C=2,那么softmax实际上就是逻辑回归 例1: 项目音乐分类器
#encoding:utf-8
"""
基于快速傅立叶变化的音乐分类器
"""
# 用来读取wav格式的音乐数据
import numpy as np
from scipy.io import wavfile
# 用来做快速傅立叶变化
from scipy import fft
from sklearn.linear_model import LogisticRegression
from tqdm import tqdm
# 准备音乐数据
def create_fit(g, n):
"""
:param g: 音乐的分类
:param n: 音乐的索引序数
:return:
"""
# zifll返回制定长度的字符串,原字符串右对其,前面填充0
rad = "./genres/" + g + '/converted/' + g + '.' + str(n).zfill(5) + '.au.wav'
"""
sample_rate: 采样率:采样率高->样本丢失率低
采样率低->样本丢失率高
X: 就是我们的音乐文件
wavfile.read():模电转数电:把波形转乘01形式
"""
sample_rate, X = wavfile.read(rad)
"""
通过上面的变化,我们就把音乐文件从人能听懂的数据,变成了机器能看懂的数据,但是机器还不理解
"""
fft_features = abs(fft(X)[:1000])
# 把特征存到某个具体的路径下面去
sad = "./trainset/" + g + '.' + str(n).zfill(5) + ".fft"
np.save(sad, fft_features)
if __name__ == '__main__':
# 把wav格式作快速傅立叶变化,然后把结果存起来
genre_list = ["classical", "jazz", "country", "pop", "rock", "metal"]
for g in genre_list:
for n in range(100):
create_fit(g, n)
X = []
Y = []
for g in tqdm(genre_list):
for n in range(100):
rad = "./trainset/" + g + '.' + str(n).zfill(5) + ".fft.npy"
fft_features = np.load(rad)
X.append(fft_features)
Y.append(genre_list.index(g))
X = np.array(X)
Y = np.array(Y)
# print(X)
# print(Y)
"""
训练模型
"""
# model = LogisticRegression(multi_class='auto',solver='sag',max_iter=10000)
model.fit(X, Y)
"""
预测
"""
print("Staring read wavfile...")
# sample_rate, test = wavfile.read("./genres/metal/converted/metal.00082.au.wav")
sample_rate, test = wavfile.read("./genres/heibao-wudizirong-remix.wav")
testdata_fft_features = abs(fft(test))[:1000]
print(sample_rate, testdata_fft_features, len(testdata_fft_features))
type_index = model.predict([testdata_fft_features])
print(genre_list[type_index[0]])
可以利用傅立叶变化FFT FFT是一种数据处理技巧,它可以把time domain上的数据,例如一个音频,拆成一堆基准频率,然后投射到frequency domain上。 音乐的时域和频域:时域是真实世界,是惟一实际存在的域。
例2: 逻辑回归处理鸢尾花数据集
"""
逻辑回归(处理鸢尾花数据集)
"""
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
iris = datasets.load_iris()
# print(type(iris['data']))
# print(iris)
# print(iris.keys())
# print(iris['DESCR'])
# print(iris['feature_names'])
# 因为花瓣的相关系数比较高,所以分类效果比较好,所以我们就用花瓣宽度当作X
X = iris['data'][:, 3:]
# print(X)
# 把分类结果拿出来
y = iris['target']
# print(y)
# 用以上的数据做逻辑回归
log_reg = LogisticRegression(multi_class='ovr', solver='sag')
log_reg.fit(X, y)
# print("w1", log_reg.coef_)
# print("w0", log_reg.intercept_)
# 创建新的数据集去预测 创建0到3的1000个等差数列,(-1,1)就是让他在不知道多少行的情况下,变成1列,
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
# print(X_new)
# 用来预测分类的概率值,比如第一个行第一个概率最大,那么得到的y=0
y_proba = log_reg.predict_proba(X_new)
# 用来预测分类号的
y_hat = log_reg.predict(X_new)
# print(y_proba)
# print(y_hat)
# 打印花瓣宽度和分类概率的关系图
plt.plot(X_new, y_proba[:, 2], 'g*', label='Iris-Virginica')
plt.plot(X_new, y_proba[:, 1], 'r-', label='Iris-Versicolour')
plt.plot(X_new, y_proba[:, 0], 'b--', label='Iris-Setosa')
plt.show()
二、评估指标
1、评估指标 K折交叉验证 交叉验证(Cross-validation)主要用于建模应用中,在给定的建模样本中,拿出大部分样本进行建模, 留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录他们的平方加和。 2、正例和反例 对于二分类问题,可将样例根据其预测结果分为正例(Positive)和负例(Negative)
正例: 需要预测的值负例: 不需要预测的值
3、真例和反例 对于二分类问题,可将样例根据其预测类别(预测的对不对)分为真例(True)和假例(False)
真例: 预测对了假例: 预测错了
4、预测结果  差准率 = TP/(TP+FP) 差全率 = TP/(TP+FN) 例: 我们有100张数字图片, 其中是5的有10张,不是5的有90张 现在需要根据一些特征预测出所有是5的图片 有一个模型: 预测出是5的图片为9张, 其中8个确实是5,剩下1个预测错了,不是5 预测出不是5的图片有91张, 其中89张不是5,2张预测错了,是5 差准率 = TP/(TP+FP) 差全率 = TP/(TP+FN) 例: 我们有100张数字图片, 其中是5的有10张,不是5的有90张 现在需要根据一些特征预测出所有是5的图片 有一个模型: 预测出是5的图片为9张, 其中8个确实是5,剩下1个预测错了,不是5 预测出不是5的图片有91张, 其中89张不是5,2张预测错了,是5
那这个模型的查准率和查全率各是多少? 解: 由题知:TP = 8;FN = 2;FP = 1;TN = 89 差准率 = 8/9;差全率 = 8/10
5、P-R图  以查准率为纵轴,查全率为横轴作图, 就得到了查准率-查全率曲线, 简称“P-R曲线”。 P-R图直观地显示出学习器在样本总体上的查全率、查准率。在进行比较时,若一个学习器的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者。 以查准率为纵轴,查全率为横轴作图, 就得到了查准率-查全率曲线, 简称“P-R曲线”。 P-R图直观地显示出学习器在样本总体上的查全率、查准率。在进行比较时,若一个学习器的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者。
面积与平衡点(BEP)
若两个学习器的P-R曲线发生了交叉,则难以一般性断言两者孰优孰劣,只能在具体的查准率或查全率条件下进行比较。 如果非要比出个高低,可以比较P-R曲线下面积的大小,或者比较平衡点(Break-Event Point)。
6、F1 Score  如果训练分类器去检测视频是否对小孩是安全的,宁愿拒绝很多好的视频也不能让哪怕一个不好的视频被小孩看到,这种情况就用低召回率去保证好的视频,也就是要高准确率 如果训练分类器去检测视频是否对小孩是安全的,宁愿拒绝很多好的视频也不能让哪怕一个不好的视频被小孩看到,这种情况就用低召回率去保证好的视频,也就是要高准确率
如果监视录像中去检测商店小偷,那么我们可以要高召回率,低准确率(宁杀错不放过)。
所以这里有TradeOff
7、真正率和假正率  真正率:正样本预测结果数 / 正样本实际数 假正率:被预测为正的负样本结果数 / 负样本实际数 真正率:正样本预测结果数 / 正样本实际数 假正率:被预测为正的负样本结果数 / 负样本实际数  ROC含义: ROC含义:  ROC曲线 ROC曲线  对于一个ROC曲线来说,这个曲线可以理解为一个模型,用不同的阈值画出来的曲线。 纵轴:真正例率(True Positive Rate),TPR 横轴:假正例率(False Positive Rate),TPR 对于一个ROC曲线来说,这个曲线可以理解为一个模型,用不同的阈值画出来的曲线。 纵轴:真正例率(True Positive Rate),TPR 横轴:假正例率(False Positive Rate),TPR  若一个学习器的ROC曲线被另一个学习 曲线完全“包住”,则可断言后者的性能 优于前者 若两个学习器的ROC曲线发生交叉,则 难以一般性地断言两者孰优孰劣 若一个学习器的ROC曲线被另一个学习 曲线完全“包住”,则可断言后者的性能 优于前者 若两个学习器的ROC曲线发生交叉,则 难以一般性地断言两者孰优孰劣
如果一定要进行比较,则较为合理的判 断是比较ROC曲线下的面积, 即AUC(Area Under Roc Curve) AUC面积  特点: 1、面积数值不会大于1 2、AUC一般情况下取值范围在0.5和1之间 3、使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。 特点: 1、面积数值不会大于1 2、AUC一般情况下取值范围在0.5和1之间 3、使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
|