| redis实现队列的几种方式(LPUSH/BRPOP,发布/订阅模式,stream) | 您所在的位置:网站首页 › 发布订阅模式的实现 › redis实现队列的几种方式(LPUSH/BRPOP,发布/订阅模式,stream) |
redis实现队列的几种方式(LPUSH/BRPOP,发布/订阅模式,stream)
|
前言
前面我们在redis学习笔记之基本5种数据结构中提到列表实现队列,我们今天就简单说下redis队列实现的几种方式。redis队列实现可以通过 基于List的 LPUSH+BRPOP 的实现, 基于Sorted-Set的实现,PUB/SUB(订阅/发布模式),stream,下面我们主要是说说list,发布订阅,stream这三个知识点,至于sorted-set (有序集合)我们后面再说。 队列(LPUSH/BRPOP)
redis中通过列表可以来实现队列具体操作可以下面操作 rpush/lpop或lpush/rpop实现简单队列 127.0.0.1:6379> lpush word a b c d (integer) 4 127.0.0.1:6379> llen word (integer) 4 127.0.0.1:6379> rpop word "a" 127.0.0.1:6379> rpop word "b" 127.0.0.1:6379> rpop word "c" 127.0.0.1:6379> rpop word "d" 127.0.0.1:6379> rpop word (nil) blpop或brpop实现阻塞读取队列 127.0.0.1:6379> rpush word a b c d (integer) 4 127.0.0.1:6379> blpop word 1 1) "word" 2) "a" 127.0.0.1:6379> blpop word 1 1) "word" 2) "b" 127.0.0.1:6379> blpop word 1 1) "word" 2) "c" 127.0.0.1:6379> blpop word 1 1) "word" 2) "d" 127.0.0.1:6379> blpop word 1 (nil) (1.09s) python实例在上面的rpush/lpop可以看出,如果没有队列没有数据的话,返回则为nil,所以在我们在写代码时候一般会加一个循环,代码如下: while True: msg = redis.rpop("queue") if msg is None: continue hadle_data(msg)这里存在一个问题就是:如果queue没有数据则一直存在rpop的操作,这样对客户端的cpu消耗和redis性能的浪费,所以我们可以暂时先考虑让msg为None的时候让他休息一秒,例子如下: while True: msg = redis.rpop("queue") if msg is None: time.sleep(1) continue hadle_data(msg)在优化之后,仔细仔细想下还是存在一个问题,那就是实时性存在问题了(有点像es近实时了),所以我们需要动动我们聪明的大脑来想想怎么解决。这时候我们就需要使用blpop(b指的是blocking,也就是阻塞读),这样没有数据来的时候会立即进入休眠状态,一旦数据来了,则立即激活,这样不但解决了性能的问题,也尽可能的解决了延迟的问题 while True: msg = redis.brpop("queue") if msg is None: continue hadle_data(msg)这里注意:一旦长时间没有来数据,服务端会主动断开连接,减少闲置资源的占用,这时候会抛出异常,所以我们需要加入捕捉异常,还要重试。 使用这种模型来实现队列存在两个比较致命的问题: 没有ack机制,消息丢了就丢了不能重复消费 发布订阅"发布/订阅"模式包含两种角色,分别是发布者和订阅者。订阅者可以订阅一个或者多个频道(channel),而发布者可以向指定的频道(channel)发送消息,所有订阅此频道的订阅者都会收到此消息。 简单版发布订阅 //订阅主题的客户端 127.0.0.1:6379> SUBSCRIBE python Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "python" 3) (integer) 1 //发布消息的客户端 127.0.0.1:6379> PUBLISH python HelloWorld (integer) 1 //订阅主题的客户端 127.0.0.1:6379> SUBSCRIBE python Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "python" 3) (integer) 1 1) "message" 2) "python" 3) "HelloWorld" 模式订阅 # 模式订阅 他会匹配stu. 满足的则接收到 127.0.0.1:6379> PSUBSCRIBE stu.* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "stu.*" 3) (integer) 1 1) "pmessage" 2) "stu.*" 3) "stu.name" 4) "linjian" 1) "pmessage" 2) "stu.*" 3) "stu.age" 4) "25" # 发布 127.0.0.1:6379> PUBLISH stu.name linjian (integer) 1 127.0.0.1:6379> PUBLISH stu.age 25 (integer) 1 python实例发布者 import redis client = redis.StrictRedis() client.publish("stu", "tom") client.publish("stu", "jack") client.publish("stu", "mary")订阅者 import time import redis client = redis.StrictRedis() p = client.pubsub() p.subscribe("stu") while True: msg = p.get_message() if not msg: time.sleep(1) continue print(msg) {'type': 'subscribe', 'pattern': None, 'channel': b'stu', 'data': 1} {'type': 'message', 'pattern': None, 'channel': b'stu', 'data': b'tom'} {'type': 'message', 'pattern': None, 'channel': b'stu', 'data': b'jack'} {'type': 'message', 'pattern': None, 'channel': b'stu', 'data': b'mary'}上面是python的简单事例,根据我们最开始的rpop的例子,我们可以敏锐的感觉的这里使用睡眠还是有不妥的,所以我接下来改成监听的模式 import redis client = redis.StrictRedis() p = client.pubsub() p.subscribe("stu") for msg in p.listen(): print(msg)这里我们不需要休眠,延迟的问题也不再是问题。 注意:redis发布订阅我们要先订阅主题,再向主题发布消息,反之订阅端会丢失订阅之前的数据 redis发布订阅不会持久化所以reids宕机就是引起数据丢失,在订阅也消费不到,所以在redis5.0引进了stream数据结构。 streamredis5.0后才有的新的数据结构,redis作者借鉴kafka设计出来一种新的强大的支持多播的可持久化的消息队列。 增删改查基本操作指令如下: xadd: 追加信息;xdel: 删除信息;这里的删除是设置标志位,不影响消息总长度xrange: 获取stream的消息列表(会过滤已经删除的信息)xlen: 获取信息长度del: 删除整个stream消息列表的种的所有信息(不会删除信息,只是给消息做个标记位)xread: 可以将stream当作队列来使用,xread可以从队列中获取消息 127.0.0.1:6379[1]> xadd stream_key * filed 1 "1618239631638-0" 127.0.0.1:6379[1]> xadd stream_key * filed 2 "1618239634713-0"xadd语法:XADD key ID field string [field string ...] 这里的*代表有服务器自动生成ID, 后面是key, val结构。返回的信息是由毫秒时间戳+序列号组成 127.0.0.1:6379[1]> xrange stream_key - + 1) 1) "1618239631638-0" 2) 1) "filed" 2) "1" 2) 1) "1618239634713-0" 2) 1) "filed" 2) "2" 127.0.0.1:6379[1]> xrange stream_key 1618239631638-0 + 1) 1) "1618239631638-0" 2) 1) "filed" 2) "1" 2) 1) "1618239634713-0" 2) 1) "filed" 2) "2"xrange语法: XRANGE key start end [COUNT count] - 代表最小值, +代表最大值 127.0.0.1:6379[1]> XLEN stream_key (integer) 2 127.0.0.1:6379[1]> XDEL stream_key 1618239634713-0 (integer) 1 127.0.0.1:6379[1]> XLEN stream_key (integer) 1 127.0.0.1:6379[1]> xrange stream_key - + 1) 1) "1618239631638-0" 2) 1) "filed" 2) "1"发现执行xrange没有返回被删除的信息,长度减少了1 xread : XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] I # 0 从头开始 127.0.0.1:6379> XREAD streams stu 0 1) 1) "stu" 2) 1) 1) "1619247923630-0" 2) 1) "name" 2) "zs" 2) 1) "1619247923630-1" 2) 1) "name" 2) "ls" 3) 1) "1619247923630-2" 2) 1) "name" 2) "ww" 4) 1) "1619247923630-3" 2) 1) "name" 2) "lj" # block 阻塞 1000000 毫秒 $最新开始读 127.0.0.1:6379> XREAD block 1000000 streams stu $ 1) 1) "stu" 2) 1) 1) "1619265214984-0" 2) 1) "name" 2) "1" (25.48s)注意: 如果是默认redis生成消息id,那么消息ID由两部分组成:时间戳-序号 消费组模式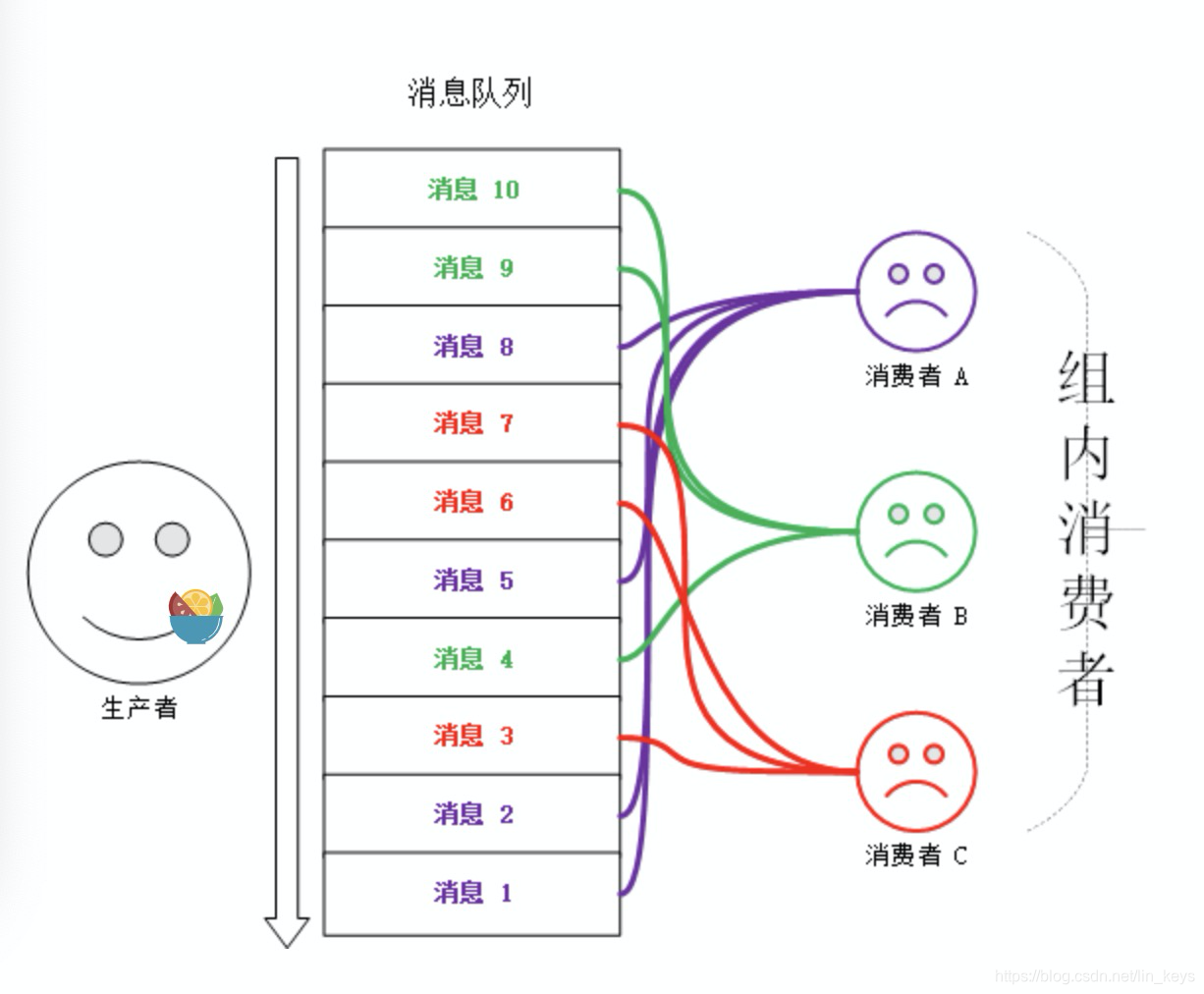 此图来源
https://zhuanlan.zhihu.com/p/60501638
此图来源
https://zhuanlan.zhihu.com/p/60501638
创建消费组 # 这里0表示从头开始消费, $表示从尾部开始消费,只接受最新的消息 127.0.0.1:6379> XGROUP create stu stuGroup1 0 OK 127.0.0.1:6379> XGROUP create stu stuGroup2 0 OK # 查看stream信息 127.0.0.1:6379> XINFO stream stu 1) "length" # 数据长度 2) (integer) 5 3) "radix-tree-keys" 4) (integer) 1 5) "radix-tree-nodes" 6) (integer) 2 7) "groups" # 两个消费组 8) (integer) 2 9) "last-generated-id" # 即本组中已发送的最大信息 10) "1619247923630-4" 11) "first-entry" # 第一个消息 12) 1) "1619247923630-0" 2) 1) "name" 2) "zs" 13) "last-entry" # 最后一个消息 14) 1) "1619247923630-4" 2) 1) "name" 2) "xm" # 获取stream 的消费组信息 127.0.0.1:6379> xinfo groups stu 1) 1) "name" # 消费组名 2) "stuGroup1" 3) "consumers" # 该消费组的消费者 4) (integer) 0 5) "pending" # 正在处理的消息 6) (integer) 0 7) "last-delivered-id" 8) "0-0" 2) 1) "name" 2) "stuGroup2" 3) "consumers" 4) (integer) 0 5) "pending" 6) (integer) 0 7) "last-delivered-id" 8) "0-0"XGROUP create stu stuGroup1 0 用于在消息队列stu上创建一个名字为stuGroup1消费组 。0表示该组从第一条消息开始消费。XGROUP除了支持CREATE外,还支持SETID设置起始ID,DESTROY销毁组,DELCONSUMER删除组内消费者等操作。 开始消费 # 消费者a消费第一条数据 127.0.0.1:6379> XREADGROUP group stuGroup1 a count 1 streams stu > 1) 1) "stu" 2) 1) 1) "1619247923630-0" 2) 1) "name" 2) "zs" # 消费者a1消费第2-4条数据 (count 3 消费三条数据) 127.0.0.1:6379> XREADGROUP group stuGroup1 a1 count 3 streams stu > 1) 1) "stu" 2) 1) 1) "1619247923630-1" 2) 1) "name" 2) "ls" 2) 1) "1619247923630-2" 2) 1) "name" 2) "ww" 3) 1) "1619247923630-3" 2) 1) "name" 2) "lj" # 消费者a1消费第5条数据 127.0.0.1:6379> XREADGROUP group stuGroup1 a2 count 3 streams stu > 1) 1) "stu" 2) 1) 1) "1619247923630-4" 2) 1) "name" 2) "xm" # 查看stream信息 发现stuGroup1 等待处理已经有五条了(这是因为我们没有执行ack) 127.0.0.1:6379> XINFO groups stu 1) 1) "name" 2) "stuGroup1" 3) "consumers" 4) (integer) 3 5) "pending" 6) (integer) 5 7) "last-delivered-id" 8) "1619247923630-4" 2) 1) "name" 2) "stuGroup2" 3) "consumers" 4) (integer) 1 5) "pending" 6) (integer) 1 7) "last-delivered-id" 8) "1619247923630-0"XREADGROUP group stuGroup1 a count 1 streams stu > 用于组stuGroup1内消费者a在队列stu中消费,参数>表示未被组内消费的起始消息,参数count 1表示获取一条。语法与XREAD基本一致,不过是增加了组的概念。 查询pending 127.0.0.1:6379> XPENDING stu stuGroup1 1) (integer) 5 # 已读取但未处理的消息 2) "1619247923630-0" # 开始id 3) "1619247923630-4" # 结束ID 4) 1) 1) "a" # 消费者 2) "1" # 未处理的消息数量 2) 1) "a1" 2) "3" 3) 1) "a2" 2) "1" # 我们也可以查看某个消费者在peding中详细信息 127.0.0.1:6379> XPENDING stu stuGroup1 - + 5 a 1) 1) "1619247923630-0" # 消息ID 2) "a" # 消费者 3) (integer) 1263223 # 已读取时长 4) (integer) 1 # 被读次数从上面我们可以看出,之前读取的消息都没有处理,都被记录在Pending列表中。有了这样一个Pending机制,就意味着在某个消费者读取消息但未处理后,消息是不会丢失的。等待消费者再次上线后,可以读取该Pending列表,就可以继续处理该消息了,保证消息的有序和不丢失。 告知消息处理完成 127.0.0.1:6379> XACK stu stuGroup1 1619247923630-0 (integer) 1 127.0.0.1:6379> XPENDING stu stuGroup1 1) (integer) 4 2) "1619247923630-1" 3) "1619247923630-4" 4) 1) 1) "a1" 2) "3" 2) 1) "a2" 2) "1"如果消费者不在线,那么他对应的消息怎么办,总不能一直放在队列里面,所以stream提供了转移的功能 消息转移 # 查看PEL的信息 127.0.0.1:6379> XPENDING stu stuGroup1 - + 10 1) 1) "1619247923630-1" 2) "a1" 3) (integer) 16891936 4) (integer) 1 2) 1) "1619247923630-2" 2) "a1" 3) (integer) 16891936 4) (integer) 1 3) 1) "1619247923630-3" 2) "a1" 3) (integer) 16891936 4) (integer) 1 4) 1) "1619247923630-4" 2) "a1" 3) (integer) 2868297 4) (integer) 2 5) 1) "1619265214984-0" 2) "a2" 3) (integer) 29221 4) (integer) 1 # 将a2的信息转给a1 127.0.0.1:6379> XCLAIM stu stuGroup1 a1 10 1619265214984-0 1) 1) "1619265214984-0" 2) 1) "name" 2) "1" 127.0.0.1:6379> XPENDING stu stuGroup1 - + 10 1) 1) "1619247923630-1" 2) "a1" 3) (integer) 16959519 4) (integer) 1 2) 1) "1619247923630-2" 2) "a1" 3) (integer) 16959519 4) (integer) 1 3) 1) "1619247923630-3" 2) "a1" 3) (integer) 16959519 4) (integer) 1 4) 1) "1619247923630-4" 2) "a1" 3) (integer) 2935880 4) (integer) 2 5) 1) "1619265214984-0" 2) "a1" 3) (integer) 2086 4) (integer) 2上面完成了a2消息转移给a1,除了要指定ID外,还需要指定IDLE,保证是长时间未处理的才被转移。被转移的消息的IDLE会被重置,用以保证不会被重复转移,以为可能会出现将过期的消息同时转移给多个消费者的并发操作,设置了IDLE,则可以避免后面的转移不会成功,因为IDLE不满足条件。 消息如果忘记ack怎么样Stream在每个消费者结构中保存了正在处理中的消息ID列表PEL,如果消费者收到了消息处理完了但是没有回复ack,就会导致PEL列表不断增长,如果有很多消费组的话,那么这个PEL占用的内存就会放大。如果一个消息不能被消费者处理,也就是不能被XACK,这是要长时间处于Pending列表中,即使被反复的转移给各个消费者也是如此。此时该消息的delivery counter就会累加,当累加到某个我们预设的临界值时,我们就认为是坏消息(也叫死信,DeadLetter,无法投递的消息),由于有了判定条件,我们将坏消息处理掉即可,删除即可 消息堆积时,Stream 是怎么处理 127.0.0.1:6379> XADD animal MAXLEN 10000 * name dog "1619267908579-0"在发布消息时,你可以指定队列的最大长度,防止队列积压导致内存爆炸。当队列长度超过上限后,旧消息会被删除,只保留固定长度的新消息。 三者区别
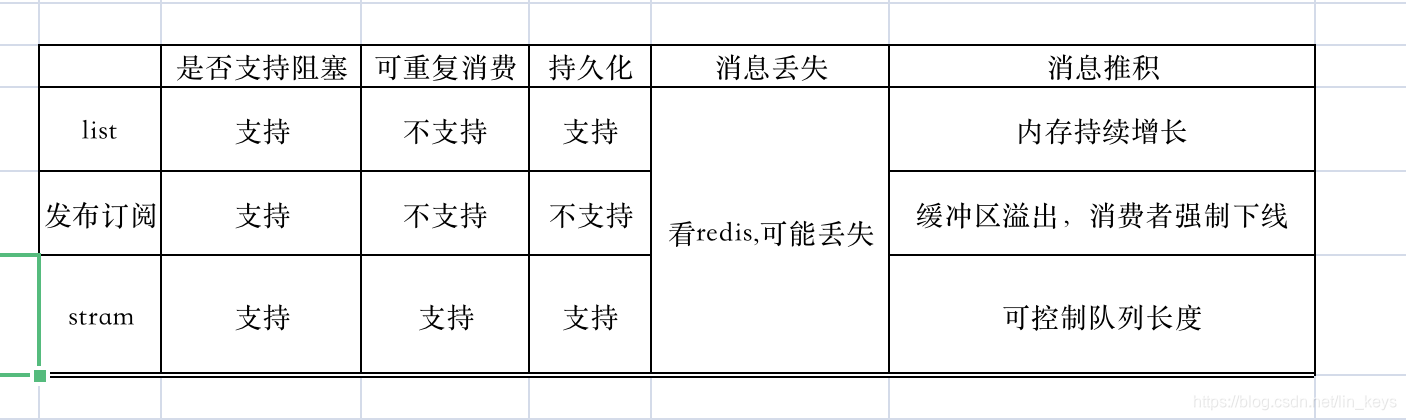
Stream 是基于 RadixTree 实现的,可以了解下 官方文档 如何看待Redis5.0的新特性stream? 把Redis当作队列来用,真的合适吗? |

【本文地址】