| 【机器学习】数据归一化全方法总结:Max | 您所在的位置:网站首页 › 向量归一化处理公式 › 【机器学习】数据归一化全方法总结:Max |
【机器学习】数据归一化全方法总结:Max
|
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是常用的归一化方法: 一、Min-Max归一化(Min-Max Normalization)也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 – 1]之间。转换函数如下: x* = ( x − min ) / ( max − min ) 其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。 机器学习中MinMaxScaler将通过估计器分别缩放和转换每个元素成给定范围的值。(如:[0, 1]之间的值) 详细内容参考:https://blog.csdn.net/silent1cat/article/details/120072275 二、Z-score归一化(Z-Score normalization)这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为: x* = ( x − μ ) / σ 其中 μ为所有样本数据的均值,σ为所有样本数据的标准差。 三、Z-scores简单化模型如下: x* = 1 / ( 1 + x ) x 越大证明 x* 越小,这样就可以把很大的数规范在[0-1]之间了。 以上三种较为常见,其中1,2方法都需要依赖样本所有数据,而3方法只依赖当前数据,可以动态使用,比较好理解。 四、对数归一化(Logarithmic normalization)在实际工程中,经常会有类似点击次数/浏览次数的特征,这类特征是长尾分布的,可以将其用对数函数进行压缩。特别的,在特征相除时,可以用对数压缩之后的特征相减得到。对数规范化的常见形式是: 小数位归一化发生在具有数字类型的数据表中。如果你使用过 Excel,你就会知道这是如何发生的。默认情况下,Excel 会保留小数点后两位数字,也可以设定小数的位数,并在整个表格中进行统一。 六、数据类型归一化(Data type normalization)另一种常见是对数据类型的归一化。在 Excel 或 SQL 查询数据库中构建数据表时,可能会发现自己查看的数字数据有时被识别为货币,有时被识别为文本,有时被识别为数字,有时被识别为逗号分割的字符串。 问题是这些数值数据对公式和各种分析处理的操作是不一样的。所以就需要将它们统一成相同的类型。 七、格式的归一化(Formatting normalization)最后一个简单的技术是格式的归一化。这对于字符串(文本)是很常见的,并且在印刷和打印上出现的更多。虽然这些问题不会对分析产生影响,但是他可能会分散我们的注意力和现实的效果,例如斜体、粗体或下划线或者字体与其他的文字显示不一样。 八、三角函数归一化(Normalization of trigonometric functions)三角函数的值在[0, 1]之间,如果有需要,可以用三角函数进行变换。 三角函数归一公式为: f(x) = asinx + bcosx = √(a^2+b^2) 三角函数是以角度(数学上最常用弧度制)为自变量,角度对应任意角终边与单位圆交点坐标或其比值为因变量的函数。 常见的三角函数包括正弦函数、余弦函数和正切函数。在航海学、测绘学、工程学等其他学科中,还会用到如余切函数、正割函数、余割函数、正矢函数、余矢函数、半正矢函数、半余矢函数等其他的三角函数。 九、剪裁归一化(lipping normalization)裁剪并不完全是一种归一化技术,他其实是在使用归一化技术之前或之后使用的一个操作。简而言之,裁剪包括为数据集建立最大值和最小值,并将异常值重新限定为这个新的最大值或最小值。 例如有一个由数字 [14, 12, 19, 11, 15, 17, 18, 95] 组成的数据集。数字 95 是一个很大的异常值。我们可以通过重新分配新的最大值将其从数据中剔除。由于删除95后,数据集的范围是 11-19,因此可以将最大值重新分配为 19。最小值也同理 需要注意的是,裁剪不会从数据集中删除点,它只是重新计算数据中的统计值。 十、标准差归一化(Standard Deviation Normalization)假设我们的数据有五行 ,他们的ID 为 A、B、C、D 和 E,每行包含 n 个不同的变量(列)。我们在下面的计算中使用记录 E 作为示例。其余行以相同方式进行标准化。 第 i 列中 E 行的 ei 的归一化值计算如下:
当
如果E行的所有值都是相同的,那么E的标准差(std(E))等于0,那么E行的所有值都设为0。 哪些算法需要归一化1、涉及或隐含距离计算的算法,比如K-means、KNN、PCA、SVM等,一般需要进行归一化 2、梯度下降算法,梯度下降的收敛速度取决于:参数的初始位置到local minima的距离,以及学习率η的大小,其实还是距离的计算。 3、采用sigmoid等有饱和区的激活函数,如果输入分布范围很广,参数初始化时没有适配好,很容易直接陷入饱和区,导致梯度消失,所以才会出现各种BN,LN等算法。 哪些算法不需要归一化与距离计算无关的概率模型不需要,比如Naive Bayes; 与距离计算无关基于树的模型,比如决策树、随机森林等,树中节点的选择只关注当前特征在哪里切分对分类更好,即只在意特征内部的相对大小,而与特征间的相对大小无关。但是我们前几篇文章中说到了,使用Z-Score归一化会提高模型的准确率。其实归一化的作用就是由绝对变为了相对,所以可以说归一化对于树型模型不那么重要,是一个可选项或者说可以作为一个超参数在训练时进行选择。 参考文章:https://mp.weixin.qq.com/s?__biz=MzI1MjQ2OTQ3Ng==&mid=2247563527&idx=2&sn=2b754cbf718f240d47d5121b0e4fe795&chksm=e9e0f08cde97799af3752df8798b1660f6a90ea2a5c143b4fa244b66a7901b66f3a4fc2b0d0a&scene=27 https://blog.csdn.net/xinghuanmeiying/article/details/91873329 |
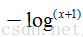 。
。 
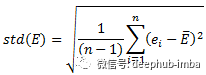
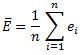
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |