| 葵花8(Himawari | 您所在的位置:网站首页 › 嗅探使用方法 › 葵花8(Himawari |
葵花8(Himawari
|
这一篇博客简单介绍一下基于葵花8L1级数据下载的两种方法:1.使用FTP工具连接葵花8的数据站点进行下载2.使用python代码下载葵花8的L1级数据1.使用FTP工具下载 1.1 注册葵花8官网账号 首先进入葵花8,9的官方网站: 葵花8数据的官网,然后选择用户注册,进入注册页面。  进入注册页面之后,在下面图片中的位置输入两次邮箱(最好用国外邮箱),不过也不是必须,也可以使用QQ邮箱等,然后点击下面的确认提交。 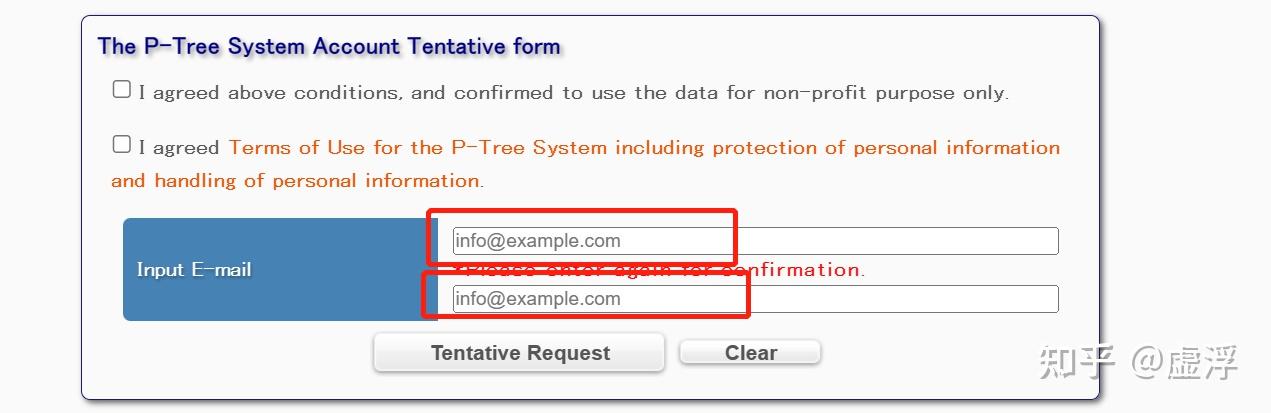 然后你的邮箱会收到一封葵花8官方发送的邮件,点击下图的链接进入: 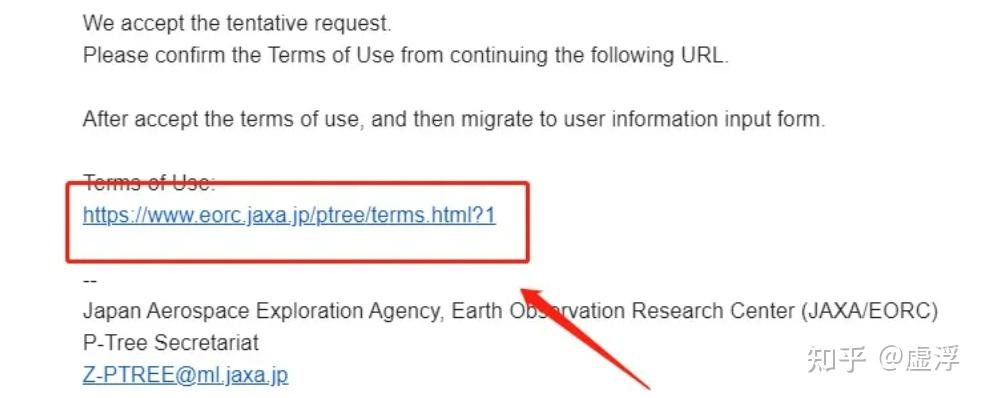 滑到跳转后的网页的最下面,点击agree  这时就会进入账号信息填写界面,按照提示填写即可,填写完之后葵花8官网会发送一封邮件,里面有账户名和密码(可以复制保存一下,后面会用到)。  1.2 数据下载 1.2 数据下载因为葵花8官方给我们的是ftp链接,所以此时我们需要先安装一个FTP工具,这里推荐一个FTP工具:filezilla,下载地址:filezilla官网  点击下载软件,然后进行安装,安装完毕后打开软件,点击下图所示的位置,配置站点信息:   点击确认连接,窗口右侧就出现了下载文件目录,L1级数据在jma文件夹里面:  点击打开jma文件夹,选择需要下载的数据类型(netcdf/hsd两种类型),然后点击进去选择下载时间:  然后将选中的数据往左侧本地文件位置拖拽就可以进行下载了。  2.使用python下载葵花8的L1级别数据 2.使用python下载葵花8的L1级别数据 这里不介绍使用requests库进行下载的方法,介绍一下使用python第三方库下载的方法: 首先我们下载需要使用的python包: pip install lb_toolkits下面是官方文档的示例代码: from lb_toolkits.downloadcentre import downloadH8 nowdate = datetime.datetime.strptime('20221027', '%Y%m%d') down = downh8file(username=FTP_USER, password=FTP_PAWD) filelist = down.search_ahi8_l1_netcdf(nowdate) down.download('./data', filelist) filelist = down.search_ahi8_l1_hsd(nowdate) down.download('./data', filelist)简单解释一下上面的代码: 第一行是导入downloadH8这个类;第二行是设置下载的开始时间,注意这个时间必须是datetime类型,源码里面是这样写的;第三行是输入用户名和密码来初始化downloadH8这个类(不是downh8flie),这里官方文档写错了,可以自己修改一下;第四行代码就是搜索这个时间所有的葵花8L1级数据的文件列表;第五行代码调用download函数进行下载;后面两行代码就是hsd数据的下载,目前这个数据类型的接口有问题会报错,等待作者修复吧。 下面在官网基础上介绍一下如何按照自己的需要下载特定时间的数据: 这里以批量下载每天的特定时间段和多个月的数据为例: # 导入包 from lb_toolkits.downloadcentre import downloadH8 from datetime import datetime import calendar # 自定义下载分辨率5KM的每日整点L1级数据的函数 def down_h8(start, end): """ :start 开始时间 :end 终止时间 """ # 将输入的开始时间转换成datetime格式,后面的"%Y%m%d%H%M"格式化方式按照自己的需要进行修改 nowdate = datetime.strptime(start, "%Y%m%d%H%M") # 将输入的终止时间转换为datetime格式 enddate = datetime.strptime(end, '%Y%m%d%H%M') # 初始化下载类,将你的用户名和密码分别赋值给username和password两个参数 down = downloadH8(username=username, password=password) # 下载自己需要的nc数据 # 获取下载列表 filelist = down.search_ahi8_l1_netcdf(nowdate, enddate) # 新建一个列表用来保存需要下载的文件链接 down_list = [] # 循环获取到的文件列表按照自己需要进行筛选 for file in filelist: # 按照需要进行匹配(这里是需要下载5KM分辨率的每日整时数据) name_list = file.split("_") if (name_list[3][2] == '0' and name_list[3][3] == '0') and (name_list[6][2] == '4') and name_list[1] == 'H08': down_list.append(file) # 进行数据下载 down.download('数据下载路径', down_list) down(start, end) # 调用函数就可以下载上面就是一个简单的下载函数示范,如果大家想要批量下载几年或者几个月的数据,可以自己设置年的列表或者月的列表,循环读取下载就好。当然,如果觉得第三方库的功能比较局限,可以自己将python包的代码从github复制过来进行修改就好,为了方便,这里也贴一下源码: import os import sys import datetime import time from lb_toolkits.tools import ftppro from lb_toolkits.tools import writejson FTPHOST='ftp.ptree.jaxa.jp' class downloadH8(object): def __init__(self, username, password): self.ftp = ftppro(FTPHOST, username, password) def search_ahi8_l1_netcdf(self, starttime, endtime=None, pattern=None, skip=False): ''' 下载葵花8号卫星L1 NetCDF数据文件 Parameters ---------- starttime : datetime 下载所需数据的起始时间 endtime : datetime 下载所需数据的起始时间 pattern: list, optional 模糊匹配参数 Returns ------- list 下载的文件列表 ''' if endtime is None : endtime = starttime downfilelist = [] nowdate = starttime while nowdate endtime) : continue downflag = True # 根据传入的匹配参数,匹配文件名中是否包含相应的字符串 if pattern is not None : if isinstance(pattern, list) : for item in pattern : if item in filename : downflag = True # break else: downflag = False break elif isinstance(pattern, str) : if pattern in filename : downflag = True else: downflag = False if downflag : srcname = os.path.join(srcpath, filename) srcname = srcname.replace('\\','/') downfiles.append(srcname) return downfiles def writeok(self, okname, info): writejson(okname, info)到此,本篇推文的内容就结束了,有问题欢迎交流。 参考资料:https://lb-toolkits.readthedocs.io/zh/latest/overview.html https://zhuanlan.zhihu.com/p/440754592 https://github.com/libin033/lb_toolkits |
【本文地址】