| 图解数据结构:数组和单链表 | 您所在的位置:网站首页 › 单链表后继节点是什么结构 › 图解数据结构:数组和单链表 |
图解数据结构:数组和单链表
|
前言
数据结构始终是计算机科学绕不开的话题,是计算机中存储、组织数据的方式。学习数据结构能让我们明白,如何更高效的存、取数据。编写程序的目的就是为了处理数据,处理数据本质上就是存、取、运算。 本篇从最简单的数据结构入手,讲解数组和链表。主要讲解他们的特点、存储结构、区别、各种场景下的效率等问题。 数组在计算机科学中,数组数据结构(英语:array data structure),简称数组(英语:Array),是由相同类型的元素(element)的集合所组成的数据结构,分配一块连续的内存来存储。利用元素的索引(index)可以计算出该元素对应的存储地址。 数组可以说是最常见的数据结构之一了,主要特点是 能存储一系列相同类型的元素所有元素用一块连续的内存来存储利用元素的索引可以直接访问对应的数据数组是静态结构,初始化必须指定容量,且容量不变 Object[] arr = new Object[10];是最常见定义数组的方式,如果要访问索引为1的数据,直接通过arr[1]即可访问。也就是说数组支持随机访问(RandomAccess)。第一次听到“随机访问”这个词的时候非常懵逼:既然是随机,那就表示不确定,也就是说没人知道程序会访问哪个数据,那怎么保证访问的就是程序需要的数据呢?后来才知道:这个随机访问(RandomAccess)倒不如翻译成“任意访问”,就是想访问哪个数据,就可以直接访问。数组就是这样,只需要给定下标就可以直接访问。 说数组是静态结构,容量不能变。可能有同学不理解了,ArrayList底层就是数组,但是ArrayList是可以自动扩容的。既然这样,那我就用数组手动实现简易版的ArrayList吧,简易的实现了ArrayList的核心功能,先来看下定义 /** * 动态数组实现ArrayList */ public class ArrayList { /** * 默认容量 */ private static final int DEFAULT_CAPACITY = 10; /** * 扩容倍数 */ private static final int RESIZE_RATE = 2; private E[] table; private int size; }E[] table用来保存添加的元素,int size用来记录ArrayList中元素的个数。需要注意的是,size和容量并不一定相等,容量是table.length,也就是数组长度。 再来看两个核心方法add(...)和remove()的实现思想,首先看下add(...)方法,往指定的位置插入元素,插入过程如下 其中第11至14行代码是size == table.length的情况,也就是数组满了的时候,再新增元素时,需要先扩容。扩容的逻辑也简单:重新创建一个更大容量的数组,再把当前数组的元素一个个拷贝过去,扩容过程如下 只需要传递一个参数,就是新容量。这个新容量不一定是大于size的,也可以小于size,也就是缩容操作。 以上两个主要方法就是动态数组的实现原理,也就是ArrayList的实现原理。这样就解释了:数组是静态的,实例化后不能改变其容量大小,但是ArrayList却是可以自动扩容的。 知道了add(...)的实现原理后,再来看看remove()方法实现原理。其实现过程如下 第18至20行,是判断当前元素的个数(size)只有数组容量的1/4时,把数组的容量减小为原来的一半,也就是缩容。 至此,数组的增、删、改、查四大功能已经完成了两个,剩下的两个比较简单,就直接给出代码。 数组的修改代码 /** * 替换指定位置元素 * @param index 下标 * @param e */ public void replace(int index, E e) { if (index < 0 || index >= size) { throw new IllegalArgumentException("illegal index, max " + size + " min 0 but index is " + index); } table[index] = e; }该方法时间复杂度为O(1),因为是根据下标直接设置,不需要其他的操作; 数组的查找代码 /** * 查找某个元素的下标 * @param e 指定元素 * @return 该元素的下标 -1 表示不存在该元素 */ public int indexOf(E e) { for (int i = 0; i < size; i++) { if (e.equals(table[i])) { return i; } } return -1; }该方法时间复杂度为O(n),因为不知道下标,只能遍历查找。对于数组的查找,如果已知下标,便可以直接根据下标取到对应的元素table[index],此时时间复杂度就为O(1)。 以上便是利用动态数组实现ArrayList的基本功能。以上完整代码的下载地址: Github:ArrayList.java CSDN:ArrayList.java 链表链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。 使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。 链表有很多种:单向链表,双向链表以及循环链表。先从最简单的单向链表开始,其主要特点是 是一种线性结构(和数组一样)每个节点存储下一个节点的指针(而数组是根据下标访问)是一种动态数据结构,不需要预先设置大小不支持随机访问(Random Access)
因为每个节点至多只能有一个前驱节点和一个后继节点,所以链表是线性结构。由于链表依靠指针相互连接,可以无限扩展,不需要预先设置链表的大小。又由于链表没有下标,所以不支持随机访问,只能通过指针进行遍历访问。 同样,利用单链表实现一个简易的LinkedList,同样完成链表的增、删、改、查四大操作。 在操作单链表时,有一个常用的小技巧,就是给单链表设置一个虚拟的头结点,这样在增加、删除真正的头结点时,就不需要进行特殊处理,把真正的头节点当成是普通节点来处理。以下是带虚拟头节点的单链表: 首先看看核心方法add(...)的实现原理。比如要把节点F插入索引为2的位置,也就是节点B、C之间。执行步骤分为三步: 找到索引为2的节点的前驱节点prev(从dummyHead虚拟头节点开始,依次遍历访问)将要插入的节点的next指向prev的next将prev的next指向要插入的节点
根据算法可知,往单链表中的任意位置插入元素,时间复杂度是O(n),因为需要从头节点开始,遍历才能找到插入的位置。但是如果是在头节点插入的话(即index参数传入0),就不需要遍历查找,时间复杂度就是O(1)。 实现了单链表的插入,再来实现单链表节点的删除。 假设要删除索引为2的节点,也就是F节点,也分为三个步骤 从dummyHead开始,依次遍历,找到要删除的节点的前驱节点prev,并且记录下要删除的节点result,用于返回值使prev节点的next指向result的next使result节点的next为null,完全脱离链表
从代码可以看到,单链表删除任意节点的时间复杂度为O(n),原因同样是因为需要遍历找到要删除的节点。如果删除的是头节点(index参数传入0),则时间复杂度为O(1)。所以单链表对头部进行增、删操作时,效率最高。 对链表的修改和查询操作比较简单,直接给出代码 修改链表特定节点的值 public boolean set(int index, E e) { if (index < 0 || index >= size) { throw new IllegalArgumentException("illegal index"); } Node curr = dummyHead.next; for (int i = 0; i < index; i++) { curr = curr.next; } curr.e = e; return true; }基本思路也是遍历查找需要修改的节点,再修改。单链表修改任意节点的时间复杂度为O(n)。如果修改的是头节点(index参数传入0),则时间复杂度为O(1)。 查询链表中是否包含某个元素 public boolean contains(E e) { Node curr = dummyHead.next; while (curr != null) { if (e.equals(curr.e)) { return true; } curr = curr.next; } return false; }同样也是遍历查询。 综合链表的增、删、改、查操作可以知道,对单链表的任意节点的的操作,时间复杂度都是O(n),但是对头节点的任意操作时间复杂度都是O(1)。 以上便是利用单链表实现LinkedList的基本功能。需要注意的是,JDK提供的LinkedList并不是单链表实现的。以上完整代码的下载地址: Github:LinkedList.java CSDN:LinkedList.java 学习了单链表的后,再学习更加复杂的双向链表、循环链表就相对容易一些。 总结本篇主要讲解数组和链表的区别,并用它们手动实现了ArrayList和LinkedList的基本功能。以下是二者在操作上的时间复杂度汇总比较,让大家有个更清晰地对比。 对数组而言: 在头部或中部进行增、删操作,时间复杂度是O(n),因为要移动元素。在尾部进行增、删操作,时间复杂度为O(1),最坏时间复杂度是O(n)。改、查操作如果已知下标,时间复杂度为O(1);未知下标,时间复杂度为O(n)。对于(只有一个头指针的)单链表而言: 在头部进行增、删、改、查操作时间复杂度都是O(1)。在其余部位进行增、删、改、查操作时间复杂度都是O(n)。以上便是数据结构中最简单的两种数据结构,他们都是线性结构。但是数组是静态数据结构;链表是动态数据结构。根据他们的性质,开发者便可以在适当的场景,选用不同的数据结构。 |
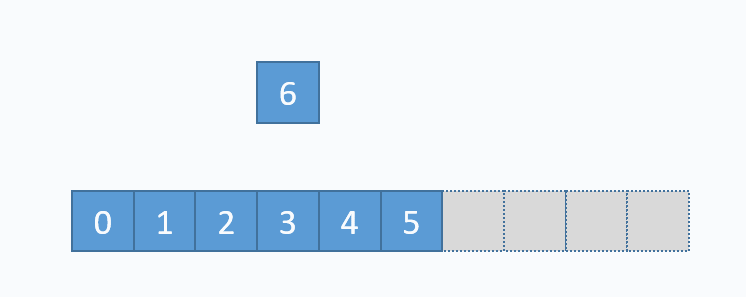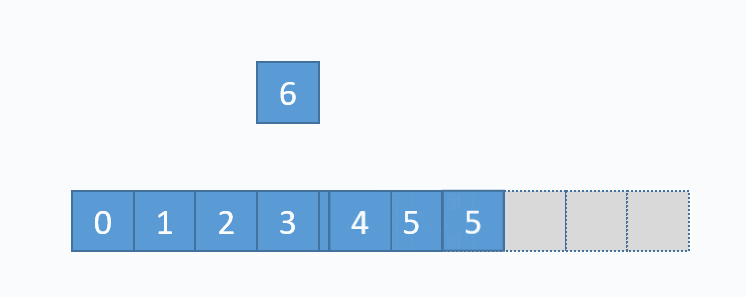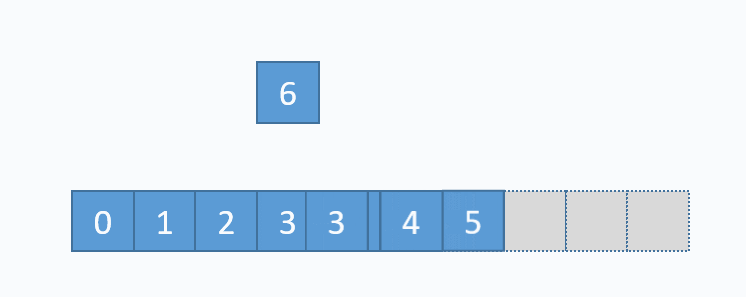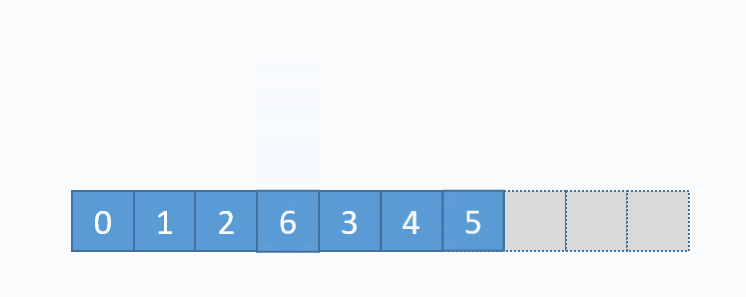 动画演示的是:把元素6插入下标为3的位置。在插入之前,必须先把下标3及以后的元素向后移动一格。并且必须按照下标递减的顺序来先后移动元素,避免元素被覆盖。 从图中便可以看出,向数组中间插入元素,时间复杂度是O(n),因为需要移动元素。但是向数组尾部插入元素,便不需要移动元素,所以时间复杂度为O(1)。由于向数组尾部插入元素有可能导致扩容操作(下面详细介绍),而扩容操作的时间复杂度为O(n),所以向数组尾部插入元素的最坏时间复杂度为O(n)。下面的代码是该逻辑的实现。
动画演示的是:把元素6插入下标为3的位置。在插入之前,必须先把下标3及以后的元素向后移动一格。并且必须按照下标递减的顺序来先后移动元素,避免元素被覆盖。 从图中便可以看出,向数组中间插入元素,时间复杂度是O(n),因为需要移动元素。但是向数组尾部插入元素,便不需要移动元素,所以时间复杂度为O(1)。由于向数组尾部插入元素有可能导致扩容操作(下面详细介绍),而扩容操作的时间复杂度为O(n),所以向数组尾部插入元素的最坏时间复杂度为O(n)。下面的代码是该逻辑的实现。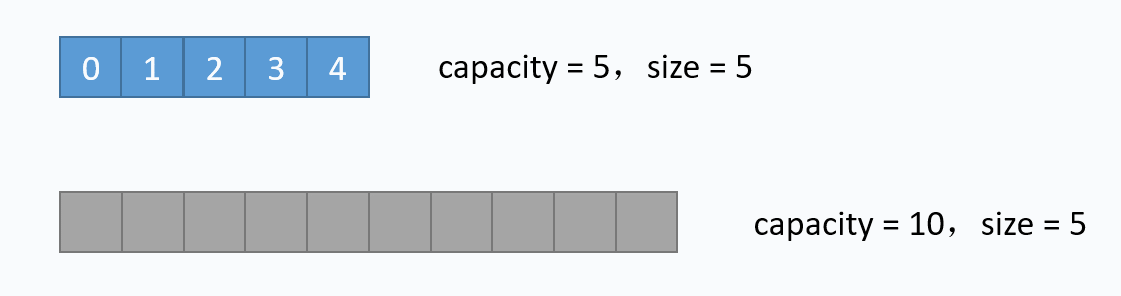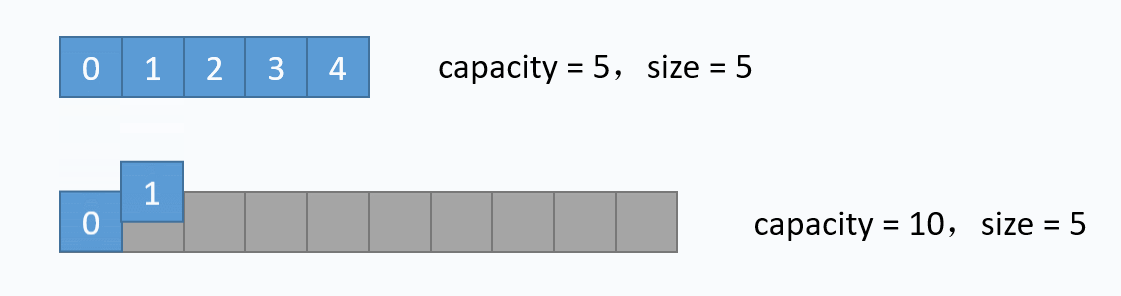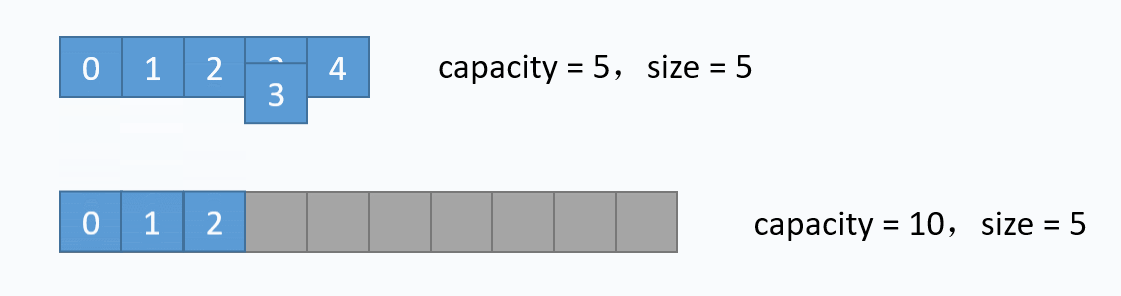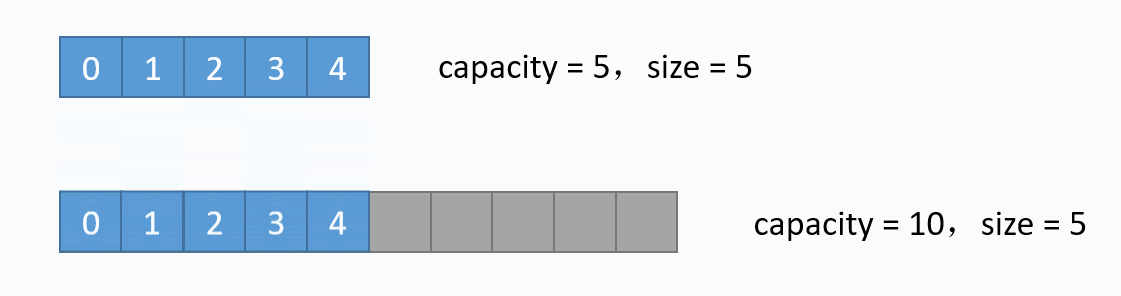 对应的代码实现如下:
对应的代码实现如下: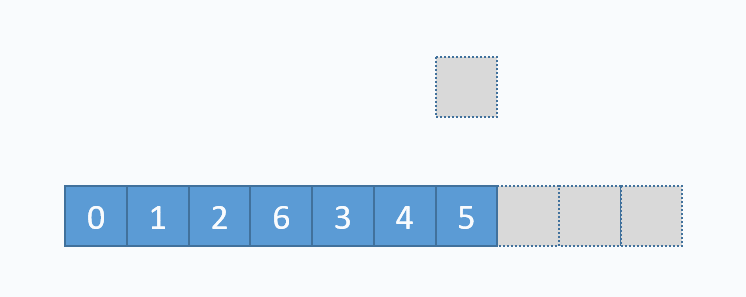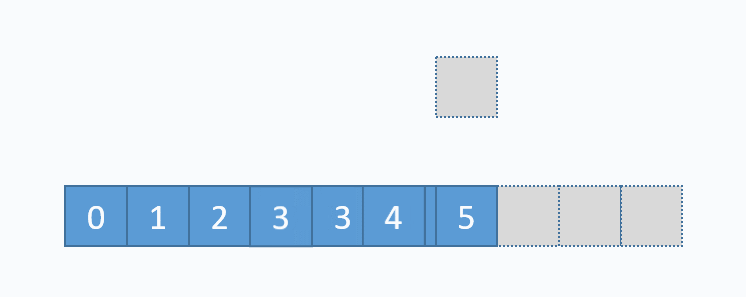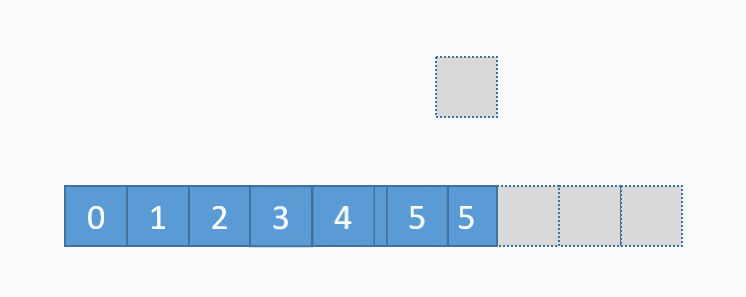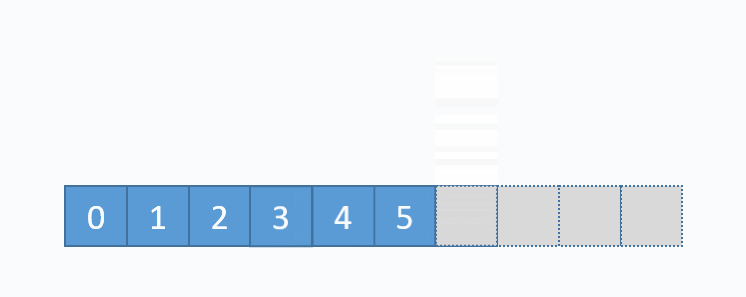 动图演示的是,删除下标为3的元素,也就是6。先从要删除的下标开始,把每一个元素都向前移动一格,再把最后一个元素重置(非必须,但是更合理)。从图中可以看出,删除数组中任意元素,需要移动该位置之后的所有元素,所以时间复杂度为O(n),但是删除尾部元素不需要移动元素,所以时间复杂度为O(1)。和add(...)方法一样,删除尾部元素也有可能导致缩容操作,缩容操作是的时间复杂度为O(n),所以删除尾部元素最坏时间复杂度为O(n),其对应的代码实现如下
动图演示的是,删除下标为3的元素,也就是6。先从要删除的下标开始,把每一个元素都向前移动一格,再把最后一个元素重置(非必须,但是更合理)。从图中可以看出,删除数组中任意元素,需要移动该位置之后的所有元素,所以时间复杂度为O(n),但是删除尾部元素不需要移动元素,所以时间复杂度为O(1)。和add(...)方法一样,删除尾部元素也有可能导致缩容操作,缩容操作是的时间复杂度为O(n),所以删除尾部元素最坏时间复杂度为O(n),其对应的代码实现如下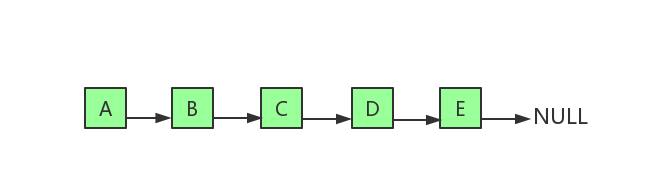 上图是单链表基本结构,每个节点除了存储自身的数据外,还需要存储指向下一个节点的指针,分别称为数据域和指针域,最后一个节点的指针指向NULL。
上图是单链表基本结构,每个节点除了存储自身的数据外,还需要存储指向下一个节点的指针,分别称为数据域和指针域,最后一个节点的指针指向NULL。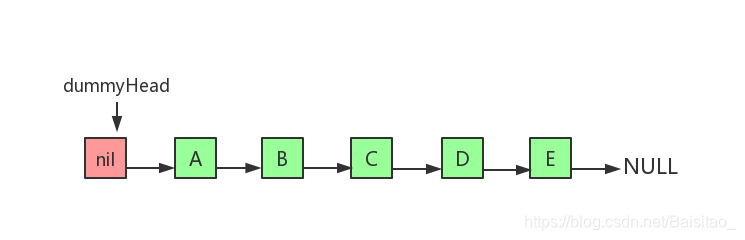 dummyHead指向虚拟头节点,虚拟头节点的值为nil,也就是null。而节点A才是真正的头节点。 首先定义LinkedList
dummyHead指向虚拟头节点,虚拟头节点的值为nil,也就是null。而节点A才是真正的头节点。 首先定义LinkedList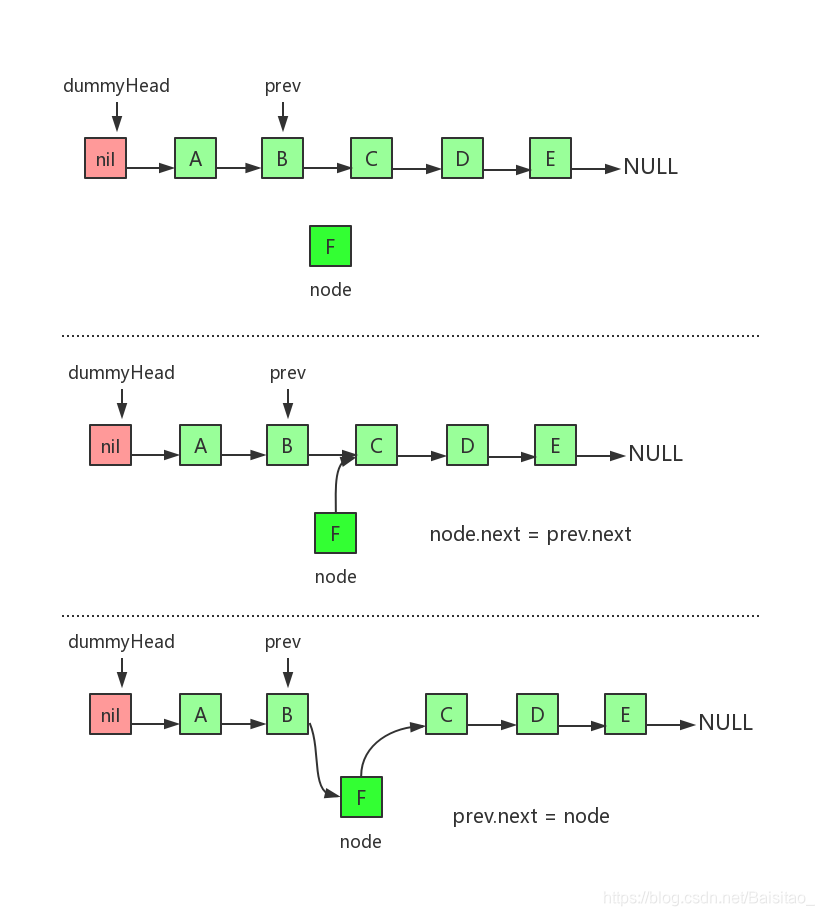 图示三步就是在链表指定位置插入新的节点的三个步骤。需要特别注意的是B、C、F三个节点的指向变化。还有一点就是第二步和第三步不能调换顺序。至于为什么,读者自己画个草图就一目了然了。事实上,链表相关的操作,顺序都非常重要,不能随意调换操作顺序。 对于以上的逻辑,实现代码如下:
图示三步就是在链表指定位置插入新的节点的三个步骤。需要特别注意的是B、C、F三个节点的指向变化。还有一点就是第二步和第三步不能调换顺序。至于为什么,读者自己画个草图就一目了然了。事实上,链表相关的操作,顺序都非常重要,不能随意调换操作顺序。 对于以上的逻辑,实现代码如下: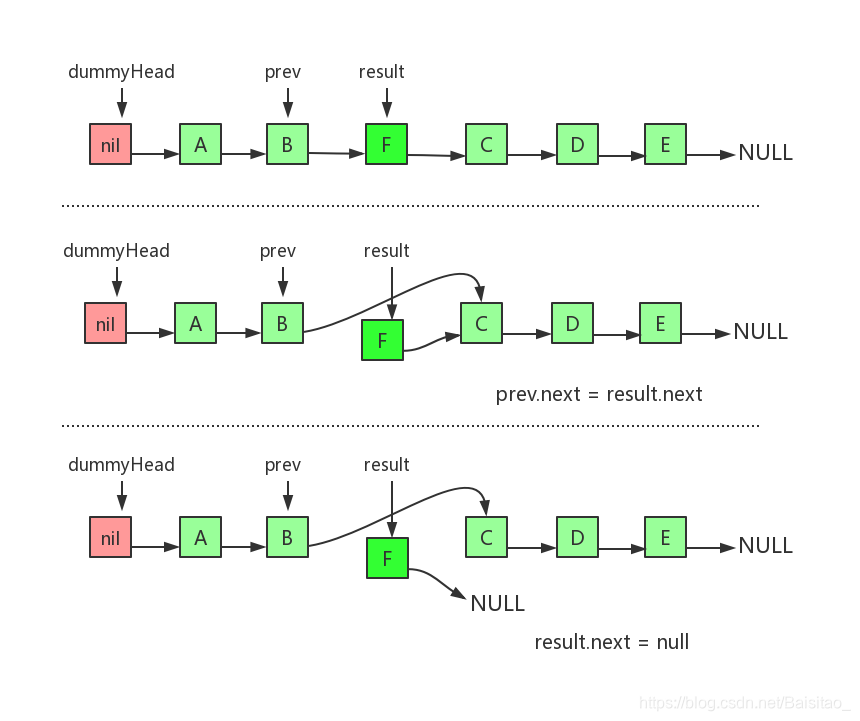 同样需要注意的是B、C、F三个节点的指向变化,并且第二步和第三步不能调换顺序。对于删除操作,实现代码如下:
同样需要注意的是B、C、F三个节点的指向变化,并且第二步和第三步不能调换顺序。对于删除操作,实现代码如下:【本文地址】