| 【CNN可解释性】 | 您所在的位置:网站首页 › 可视化技术有哪些分类方法 › 【CNN可解释性】 |
【CNN可解释性】
|
缺点: 虽然借助反卷积和导向反向传播我们“看到”了CNN模型神秘的内部,但是却并不能拿来解释分类的结果,因为它们对类别并不敏感,直接把所有能提取的特征都展示出来了。 ref https://mp.weixin.qq.com/s/4Tq43DEaUk_rtLubcztyNw 类激活映射 CAMCAM:Learning Deep Features for Discriminative Localization 翻译 https://www.jianshu.com/p/1a207e7ca460 一个深层的卷积神经网络,通过层层卷积操作,提取空间和语义信息。一般存在其他更难理解的层,例如分类的全连接层、softmax层等,很难以利用可视化的方式展示出来。 所以,CAM的提取一般发生在卷积层,尤其是最后一层卷积。通常每一层的特征图还会有很多层,一般称为channel(通道),例如Resnet18最后一层特征图有512个通道。这512个通道可以认为提取到不同的特征,该特征具有高度抽象性,且每个通道对最后的结果贡献不同,单独可视化每个通道获取热图也让人很难理解。 所以一般CAM的获取是根据每个通道不同的贡献大小去融合获取一张CAM。 分类网络如VGGnet和Alexnet等基本由卷积操作对图片的特征进行提取,在网络末端使用全连接层进行信息综合和分类。在监督学习中,分类问题需要带类别标签的数据集,定位问题需要带BBox(BoundingBox)标签的数据集,分别计算预测与真值之间的loss并进行优化,达到网络训练的目的。而对于只提供分类标签的数据集,但需要完成分类和定位两个功能的网络训练时,就属于弱监督学习问题。 论文中提出,CNN网络中各卷积核除了提取特征外,其实本身已经具有物体检测功能,即使没有单独对物体的位置检测进行监督学习,而这种能力在使用全连接层进行分类的时候会丧失。通过使用GAP(global average pooling)替代全连接层,可以保持网络定位物体的能力,且相对于全连接网络而言参数更少。论文中提出一种CAM(Class Activation Mapping)方法,可以将CNN在分类时使用的分类依据(图中对应的类别特征)在原图的位置进行可视化,并绘制成热图,以此作为物体定位的依据。 全局平均池化层(GAP)和全局最大池化层(GMP)对比 GAP和GMP都是全局池化的方法,也有学者在做弱监督物体定位时采用了这两种方法,而文章之所以选择GAP有以下两个原因: GMP希望网络更关注物体的1个discriminaltive part,更关注物体的边缘识别,取最大的部分,而GAP则更希望网络识别物体的整个范围。在求平均值时,GAP可以综合并找到所有discriminaltive part来得到最大激活,对于低激活的区域就会减少特定输出,即GAP相对于GMP来说识别这个物体辨别性区域的损失更小。 GMP由于只取了区域最大值,所以其他低分的区域对最终分类的得分都不会有影响 通过在ILSVRC数据集上进行验证发现,GMP的分类性能和GAP相当,但GAP的定位能力强于GMP CNN网络做分类时之所以丢失了物体的位置信息,是因为网络末端使用了全连接层,通过使用GAP替代全连接层,从而使卷积网络的定位能力能延续到网络的最后一层(全局平均池化的技术不是本论文提出的,论文主要挖掘出GAP可以用于定位区别性区域的特点,即discriminative localization) 对AlexNet,我们移除conv5之后的卷积层(pool5到prob),得到图分辨率(mapping resolution)为13x13。对VGGnet,我们溢出了conv5-3后的所有卷积层(pool5到prob),得到14x14的图分辨率。对GoogLeNet,我们溢出了inception4e后的卷积层(pool4到prob),得到14x14的图分辨率。对上述的每个网络,我们都添加一个3x3,步长为1,padding为1,1024个单元的卷积层,然后接一个GAP层和一个softmax层。最后对每个网络在ILSVRC的1.3M张要分成1000类的训练图片进行精调(fine-tuned),分别产生我们最终的AlexNet-GAP,VGGnet-GAP和GoogLeNet-GAP。 作者将VGG、GoogleNet、AlexNet的最后几层去掉,一般是去掉的全连接层,然后作者加入33,stride为1,pad为1的卷积层,之后是1414的Average Pool层,然后就是softmax层,对这个新的网络进行fine-tuned。获取分类权重。 求CAM等到收敛之后,首先获取预测类别。 过程如下: 「step1」:提取需要可视化的特征层,例如尺寸为77512的张量; 「step2」:获取该张量对应预测类别的每个channel的权重,即长度为512的向量; 「step3」:通过线性融合的方式,将该张量在channel维度上加权求和,获取尺寸为7*7的map; 「step4」:对该map进行归一化,并通过插值的方式resize到原图尺寸; # 获取全连接层的权重 self._fc_weights = self.model._modules.get(fc_layer).weight.data # 获取目标类别的权重作为特征权重 weights=self._fc_weights[class_idx, :] # 这里self.hook_a为最后一层特征图的输出 batch_cams = (weights.unsqueeze(-1).unsqueeze(-1) * self.hook_a.squeeze(0)).sum(dim=0) # relu操作,去除负值 batch_cams = F.relu(batch_cams, inplace=True) # 归一化操作 batch_cams = self._normalize(batch_cams)CAM的实现需要将网络的全连接层替换为GAP(即卷积特征映射→全局平均池化→softmax层),一定程度上改变了原卷积网络的结构,所以适用性受到一些影响。 在CAM的基础上有人也提出了更泛化的版本Grad-CAM,这是一种使用梯度信号组合特征映射的方法,该方法不需要对网络架构进行任何修改,所以基本适用于所有的CNN结构得到网络,具体请见Grad-CAM论文《Visual Explanations from Deep Networks via Gradient-based Localization》。 类似目标检测领域 anchor-base和anchor-free, CAM也有两种不同的阵营gradient-based和gradient-free。做法不同,其本质类似: 「提取目标特征层,并进行加权融合获取激活图(CAM)。主要的区别在于上述step2叙述的特征层之间融合权重的选择上」。 Grad-CAMCAM有一个致使伤,就是它要求修改原模型的结构,导致需要重新训练该模型,这大大限制了它的使用场景。如果模型已经上线了,或着训练的成本非常高,我们几乎是不可能为了它重新训练的。于是乎,Grad-CAM横空出世,解决了这个问题。 其基本思路是目标特征图的融合权重可以表达为梯度。用梯度的全局平均来计算权重。事实上,经过严格的数学推导,Grad-CAM与CAM计算出来的权重是等价的。 另外,因为热图关心的是对分类有正面影响的特征,所以加上了relu以移除负值。 定义Grad-CAM中第k个特征图对类别c的权重如下: 求得类别对所有特征图的权重后,同CAM,求其加权和就可以得到热力图。 加入ReLU使得只关心对类别c有正影响的那些像素点,如果不加ReLU层,最终可能会带入一些属于其它类别的像素,从而影响解释的效果。 https://www.cnblogs.com/wanghui-garcia/p/14087162.html Grad-CAM是利用目标特征图的梯度求平均(GAP)获取特征图权重,可以看做梯度map上每一个元素的贡献是一样。 GRAD-CAM++认为梯度map上的「每一个元素的贡献不同」,因此增加了一个额外的权重对梯度map上的元素进行加权
moothGrad的做法也很简单,即为多次输入加入随机噪声的图片,对结果并求平均,用以消除输出saliency maps的"噪声",达到“引入噪声”来“消除噪声”的效果。核心公式如下:
本文摒弃了利用梯度获取特征权重的做法,作者认为: 对于深度神经网络,梯度可能是存在噪声的,并存在饱和问题。 利用Grad-CAM很容易找到错误置信度的样本,即具有更高权重的激活图对网络输出的贡献较小的例子。 因此本文提出了gradient-free的做法。首先,作者定义了CIC( (Increase of Confidence)的概念,既相对于baseline图片的置信度增量
Smoothed Score-CAM for Sharper Visual Feature Localization https://arxiv.org/pdf/2006.14255v1.pdf 本文和score-CAM的关系类似于smooth Grad-CAM++ 和 Grad-CAM++的关系。本文同样是利用了smoothGrad技术来降低输出噪声。关于smoothGrad平滑策略, 本文给出了两种做法,一种是噪声增加在特征图上,一种是噪声增加在输入图上。这两种做法在论文给出的不同数据集上的测试指标也互有高低,具体选择也依情况而定。
ref https://mp.weixin.qq.com/s/WKImrtpjQBziz6Wr5uOGNw LIMELIME是KDD 2016上一篇非常漂亮的论文,思路简洁明了,适用性广,理论上可以解释任何分类器给出的结果。 其核心思想是:对一个复杂的分类模型(黑盒),在局部拟合出一个简单的可解释模型,例如线性模型、决策树等等。这样说比较笼统,我们从论文中的一张示例图来解释:
一个看似复杂的模型通过我们巧妙的转换,就能够从局部上得到一个让人类理解的解释模型,光这样说还是显得有些空洞,具体来看看LIME在图像识别上的应用。我们希望LIME最好能生成和Grad-CAM一样的热力图解释。但是由于LIME不介入模型的内部,需要不断的扰动样本特征,这里所谓的样本特征就是指图片中一个一个的像素了。仔细一想就知道存在一个问题,LIME采样的特征空间太大的话,效率会非常低,而一张普通图片的像素少说也有上万个。若直接把每个像素视为一个特征,采样的空间过于庞大,严重影响效率;如果少采样一些,最终效果又会比较差。 所以针对图像任务使用LIME时还需要一些特别的技巧,也就是考虑图像的空间相关和连续的特性。不考虑一些极小特例的情况下,图片中的物体一般都是由一个或几个连续的像素块构成,所谓像素块是指具有相似纹理、颜色、亮度等特征的相邻像素构成的有一定视觉意义的不规则像素块,我们称之为超像素。相应的,将图片分割成一个个超像素的算法称为超像素分割算法,比较典型的有SLIC超像素分割算法还有quickshit等,这些算法在scikit-image库中都已经实现好了,quickshit分割后如图所示: 从特征的角度考虑,实际上就不再以单个像素为特征,而是以超像素为特征,整个图片的特征空间就小了很多,采样的过程也变的简单了许多。更具体的说,图像上的采样过程就是随机保留一部分超像素,隐藏另一部分超像素,如下所示:
虽然LIME方法虽然有着很强的通用性,效果也挺好,但是在速度上却远远不如Grad-CAM那些方法来的快。当然这也是可以理解的,毕竟LIME在采样完成后,每张采样出来的图片都要通过原模型预测一次结果。 AAAI 2018LIME作者的后续研究成果Anchors。Anchors指的是复杂模型在局部所呈现出来的很强的规则性的规律,注意和LIME的区别,LIME是在局部建立一个可理解的线性可分模型,而Anchors的目的是建立一套更精细的规则系统。不过看过论文以后感觉更多是在和文本相关的任务上有不错的表现,在图像相关的任务上并没有什么特别另人耳目一新的东西,只是说明了在Anchor(图像中指若干个超像素)固定的情况下,其他像素无论替换为什么,现有的模型都会罔顾人类常识,自信的做出错误判断。 Contrastive Learning of Class-agnostic Activation Map for Weakly Supervised Object Localization and Semantic Segmentation 时间:2022/03/25 方法:Contrastive Learning of Class-agnostic Activation Map(CCAM) 会议:CVPR 2022 Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation 时间:2022/03/02 方法:Class Re-Activation Map(ReCAM) 会议:CVPR 2022 REF https://mp.weixin.qq.com/s/4Tq43DEaUk_rtLubcztyNw https://github.com/jennalau/feature-vis-yolov3 https://zhuanlan.zhihu.com/p/395647673 |


 使用普通的反向传播得到的图像噪声较多,基本看不出模型的学到了什么东西。使用反卷积可以大概看清楚猫和狗的轮廓,但是有大量噪声在物体以外的位置上。导向反向传播基本上没有噪声,特征很明显的集中猫和狗的身体部位上。
使用普通的反向传播得到的图像噪声较多,基本看不出模型的学到了什么东西。使用反卷积可以大概看清楚猫和狗的轮廓,但是有大量噪声在物体以外的位置上。导向反向传播基本上没有噪声,特征很明显的集中猫和狗的身体部位上。
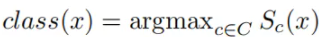 将卷积层每一通道乘以对应分类的连接权重,实现对特征图加权,就可以得到热力图class activation map
将卷积层每一通道乘以对应分类的连接权重,实现对特征图加权,就可以得到热力图class activation map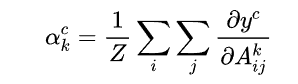 yc是对应类别c的分数(在代码中一般用logits表示,是输入softmax层之前的值
yc是对应类别c的分数(在代码中一般用logits表示,是输入softmax层之前的值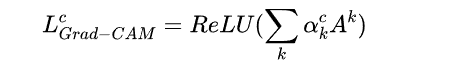

 这样就很好的解决了反卷积和导向反向传播对类别不敏感的问题。 Grad-CAM的神奇之处还不仅仅局限在对图片分类的解释上,任何与图像相关的深度学习任务,只要用到了CNN,就可以用Grad-CAM进行解释,如图像描述(Image Captioning),视觉问答(Visual Question Answering)等,所需要做的只不过是把y^c换为对应模型中的那个值即可。
这样就很好的解决了反卷积和导向反向传播对类别不敏感的问题。 Grad-CAM的神奇之处还不仅仅局限在对图片分类的解释上,任何与图像相关的深度学习任务,只要用到了CNN,就可以用Grad-CAM进行解释,如图像描述(Image Captioning),视觉问答(Visual Question Answering)等,所需要做的只不过是把y^c换为对应模型中的那个值即可。
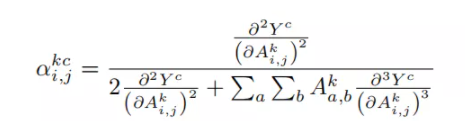

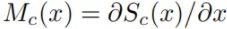 称之为saliency maps,表示x每个像素的微小变化会对类c的分类score产生多大的影响,如下图。
称之为saliency maps,表示x每个像素的微小变化会对类c的分类score产生多大的影响,如下图。 
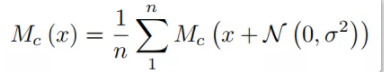 n为对原图增加噪声并前向的次数,N为高斯噪声。可以看到,随着的增加,噪声逐渐减少,saliency maps逐渐聚焦到目标物体区域
n为对原图增加噪声并前向的次数,N为高斯噪声。可以看到,随着的增加,噪声逐渐减少,saliency maps逐渐聚焦到目标物体区域  对原图多次增加高斯噪声,对目标类别对特征图的梯度求平均。
对原图多次增加高斯噪声,对目标类别对特征图的梯度求平均。
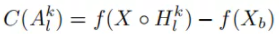

 对获取的特征图进行channel-wise遍历,对每层特征图进行上采样+归一化,与原始图片进行pixel-wise相乘融合,然后送进网络获取目标类别score(softmax后),减去baseline的目标类别score,获取CIC。再进行softmax操作来保证所有CIC之和为1。最后将CIC作为特征融合权重融合需要可视化的特征层。
对获取的特征图进行channel-wise遍历,对每层特征图进行上采样+归一化,与原始图片进行pixel-wise相乘融合,然后送进网络获取目标类别score(softmax后),减去baseline的目标类别score,获取CIC。再进行softmax操作来保证所有CIC之和为1。最后将CIC作为特征融合权重融合需要可视化的特征层。
 如图所示,红色和蓝色区域表示一个复杂的分类模型(黑盒),图中加粗的红色十字表示需要解释的样本,显然,我们很难从全局用一个可解释的模型(例如线性模型)去逼近拟合它。但是,当我们把关注点从全局放到局部时,可以看到在某些局部是可以用线性模型去拟合的。具体来说,我们从加粗的红色十字样本周围采样,所谓采样就是对原始样本的特征做一些扰动,将采样出的样本用分类模型分类并得到结果(红十字和蓝色点),同时根据采样样本与加粗红十字的距离赋予权重(权重以标志的大小表示)。虚线表示通过这些采样样本学到的局部可解释模型,在这个例子中就是一个简单的线性分类器。在此基础上,我们就可以依据这个局部的可解释模型对这个分类结果进行解释了。
如图所示,红色和蓝色区域表示一个复杂的分类模型(黑盒),图中加粗的红色十字表示需要解释的样本,显然,我们很难从全局用一个可解释的模型(例如线性模型)去逼近拟合它。但是,当我们把关注点从全局放到局部时,可以看到在某些局部是可以用线性模型去拟合的。具体来说,我们从加粗的红色十字样本周围采样,所谓采样就是对原始样本的特征做一些扰动,将采样出的样本用分类模型分类并得到结果(红十字和蓝色点),同时根据采样样本与加粗红十字的距离赋予权重(权重以标志的大小表示)。虚线表示通过这些采样样本学到的局部可解释模型,在这个例子中就是一个简单的线性分类器。在此基础上,我们就可以依据这个局部的可解释模型对这个分类结果进行解释了。
 从图中可以很直观的看出这么做的意义:找出对分类结果影响最大的几个超像素,也就是说模型仅通过这几个像素块就已经能够自信的做出预测。这里还涉及到一个特征选择的问题,毕竟我们不可能穷举特征空间所有可能的样本,所以需要在有限个样本中找出那些关键的超像素块。虽然这部分没有在论文中过多提及,但在LIME的代码实现中是一个重要部分,实现了前向搜索(forward selection)、Lasso和岭回归(ridge regression)等特征选择方式,默认当特征数小于等于6时采用前向搜索,其他情况采用岭回归。
从图中可以很直观的看出这么做的意义:找出对分类结果影响最大的几个超像素,也就是说模型仅通过这几个像素块就已经能够自信的做出预测。这里还涉及到一个特征选择的问题,毕竟我们不可能穷举特征空间所有可能的样本,所以需要在有限个样本中找出那些关键的超像素块。虽然这部分没有在论文中过多提及,但在LIME的代码实现中是一个重要部分,实现了前向搜索(forward selection)、Lasso和岭回归(ridge regression)等特征选择方式,默认当特征数小于等于6时采用前向搜索,其他情况采用岭回归。
 LIME除了能够对图像的分类结果进行解释外,还可以应用到自然语言处理的相关任务中,如主题分类、词性标注等。因为LIME本身的出发点就是模型无关的,具有广泛的适用性。
LIME除了能够对图像的分类结果进行解释外,还可以应用到自然语言处理的相关任务中,如主题分类、词性标注等。因为LIME本身的出发点就是模型无关的,具有广泛的适用性。【本文地址】