| 最清楚的 | 您所在的位置:网站首页 › 变量提升的原理和方法 › 最清楚的 |
最清楚的
|
本文尽量避免数学公式,使用文字解释列生成算法的原理,争取让读者能形成直观上的理解。 为什么需要了解列生成算法的原理 列生成算法无法简单地调用第三方库来使用,必须根据具体问题,构造不同的算法模型。只有了解了原理,才能在踩到各种坑时,有所针对地去优化各种细节。不然只能抓瞎或者抓腮。 列生成算法原理列生成算法可以从两个视角来理解:对偶角度和单纯形算法角度。 对偶角度啥是对偶 这里简单过一下对偶的概念。 假设有个长得很标准的线性规划问题:
那么,它的对偶问题为:
下面我们都以这个问题来讨论,即说到原问题时,默认是一个最小化问题;说到对偶问题时,默认是一个最大化问题。 怎么理解这个对偶关系呢?借用经济学方面的话来说,假设原问题的目标是让成本最小,那么对偶就是让收入最大。更确切地讲,是: 原问题丶:保证收入不低于某个值的条件下,使成本最小化。对偶问题:保证成本不高于某个值的条件下,使收入最大化。那个丶纯粹是为了对齐,忽略之…… 可以看到,原问题和对偶问题其实就是一个问题:目标净收益最大。只是一个是约束收入优化成本,一个是约束成本优化收入。角度不同而已。体现在公式上,就是原问题的变量对应对偶问题的约束,目标系数对应约束边界,约束矩阵倒转过来。
另外,关于对偶,一个比较重要的特性是:原问题的最优值与对偶问题的最优值相等。 从对偶角度看列生成算法 列生成算法主要用途在于求解变量多,但是大部分变量将会取值为0的线性规划问题。总体思路是先忽略大部分变量,构造一个只使用小部分变量的模型(其余变量相当于值为0),这样就能很快求出一个解。然后寻找模型外的变量,找到能够让目标值更优的变量,加入模型再次求解。重复这个过程直至找不到更好的变量。 这个过程的关键问题在于,怎么评估模型外的变量是否能让目标值更优。 我们从对偶的角度来研究这个问题。 原问题的变量对应对偶问题的约束。所以原问题新增变量,相当于对偶问题新增约束。 原问题新增变量 -> 对偶问题新增约束 由于对偶问题是个最大化问题,所以对偶问题新增约束后,显然最优值不变或变差,也就是不变或变小。从常理上看,约束越多,最优值越差嘛。 而前面提到的,原问题的最优值等于对偶问题的最优值。也就是说,如果对偶问题最优值不变,那么原问题最优值也不变;如果对偶问题最优值变小,那么原问题最优值也变小。而我们需要的正是让原问题的最优值变小。 所以问题变为如何尽量避免新增的约束没有改变最优值。设想一下,当加入新约束时,如果当前对偶的最优解没有违反新的约束,那么这个解仍然会是新增约束后的对偶问题的最优解,最优值将不变。 因此,我们要找的新增的约束,要和当前最优解冲突。 整条逻辑链为: 新增变量后原问题最优解变小 -> 新增约束后对偶问题最优解变小 -> 新增约束前的最优解不在新增约束后的可行域 -> 新增约束前的最优解不满足新增的约束 一行对偶问题的约束的公式为:
假设最优解为w*,那么违反约束的条件为:
变换一下,变成:
左侧的式子,叫做的reduced cost,也叫做检验数。 通过分析,我们知道,只要加入reduced cost小于0的对偶约束(从而加入了原问题对应的变量)即可。 很自然的想法是,我们更倾向于找到reduced cost最小的一个或几个变量加入,也就是最好能找到最小化reduced cost的新约束:
这里就出现了一个新的最优化问题。这个问题叫做列生成的子问题(sub problem)。其中w*是已知的,未知量是c和a。c和a是和问题的应用场景有关的,需要根据实际场景来构造c和a的约束条件。所以子问题无法通用地求解,只能根据具体问题选择不同的方法求解。 当所有未加入模型的变量的reduced cost都大于等于0时,目标值无法再优化,说明我们已得到最优解。 另外,熟悉对偶问题经济学含义的同学会知道,reduced cost是指产品的差额成本。那么显然要新增的是差额成本为负的产品了。这是另一种理解列生成的思路。 单纯形算法角度对偶角度给出了一个偏感性的方式来理解列生成算法。换个视角,从单纯形算法角度上看,则是单纯形算法本身,为了更高效地求解包含大量变量的问题,自然地扩展为列生成算法。 相信有不少人被单纯形算法虐得有心理阴影——公式复杂,手工计算量也巨大…… 其实,如果我们先不看细节,单纯形的核心原理并没有那么难以理解。下面讲解时不会很严谨,理解算法框架就够了。严谨的过程请参阅运筹学相关书籍。 单纯形算法 众所周知,单纯形算法有一个几何上的解释: 线性规划是一个凸优化问题,局部最优解就是全局最优解。线性规划的解空间是一个n维的凸多面体。最优解在这个凸多面体的某个顶点上。单纯形算法从一个初始顶点开始,不断沿着邻边找更好的顶点。当一个顶点四周没有更好的顶点时,这个顶点就是最优解。整个过程就像水沿着一条蜿蜒的沟渠流下,最终汇聚到最低点一样。 问题是,这里面的几何概念和代数公式怎么对应? 这里用不严谨(但更容易理解)的语言说明一下: 边界:解空间是由不等式约束(包括变量非负这些约束)围起来的一块空间区域。当点p使得若干个不等式取等号时,那么点p就在约束边界的超平面上。这个边界可能是一个面、边、顶点。顶点:顶点会让尽量多的约束取等号。也就是说,顶点是由若干个改为等号的约束组成的方程组的解。我们叫这个方程组为约束边界方程组。沿着边:约束边界方程组去掉一个方程,其解集就变成与顶点邻接的一条边。再取一条原方程组外的约束条件加入,所得到的解就是相邻的顶点。简单说,就是约束边界方程组中替换掉一个方程,形成的新方程组解出来就是相邻的顶点。这里涉及到通过让约束取等号来求边界的操作,而不等式乱糟糟地混在方程型的约束和变量非负约束里,会使这里的分析比较困难。所以使用单纯形算法之前,都会通过引入松弛变量、剩余变量和人工变量等方法(这一步在这里不重要,不详细展开了),将线性规划转换成如下标准形式:
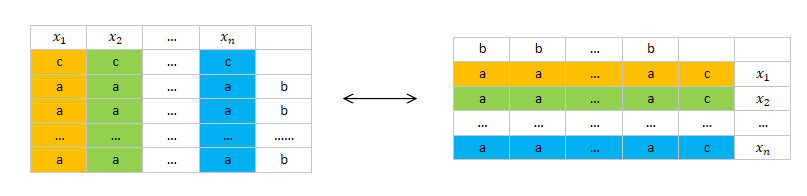
标准形式中只有变量非负约束包含不等式,其他约束都是等式。这样我们就可以很容易地做边界相关的计算了。假设变量数量为n,等式约束数量为m。通过转换而来的标准形式都会有n > m。那么,我们知道,只要让n-m个变量等于0,剩下的m个变量就可以通过这m个等式联立方程组(约束边界方程组)求出一个解(简单起见,不考虑无解,无数解这些边缘条件)。这个解就是一个顶点。 这里约束边界方程组中的m个变量叫作基变量,固定值为0的n-m个变量叫作非基变量。 沿着边找相邻顶点,就是取一个被固定为0的非负约束,也就是一个非基变量(这个操作叫入基),替换掉一个基变量(这个操作叫出基,这个变量出基后就固定值为0),然后重新求解一个顶点。 入基操作需要选择入基变量,选择的依据是这个变量在目标函数中的下降速度,也就是这个变量增加1时,目标值减少多少。经过推导可知,下降速度的计算公式刚好是检验数(reduced cost)。这里就和对偶的视角联系起来了。 出基操作这里就不细说了,大致的思路是在约束条件下,旧的基变量有一部分会随着入基变量的增长而下降,其中最先下降到0的旧的基变量就会被选为出基变量。 整个单纯形算法的计算步骤是: 选取基变量和非基变量,简单能出初始解就好。计算所有非基变量的reduced cost,找到最小且为负值的那个作为入基变量。如果reduced cost都大于等于0,迭代终止。选出基变量解约束边界方程组,回到步骤2从单纯形算法角度看列生成算法 在单纯形的步骤2,需要计算所有非基变量的RC。找到最小的那个。当变量个数很多的时候,这一步就成为了算法运行时间瓶颈。 在一些情况下,通过巧妙构造问题,可以让这一步不需要遍历所有变量。甚至我们都不需要知道有多少变量,只要能在每次迭代的时候生成一个或者多个变量,提升优化效果就可以了。 由于不需要遍历所有变量,所以一开始就不需要使用所有变量,只需要使用一组能产生初始解的初始变量构成线性优化问题即可。这种只使用部分变量的模型被称为原问题的restricted master problem(RMP)。 每次迭代时,生成一个或多个让reduced cost最小的变量加入RMP。这个生成步骤就是求解子问题。不断加入新变量直到没有小于0的reduced cost的变量时就达到最优解。 到这里就和对偶角度分析的结果一致了。 下面是单纯形算法与列生成算法简要流程图的对比,可以看到,两者的结构是一样的。
一般来说,我们不会手搓单纯形算法,所以正常都是直接调用单纯形算法库解RMP,然后做列生成,再跑RMP,直到达到最优。 一个经典例子:Cutting Stock Problem这是一个列生成算法的经典例子。
原纸卷每个长17m,顾客们分别需要25个3m长,20个5m长,18个7m长的纸卷。 问:如何切割使消耗的原纸卷数量最少? 令一个原纸卷的切割方案集合为: P = {(a, b, c) | 3a + 5b + 7c |

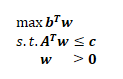

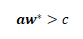
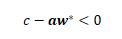
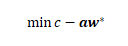
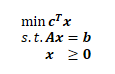


【本文地址】