| Yolov5+Resnet+Flask实现唇语识别系统 | 您所在的位置:网站首页 › 嘴唇模型图片 › Yolov5+Resnet+Flask实现唇语识别系统 |
Yolov5+Resnet+Flask实现唇语识别系统
|
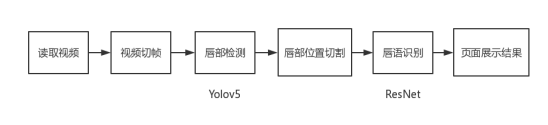
分享源码 https://github.com/wjwzy/lip_reading 部分内容参考https://blog.csdn.net/weixin_42907473/article/details/103470208 这个代码是我大四的时候东拼西凑出来的,应付毕业设计,里面很多代码写的都很low,且效率低下,现在忙着工作也懒得改了,有兴趣者自己修改或者重构吧 < G _ O > 还有数据集的问题,之前备份的硬盘坏掉了,我也没了!!!有想法者可以去找一找,我当时也是找了很久才看到有其他博主分享的 目录 1.摘要2.项目流程3.部分代码展示3.1.代码结构3.2.demo主程序3.3.视频切帧3.4.目标检测模块处理3.5.图片裁剪3.6.唇读推理模块预处理3.7.模型预测 4.核心技术分析4.1.数据分析4.2.目标检测算法4.3.分类网络 5.预处理trick5.1.数据增广5.2.帧数填充 6.效果展示6.1.训练效果6.2.页面展示效果 7.弱点分析8.总结 1.摘要项目主要针对基于视频的计算机唇读系统中唇部检测、唇读特征提取和唇语识别等关键技术进行了研究。具体来说,首先对数据进行预处理,包括对视频进行切帧和增广处理;然后采用Yolov5算法对唇部检测并截取有效区域进行后续处理;接着设计了一个新型网络用于唇部特征的提取和识别。该网络融合了3DResNet和GRU网络,能够同时利用视频数据的空间和时间信息,进而提取高效的特征获得较好的识别结果。最后,为了体现可视化和实用性,本文使用Flask框架实现了唇读系统的各个功能,可以在web端体验唇读系统的识别效果。 2.项目流程研究的主要内容是对中文唇语词语的识别功能,研究的问题涉及到唇部定位、数据特征提取、网络对特征的预测结果以及web端实现前后端数据交互四个方面。而最为关键的,就在于特征提取以及预测结果两个方面,重点设计可行的深度学习方案,对比各种方法来研究出本文的最佳实现手段。对于模型的鲁棒性和泛化能力,项目需要大量而又无误的数据集支持,以及采用合适该数据集的网络模型,才能保证网络拥有强有力的表现能力。 在系统功能上,用户需要登录成功才能使用唇语识别功能,项目流程如图所示。 在技术路线上,第一个模块是目标检测,该模块需要准确的找到人脸的唇部位置,并且通过预测的坐标对图像进行切割,保证唇部位于图像的最中间位置,项目实现算法为Yolov5算法,采用最小的预训练模型进行训练。在目标检测数据集的制作中,需要保证数据的完整性,并且标注的嘴唇应该位于图像的最中间位置,达到唇部定位的效果,这样可以大程度加快后续分类网络的拟合速度。 第二模块采用的是3DResNet与GRU复合式网络,通过Yolov5算法处理过的数据传入该网络中,残差结构提取特征,GRU保证时序信息的传递与保存,再通过softmax得到预测的结果。在该模块中,训练数据的数量尤为关键,所以在预处理中,使用数据增广让网络有充足的数据训练。其次,网络的结构也非常重要,残差网络ResNet是由多层网络堆叠而成,解决网络深度造成的梯度消失问题,让网络更深,提取到的图像信息特征越多越有效。而循环神经网络RNN的变种体GRU则是通过了门的控制机制,使时序信息得到很好的保留,让神经网络更加关注的是时间序列的唇部动态变化信息。 预测结果最终传入web模块,依靠html和js完成前后端的交互,实现的系统的识别功能。在web模块中,所使用的框架是Flask框架,该框架优点就是轻巧灵活,在登录功能中html直接往后端提交表单,后端只要通过数据库对表单进行校验,就可以完成登录功能。在识别功能中,通过js配合html读取本地视频,再提交到后台进行处理,处理过程首先是经过视频切帧,然后Yolov5模型对帧数图像进行唇部坐标预测,再切割图像并保存,最后通过分类网络得到预测的结果,识别的词语展示到前端页面即可完成整个功能的流程,处理的流程如图所示。 项目采用的技术为当今最主流的one-stage目标检测算法Yolo,用来辅助残差网络ResNet对视频进行唇语翻译,该目标检测算法首次应用于唇语识别中,使系统达到端到端的识别效果。其次数据集是由多帧数图像组成单一样本,存在缺帧等问题,给项目带来了一定的难度。项目还采用了python轻量级web框架Flask,通过前端html和js的配合使用来操作深度学习算法,达到视觉上的展示效果,让用户可以使用网页端操作唇语识别系统。 3.部分代码展示 3.1.代码结构项目由三部分构成,唇读模块、目标检测模块和web端demo模块,由于目标检测的模型路径问题,将demo和yolov5整合到了一个目录下。 post请求将前端读取的视频先保存至本地相应目录,再做后续相关操作。 @app.route('/predict', methods=['GET', 'POST']) def predict(): if requesthod == 'POST': try: # 读取video文件 f = request.files['file'] # 保存前端读取的视频到uploads basepath = args.save_video file_path = os.path.join(basepath, secure_filename(f.filename)) f.save(file_path) img_list = video_to_frames(file_path) cut_img_list = cut_img(img_list) del img_list vocab_path = 'lip_models/vocab100.txt' # 载入网络进行预测 result = model_predict(model, cut_img_list, vocab_path, args.device) result = str(result[0]) print("识别结果:" + result) return result except Exception as e: return "错误,无法正确识别" return None 3.3.视频切帧切帧直接存入list返回 def video_to_frames(path): """ 输入:path(视频文件的路径) """ # VideoCapture视频读取类 # 抽取帧数 videoCapture = cv2.VideoCapture() videoCapture.open(path) # 总帧数 frames = videoCapture.get(cv2.CAP_PROP_FRAME_COUNT) img_list = [] for i in range(int(frames)): ret, frame = videoCapture.read() if i % 4 == 0: img_list.append(frame) print("视频切帧完成!") return img_list 3.4.目标检测模块处理重新构建一个类,将加载模型初始化,由于只有一个类别,因此classes为0,定义detect方法,传入参数为图像的list,返回结果为对应坐标的list。 class yolov5(object): def __init__(self, img_size = 416, weights = 'runs/train/exp/weights/best.pt', iou_thres = 0.45, conf_thres = 0.25, device = '0', classes = 0, agnostic_nms = False, augment = False ): self.imgsz = img_size self.iou_thres = iou_thres self.conf_thres = conf_thres self.device = select_device(device) self.classes = classes self.agnostic_nms = agnostic_nms self.augment = augment # Initialize set_logging() self.half = self.device.type != 'cpu' # half precision only supported on CUDA # Load model self.model = attempt_load(weights, map_location=self.device) # load FP32 model def detect(self, source): stride = int(self.model.stride.max()) # model stride imgsz = check_img_size(self.imgsz, s=stride) # 检查图片的大小 if self.half: self.model.half() # to FP16 cudnn.benchmark = True # 设置True可以加速恒定图像大小的处理速度 # Run inference if self.device.type != 'cpu': self.model(torch.zeros(1, 3, imgsz, imgsz).to(self.device).type_as(next(self.model.parameters()))) # run once result = [] for img0 in source: imgsz = check_img_size(imgsz) # check img_size img = letterbox(img0, imgsz, stride=32)[0] # Convert img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416 img = np.ascontiguousarray(img) img = torch.from_numpy(img).to(self.device) img = img.half() if self.half else img.float() # uint8 to fp16/32 img /= 255.0 # 0 - 255 to 0.0 - 1.0 if img.ndimension() == 3: img = img.unsqueeze(0) # 获取模型预测 pred = self.model(img, augment=self.augment)[0] # 使用NMS进行预测 pred = non_max_suppression(pred, self.conf_thres, self.iou_thres, classes=self.classes, agnostic=self.agnostic_nms) # 过程检测 for i, det in enumerate(pred): # 遍历预测框 # 还原图像坐标值大小 det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round() result.append(det[0][:4].tolist()) return result 3.5.图片裁剪目标检测模块得到唇部坐标,然后裁剪保存至新的list中返回。 # 根据预测得到的坐标进行裁剪 def cut_img(img_list): # 进行目标检测得到坐标点 result = yolov5_det.detect(img_list) cut_img_list = [] for idx, image in enumerate(img_list): labels = result[idx] cropped = image[int(labels[1]): int(labels[3]), int(labels[0]):int(labels[2])] cut_img_list.append(cropped) print("嘴型检测并裁剪完成!") return cut_img_list 3.6.唇读推理模块预处理 def _sample(cut_img_list, bilater = True): data = [] for img in cut_img_list: img = img_clip(img) # 缩放并填充至112大小 if bilater and random.random() |


【本文地址】