| 详解哈希数据结构,手写哈希表 | 您所在的位置:网站首页 › 哈希函数怎么设计 › 详解哈希数据结构,手写哈希表 |
详解哈希数据结构,手写哈希表
|
哈希表,终于姗姗来迟了。 本文系统讲解了哈希表数据结构的相关概念,并以HashMap为案例讲解一下它与普通哈希表的不同点,最后也手写一个简易的哈希表。 所以通过本文,我希望读者们能对哈希表有一个清楚的认识,尤其是在Java面试过程中,HashMap的相关面试题几乎是逢面必问,如果你连哈希表结构都不清楚,那真的很难从根上理解HashMap。 除了面试,在你掌握了哈希表之后也可以根据应用场景的需要,对哈希函数进行重写,以此来保证在你的应用场景下哈希分布的更加均匀。 本文概览如下:
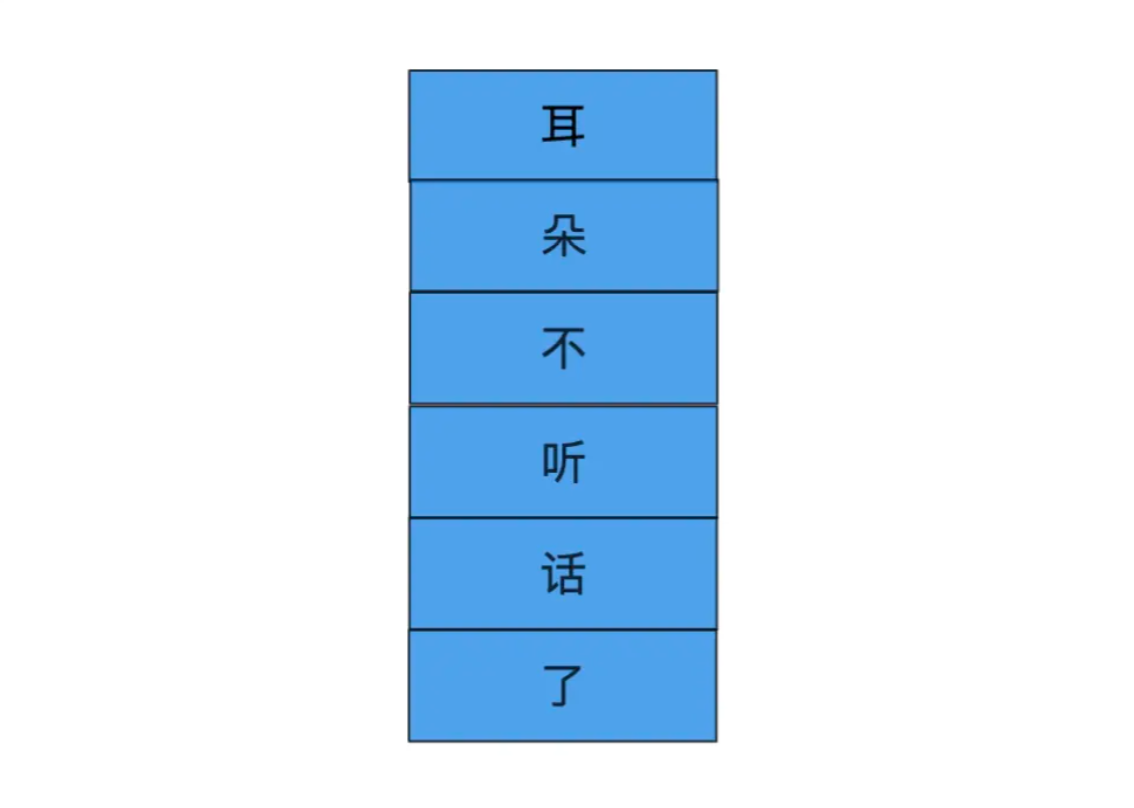
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 哈希作为一个非常常用的查找数据结构,它能够在O(1) 的时间复杂度下进行数据查找。 比方说我有一个集合有如下数据,而我想要快速查找一个数据在不在这个集合中,我应该采取什么办法?
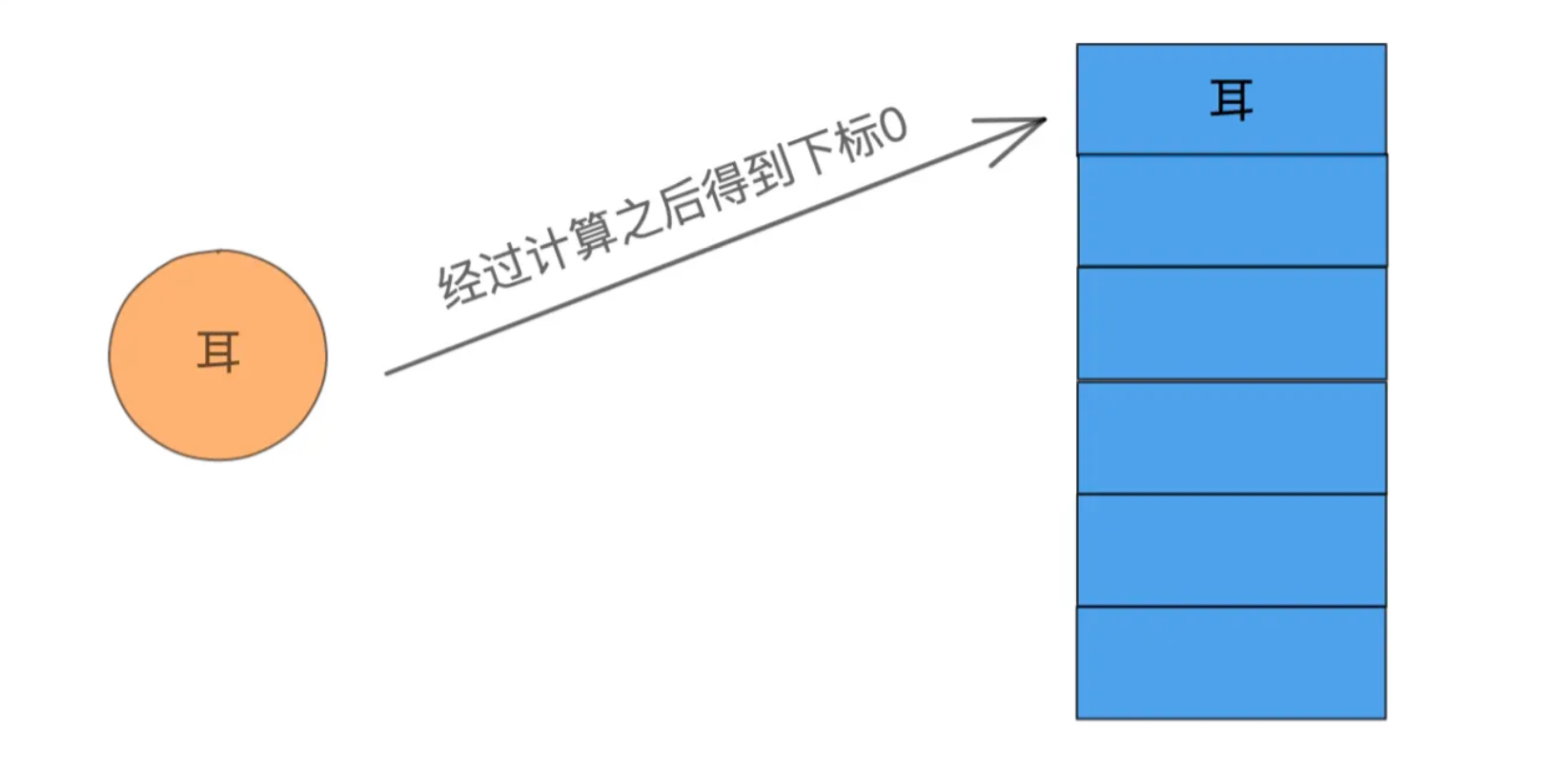
一般情况下可以使用遍历的方式,但是如果数据量太多,则每次遍历的代价将不可接受。 那么,如果它们是有序的,则可以使用树形数据结构进行二分查找,效率也是非常的高,但很不巧我们这些数据是无序的。 所以就有人想到一个很巧妙的办法来寻找它,就是将要寻找的数据(下文称为键)进行一次计算得到一个数组下标值,然后将这个值放到对应的数组里。
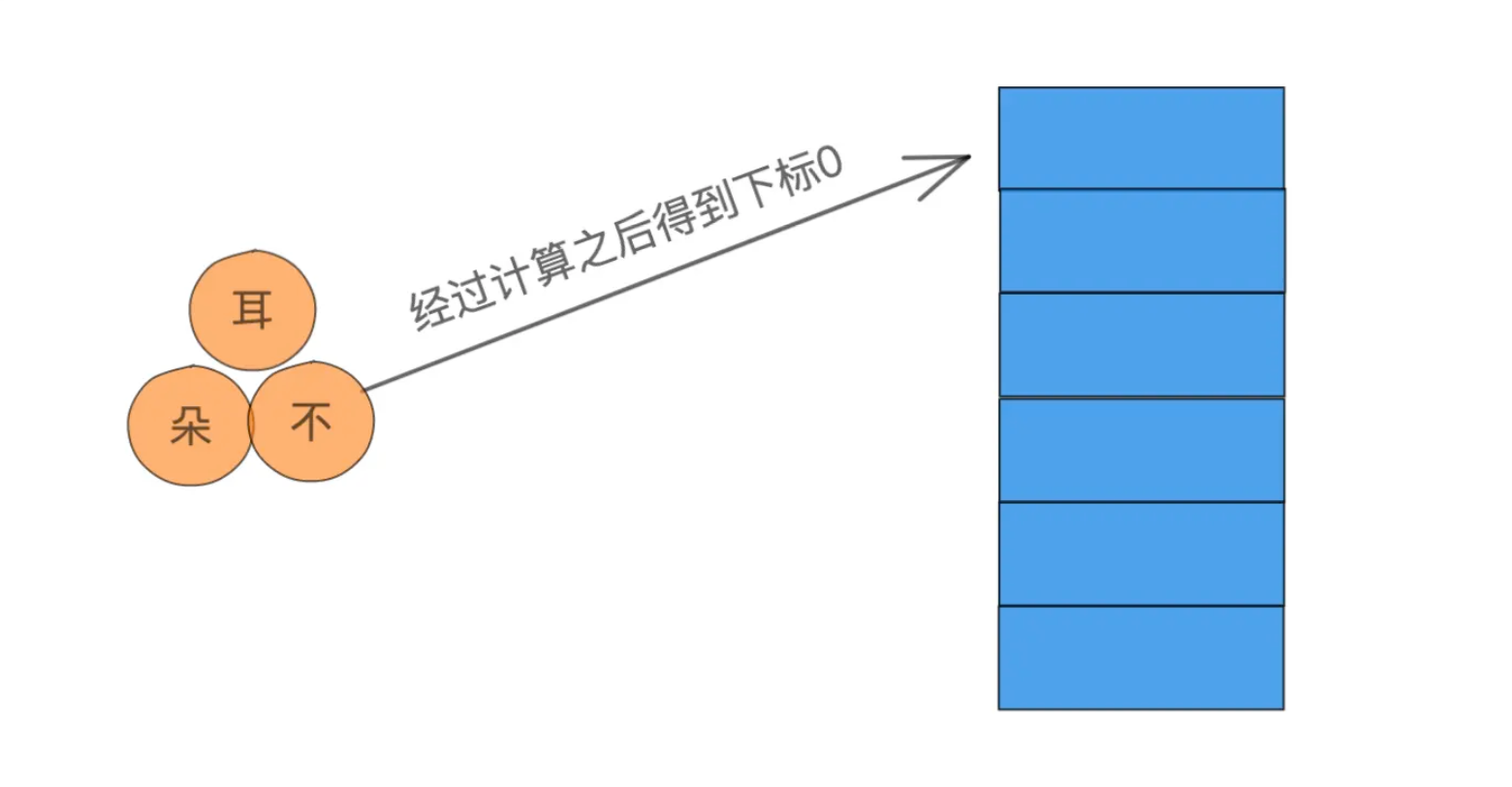
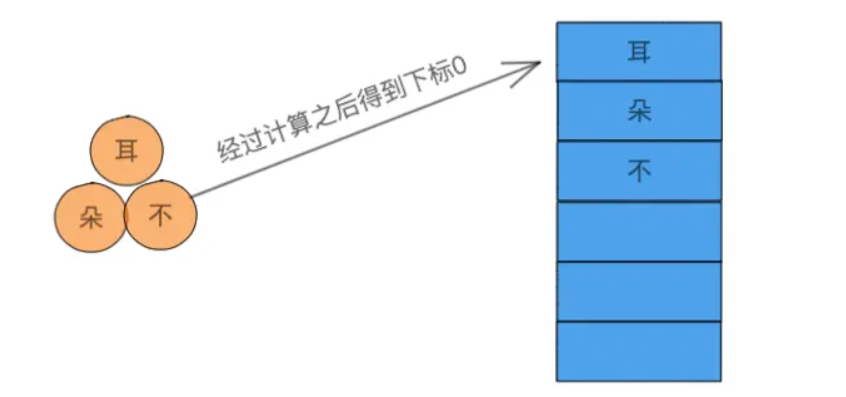
以后我们每次寻找的时候都对键进行计算从而得到一个数组下标值,然后通过下标拿到数组对应的数据,就能知道它是否存在于这个数组中了。 这种数据查找的数据结构就叫做哈希表,对键的计算的方法叫做哈希函数。 在Java中,典型的Hash数据结构的类是HashMap。 我们回顾一下哈希表的执行步骤: 对键进行哈希函数计算,得到一个哈希值。对哈希值进行计算得到一个数组下标。通过数组下标得到数组中对应的数组。由于哈希表的查找步骤与哈希函数都是恒定不变的,所以哈希表的时间复杂度为O(1)。 2. 哈希函数哈希函数是一种提取数据特征的算法,针对不通的数据形式有不同的哈希算法,所以哈希函数并不通用,针对不同场景有很多不同的哈希算法,比如我们常见的MD5就是一种获取文件信息摘要的哈希算法。 再比如在Java中,对于常用的数据类型,JDK就实现了多种不同的hash函数。 Integer: public static int hashCode(int value) { return value; }复制代码Integer的哈希函数就是直接拿到它的值。 String: public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { hash = h = isLatin1() ? StringLatin1.hashCode(value) : StringUTF16.hashCode(value); } return h; }复制代码对于字符串类型则是使用了一个这样一种算法:s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]。 Double: public static int hashCode(double value) { long bits = doubleToLongBits(value); return (int)(bits ^ (bits >>> 32)); }复制代码浮点类型则是使用位运算的方式进行哈希计算。 读者们可能会有疑惑,为什么要对这么多数据结构实现不同的哈希计算方法,这主要还是为了哈希值的均匀。 哈希值越均匀,就说明哈希函数设计的越好,也预示的哈希冲突的减少,关于哈希冲突,将在下节讲到。 在第一节的时候我说过,除了计算哈希值,我们还需要计算数组的位置。 计算数组位置有很多方法可用,这里我就介绍比较简单的除留余数法: 假设我对中国人这个key进行计算,得到了一个哈希值:19942986,那么我将用这个数字对数组的大小进行取余,这里我假设自己的数组大小是11,就得到这样的计算公式: 19942986 % 11 = 8 那么,我们就得出了本次哈希函数的结果为数组下标8,我们就可以将中国人这个字符串放到了数组下标8的位置上。 既然哈希值计算希望越均匀越好,那么数组下标是否也有类似的需求呢? 还真有,比如我们上面的除留余数法,在除留余数法中,数组大小的选择将深刻影响着取余结果是否均匀,所以在除留余数法中,我们一般使用质数,这也是为什么HashTable的初始化大小为11,因为11是一个质数。 3. 哈希冲突经过前文的学习后,相信大家对哈希表的相关概念都已经清楚了,那么本节就来学习哈希表的一大重点:哈希冲突。 哈希冲突是指多个不同的键散列到了同一个数组下标位置上,案例如下:
在上图中,耳、朵、不这三个字经过散列之后的数组下标都是0,而且因为是三个不同的值,所以也不能直接在数组上覆盖,那么我们就需要有一个办法把这三个值存起来。 这里将介绍两种常用的方法:开放地址法和链地址法。 开放地址法是一种比较简单的解决冲突的方法,它的原理非常简单:
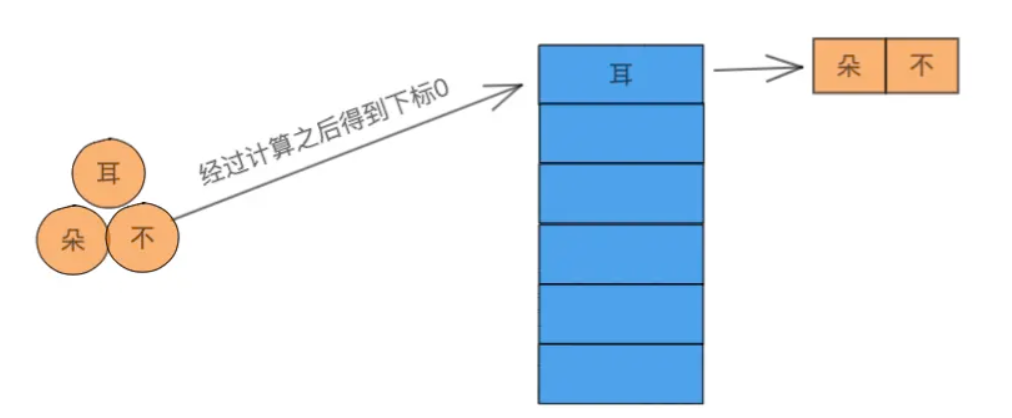
就是在第一个耳字已经占用了下标0之后,第二个朵字则向后进行寻找空余的下标,找到之后将自己设置进去,所以朵字在下标1处,而不字在下标2处。 根据寻找下标的方式不同,开放地址法可以分为以下几种: 线性探测法:下标被占用之后,以步长为1依次向后寻找,上图例中我使用的就是这种方法。二次探测法:下标被占用之后,步长为2的倍数,依次向后寻找。伪随机探测法:下标被占用后,随机出一个数字,然后使用这个数字作为下标进行寻找,这种方法全靠天意了。其实原理都差不多,都是在当前下标的基础上向后寻找空余的下标,不过步长不一样罢了。 链地址法俗称拉链法,就是在冲突的下标元素处维护一个链表,所有冲突的元素都依次放到这个链表上去:
在上图中,我将冲突的两个键就按照顺序放在了链表中,下次寻找时只需要查看该数组元素以及遍历这个链表即可,在Java中的HashMap中就是用了这种方法进行解决哈希冲突。 以上两种方法都有可能随着冲突的增多,导致查找效率变低,所以没有一个完美的方案可以解决哈希冲突的问题,我一般推荐使用拉链法,因为它比较简单易理解。 4. HashMap案例前文中大量提到了HashMap,这一节就将对HashMap中的一些和上文讲述不一样的关键点进行梳理。 首先是HashMap的表容量,表容量就是这个哈希表中可以装下多少个元素。 前文我已经说过,在哈希表中最好使用质数作为表的容量,并且还拿了HashTable作为举例。 而在HashMap中,它的初始容量是16,这不光是一个偶数还是2的倍数。 HashMap之所以没有使用质数而是使用2的倍数作为它的容量,是因为它在计算数组下标时没有使用除留余数法,而是使用了位运算进行计算数组下标。 static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }复制代码计算完哈希值之后,则是使用哈希值和数组长度进行位运算:(tab.length - 1) & hash。 5. 手写哈希表了解了上面的哈希知识之后,就可以自己写一个类似hashMap的数据结构了。 首先呢,我们先来想一下做一个哈希表的必要条件: 哈希函数哈希冲突方法只要牢记这两点,写出符合要求的数据结构即可: public class DiyHashMap{ private Object[] tables; private int size;public DiyHashMap() { size = 11; tables = new Object[size]; } public Object get(String key) { int index = hash(key) % size; if (tables[index] == null) { return null; } else { return tables[index]; } } public void put(String key, Object obj) { int index = hash(key) % size; tables[index] = obj; } private int hash(String key) { int hash = 0; for (int i = 0; i |
【本文地址】