| Hive(一) | 您所在的位置:网站首页 › 启动hive方式有什么和什么 › Hive(一) |
Hive(一)
|
一、基本概念
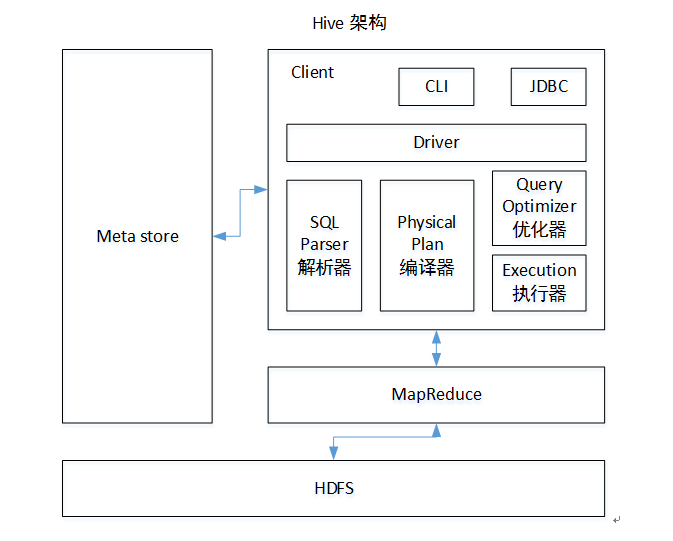
The Apache Hive™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax. Hive数据仓库软件,致力于解决读写、管理分布式存储中的大规模数据集,以及使用SQL语法进行查询的问题。 Hive用于解决海量结构化日志的数据统计问题。 Hive是基于Hadoop的一个数据仓库工具。本质是将HQL(Hive的查询语言)转化成MapReduce程序。 HIve处理的数据存储在HDFS HIve分析数据底层的默认实现是MapReduce 执行程序运行在Yarn上 Hive的优缺点优点: 可以快速进行数据分析,不需要写MapReduce程序。 MapReduce适合处理大数据,不适合处理小数据 缺点: HQL表达能力有限,迭代式算法不能表达,粒度较粗,调优比较困难。 自定义函数类别: UDF UDAF UDTF 架构原理
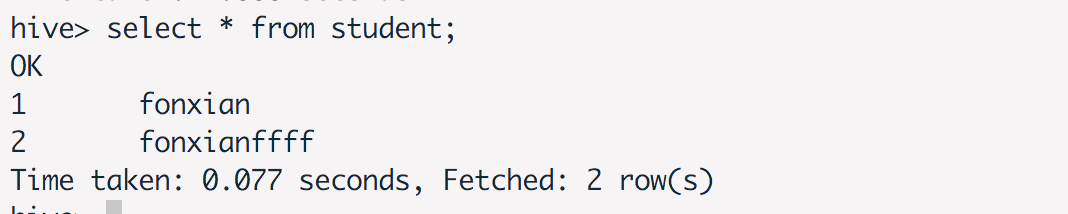
执行顺序:解析器-编译器-优化器-执行器 Hive与数据库对比HIve相比数据库,读多写少,没有索引,需要暴力扫描所有数据,即使引入了MapReduce机制,也不适合实时查询,扩展性和Hadoop的是一致的,扩展性强。 二、安装与启动下载hive-1.2.2 需要启动Hadoop的HDFS和Yarn 配置conf/hive-env.sh export HADOOP_HOME=/usr/local/hadoop(改成hadoop-home路径) export HIVE_CONF_DIR=/ur/local/hive/conf启动 bin/hive 三、Hive语句显示数据库 show databases;使用本地模式执行 hive> SET mapreduce.framework.name=local; 创建表、插入记录、查询记录 use default; #### 创建表 create table student(id int,name string); #### 插入记录 insert into table student values(1,'fonxian'); #### 查询记录 select * from student;
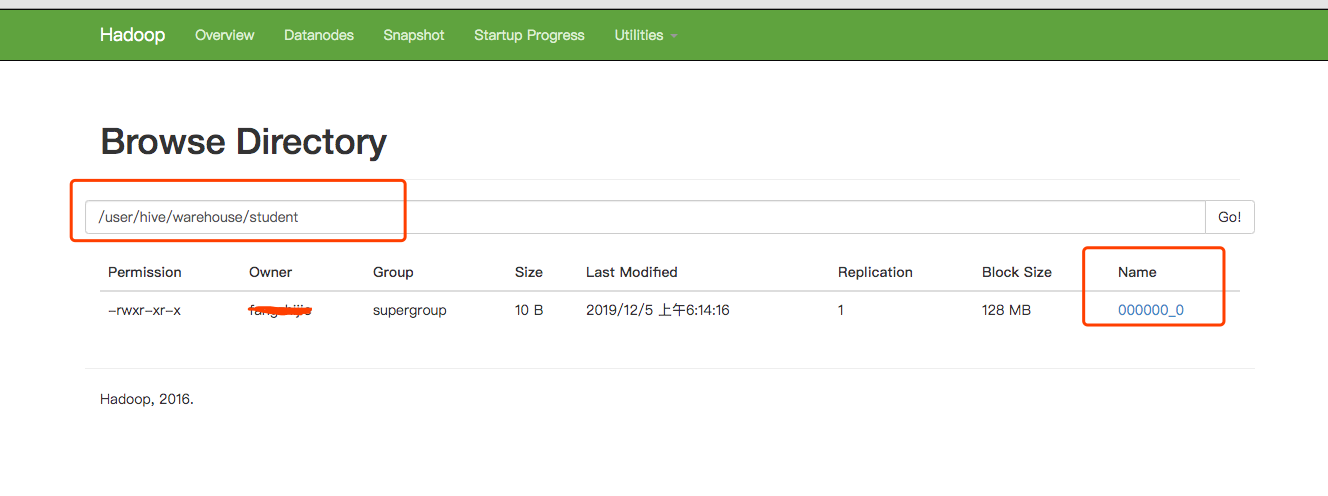
在Hadoop上查看记录
创建数据文本student.txt 3,kafka 4,flume 5,hbase 6,zookeeper创建表,定义分隔符 create table stu1(id int,name string) row format delimited fields terminated by ',';加载数据 load data local inpath '/usr/local/hive/data/student.txt' into table stu1;查看数据后的执行效果
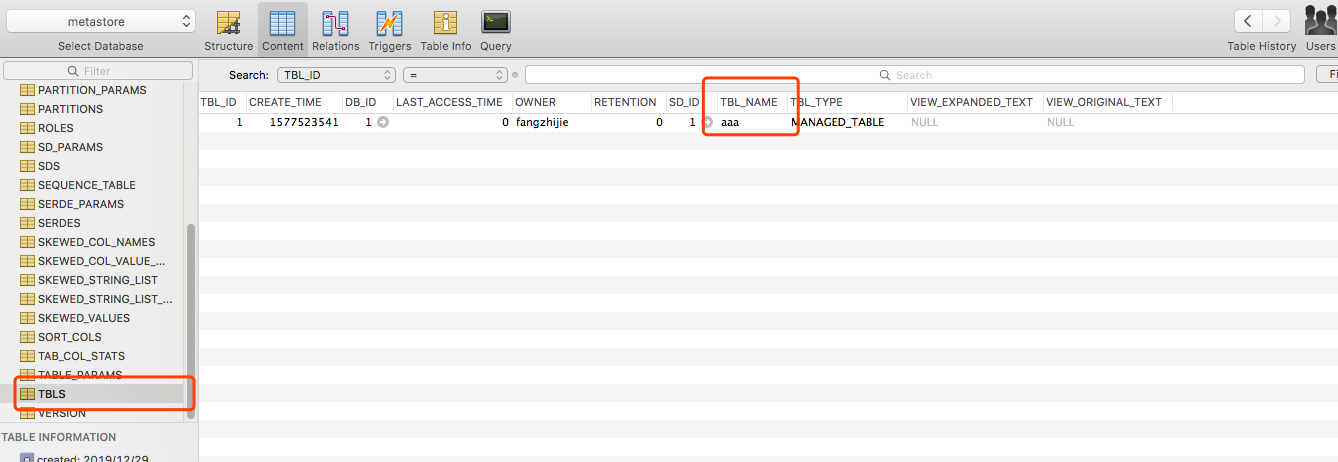
添加依赖 4.0.0 hive-hook-example Hive-hook-example 1.0 org.apache.hive hive-exec 1.1.0创建HiveExampleHook public class HiveExampleHook implements ExecuteWithHookContext { public void run(HookContext hookContext) throws Exception { System.out.println("operation name :" + hookContext.getQueryPlan().getOperationName()); System.out.println(hookContext.getQueryPlan().getQueryPlan()); System.out.println("Hello from the hook !!"); } }编译好,获得Hive-hook-example-1.0.jar hive> add jar Hive-hook-example-1.0.jar hive> set hive.exec.pre.hooks=HiveExampleHook; hive> select * from student; operation name :QUERY Query(queryId:fangzhijie_20191221231550_0e949bbf-f8f7-45a8-8726-c1cdd679cef9, queryType:null, queryAttributes:{queryString=select * from student}, queryCounters:null, stageGraph:Graph(nodeType:STAGE, roots:null, adjacencyList:null), stageList:null, done:false, started:true) Hello from the hook !! OK Time taken: 1.718 seconds Time taken: 1.68 seconds 五、使用MySQL存储元数据在本地安装mysql,创建hive-site.xml javax.jdo.option.ConnectionURL jdbc:mysql://127.0.0.1:3306/metastore?createDatabaseIfNotExist=true JDBC connect string for a JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName root username to use against metastore database javax.jdo.option.ConnectionPassword 123456 password to use against metastore database执行bin/hive,查看数据库,发现有创建表。 在hive中执行reate table aaa(id int);,HDFS中有创建该文件,且metastore的TBLS表中有记录。
HiveServer2 (introduced in Hive 0.11) has its own CLI called Beeline. HiveCLI is now deprecated in favor of Beeline, as it lacks the multi-user, security, and other capabilities of HiveServer2. To run HiveServer2 and Beeline from shell: HiveServer2有自己的客户端,叫Beeline。HiveCLI目前已经废弃了,建议使用Beeline。 使用Beeline连接HiveServer2 beeline -u "jdbc:hive2://host:port/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2" -n username -p password 七、报错信息解决&问题定位 修改配置不生效可能是配置路径的问题,查看hive-env.sh,最后发现hive配置路径写错。 错误的路径配置,导致根本找不到配置路径 export HIVE_CONF_DIR=/ur/local/hive/conf正确的配置 export HIVE_CONF_DIR=/usr/local/hive/conf 插入数据失败 hive> insert into table student values(1,'fonxian'); Query ID = fangzhijie_20191205061055_6c8c233e-2d46-470a-972d-38f36bb8068c Total jobs = 3 Launching Job 1 out of 3 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1575495654045_0004, Tracking URL = http://localhost:8088/proxy/application_1575495654045_0004/ Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1575495654045_0004 Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0 2019-12-05 06:10:58,803 Stage-1 map = 0%, reduce = 0% Ended Job = job_1575495654045_0004 with errors Error during job, obtaining debugging information... FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask MapReduce Jobs Launched: Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL Total MapReduce CPU Time Spent: 0 msec解决方法:执行下面的命令 hive> SET mapreduce.framework.name=local;分析: 参考官方文档 Hive compiler generates map-reduce jobs for most queries. These jobs are then submitted to the Map-Reduce cluster indicated by the variable: mapred.job.tracker Hive编译器 为大多数查询操作生成MR任务,这些任务之后会被提交到MR集群。 Hive fully supports local mode execution. To enable this, the user can enable the following option: Hive支持本地模式执行,用户可以使用下列操作: hive> SET mapreduce.framework.name=local; 参考文档Hive Getting Started 尚硅谷大数据课程之Hive hive-hook-example Beeline 官方文档 |

【本文地址】