| 超详细!!!一文搞定!单目深度估计MiDas思想Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero | 您所在的位置:网站首页 › 单目视频深度估计 › 超详细!!!一文搞定!单目深度估计MiDas思想Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero |
超详细!!!一文搞定!单目深度估计MiDas思想Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero
|
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9178977 项目代码:GitHub - isl-org/MiDaS: Code for robust monocular depth estimation described in "Ranftl et. al., Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, TPAMI 2022"
问题挑战描述:高容量深度模型原则上可以相当更广泛不受场景限制,但是由于数据集的数量和质量问题,缺乏大规模场景的数据,数据多样性不足,缺乏动态物体数量。面对不同的数据集,找到合适的输出空间,设计灵活的损失函数。 三大挑战: 深度表示的固有不同:深度可以直接表示或以逆深度表示,不同的数据集使用的表示方式不同。 尺度不确定性:对于某些数据源,深度仅给出一个未知的尺度。 偏移不确定性:某些数据集提供的视差仅到未知的尺度和全局视差偏移,这与未知的基线和主点的水平偏移有关。 主要方法:设计了一个单目深度模型,在不同场景下进行测试。 设计了一个新的损失函数(对各种传感器收集到的数据进行训练),对于未知和不一致的尺度和基线的数据集,训练目标不会变化。 提出了多目标优化策略(比朴素混合策略好naive mixing strategy)。量化了多种现有数据集在单目深度估计中的价值,研究不仅仅是简单地使用这些数据集,而是对它们在训练模型时的贡献和效果进行了详细的分析和评估。 高容量编码器的重要性,高容量编码器指的是具有较高参数量和复杂结构的神经网络编码器,能够更好地捕捉和表示复杂的图像特征,从而提高深度估计的精度。 大规模数据集上预训练的重要性 引言:这篇文章的引言写的不错 MRF公式--卷积回归--stereo matching--单目估计数据集问题--建立数据集的发展历程,网上数据集多样性,但需要预处理后处理需要权限--使用多个数据集和朴素的混合方式(发展历程) 动机多样化训练数据的需求: 单目深度估计模型的成功依赖于大规模且多样化的训练集。然而,在不同环境中大规模获取密集的地面真实深度数据具有很大的挑战性。 当前已有的数据集各具特色和偏差,无法单独支持训练一个能够在各种场景中稳健工作的模型。因此,需要一种方法能够有效结合多种数据集,以提升模型的泛化能力。 现有数据集的局限性: 现有数据集各自存在不足:某些数据集只包含静态场景,有些数据集的深度测量精度较低,还有些数据集的场景多样性不足。 由于数据集的获取方式不同,各数据集之间在尺度和深度范围上存在不一致,导致直接混合训练时效果不佳。 创新点尺度和偏移不敏感的损失函数: 提出了对尺度和偏移不敏感的损失函数,能够处理不同数据集之间的深度测量不一致性。该损失函数通过对预测值和真实值进行尺度和偏移调整,使得模型在多数据集混合训练时具有鲁棒性。 多目标优化的混合策略: 采用多目标优化的方法来混合不同的数据集,而不是简单地进行数据集混合。通过将每个数据集视为一个单独的任务,使用帕累托最优(Pareto-optimal)的策略来优化模型参数,使得模型在多个数据集上都能表现良好。 引入3D电影作为新的数据源: 引入了3D电影作为新的数据源,为训练提供了多样化和大规模的动态场景数据。这些数据虽然不提供绝对深度,但通过立体匹配可以获得相对深度,从而丰富了训练数据的多样性和规模。 高容量编码器和预训练策略: 强调了高容量编码器和在大型辅助任务上预训练的重要性。通过在ImageNet等大型数据集上预训练编码器,可以显著提高模型的表现。 在实验中展示了使用不同编码器的效果,并证明了预训练在提升单目深度估计性能中的关键作用。 实验验证和零样本跨数据集传输测试: 通过大量实验验证了该方法的有效性,包括在不同数据集上的零样本跨数据集传输测试,证明了该方法在真实场景中的优越性能。 采用了多种评价指标和测试集,全面展示了模型在各种环境下的表现。 通过以上创新点,该研究在提升单目深度估计模型的鲁棒性和泛化能力方面取得了显著进展,为处理不同数据集之间的兼容性问题提供了新的解决方案。 概述总结该文献《Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer》的核心内容包括以下几个方面: 问题背景: 单目深度估计在物理环境中的行动中具有重要作用,但依赖于大规模和多样化的训练数据集。 获取各种环境下的密集地面真实深度数据存在困难,因此出现了许多具有不同特征和偏差的数据集。 目前没有任何单一数据集可以支持一个在多样化场景中都能稳健工作的模型训练。 方法概述: 提出了可以在训练期间混合多个数据集的工具,即使它们的注释不兼容。 设计了对深度范围和尺度变化不变的稳健训练目标,并使用了多目标学习的方法来结合来自不同来源的数据。 强调了在辅助任务上预训练编码器的重要性。 通过在五个不同的数据集(包括一个新的3D电影数据源)上进行实验,验证了该方法的泛化能力。 创新点: 设计了对尺度和偏移不敏感的损失函数,可以处理数据集之间的不兼容性。 提出了基于多目标优化的混合策略,而不是简单的混合方法。 使用了高容量编码器,并展示了在大型辅助任务上预训练编码器的效果。 实验和结果: 实验使用了六个不同的数据集进行零样本跨数据集传输测试,验证了方法的泛化能力。 通过与现有方法的对比,证明了该方法在多个数据集上的优越性能。 提出了3D电影作为新的数据源,并描述了从3D电影中提取和处理数据的详细过程。 结论: 该研究推进了单目深度估计领域的研究,提出的工具和方法显著提高了在多样化环境中的性能。 强调了零样本跨数据集传输测试作为衡量模型在真实世界中表现的更好代理。 未来的研究可以在更大规模的数据集上进一步验证和改进该方法。 文献的核心内容主要集中在通过混合多数据集来实现单目深度估计模型的稳健性和泛化能力,解决了单一数据集训练带来的局限性。该研究在理论创新和实验验证上都取得了显著成果,为单目深度估计领域提供了新的思路和方法。 现有数据集现有数据集的种类和特征: 介绍了多种适用于单目深度估计的数据集,这些数据集包含RGB图像和相应的深度标注。这些数据集在捕获环境(室内/室外场景、动态物体)、深度标注类型(稀疏/密集、绝对/相对深度)、准确性(激光、飞行时间、SfM、立体匹配、人工标注、合成数据)、图像质量和相机设置以及数据集规模等方面存在差异。 数据集的局限性: 每个数据集都有其独特的特征和问题。例如,高精度数据难以大规模获取,且动态物体的标注较为困难;而从互联网获取的大型数据集图像质量和深度精度有限,相机参数未知。 在单一数据集上训练的模型在该数据集的测试部分上表现良好,但在不同特征的未见数据上泛化能力有限。 解决方案: 提出了一种在多个数据集上训练的方法,并通过在训练中未见过的多样化数据集上进行测试,证明该方法显著增强了模型的泛化能力。 训练和测试数据集: 训练数据集:实验使用了五个现有且互补的数据集: ReDWeb (RW):一个小型且经过严格筛选的数据集,包含多样化和动态场景,使用较大立体基线获取的地面真实深度。 MegaDepth (MD):一个较大的数据集,主要包含静态场景,使用宽基线多视角立体重建获取的地面真实深度。 WSVD (WS):来自网络的立体视频,包含多样化和动态场景,需要按照原作者的方法重新创建地面真实深度。 DIML Indoor (DL):一个主要包含静态室内场景的RGB-D数据集,使用Kinect v2捕获。 测试数据集:选择了六个基于多样性和地面真实深度准确性的数据集进行模型泛化性能的基准测试: DIW:高度多样化,但仅提供稀疏的序数关系作为地面真实深度。 ETH3D:具有高度准确的激光扫描地面真实深度的静态场景。 Sintel:为合成场景提供了完美的地面真实深度。 KITTI 和 NYU:常用数据集,具有典型的偏差。 TUM:包含室内环境中人类活动的动态子集。 强调在这些测试数据集上进行零样本跨数据集传输测试,即模型在训练中未见过这些数据集。 3D电影数据源引入3D电影作为新数据源: 为了补充现有数据集,研究提出了使用3D电影作为新的数据源。3D电影包含各种动态环境中的高质量视频帧,包括以人物为中心的故事和对话驱动的好莱坞电影到自然景观和动物纪录片。 尽管这些数据不提供绝对深度,但可以通过立体匹配获得相对深度。3D电影提供了最大规模的立体图像对,且这些图像对是在精心控制的条件下捕获的,这使得研究能够利用大量高质量图像。 数据的优势和处理: 3D电影数据源无需手动过滤问题内容,可以轻松扩展或适应特定需求,例如聚焦于跳舞的人类或自然纪录片。 数据的多样性和规模是主要驱动力,3D电影提供了成千上万的高质量图像对。 挑战和数据处理: 电影数据存在自身的挑战和缺陷。例如,立体电影的主要目标是提供视觉愉悦的观看体验,避免观众不适。这意味着每个场景的视差范围(也称为深度预算)是有限的,并取决于艺术和心理物理学的考虑。 场景中的焦距、基线和立体摄像机之间的汇聚角度未知,并且在同一部电影的不同场景之间也有所变化。此外,与标准立体摄像机直接获得的图像对不同,电影中的立体对通常包含正负视差,以使物体可以被感知为在屏幕前或屏幕后。 电影选择和预处理: 研究选择了23部多样化的电影,确保这些电影使用物理立体摄像机拍摄,兼顾现实主义和多样性,并且能够从Blu-ray格式中提取高分辨率图像。 提取的立体图像对分辨率为1920x1080,每秒24帧。对图像进行裁剪,使用FFmpeg的场景检测工具提取片段,过滤掉混乱的动作场景和高度相关的片段。 视差提取: 使用立体匹配来估计视差图,但现有立体匹配算法在应用于电影数据时表现较差,因此使用现代光流算法来处理立体对。 进行左右一致性检查,自动过滤质量较差的帧,并使用预训练的语义分割模型检测属于天空区域的像素,将它们的视差设置为图像中的最小视差。 数据集构建和示例: 最终选择了19部电影的帧用于训练,2部用于验证,2部用于测试。过滤后的电影帧数在表2中列出。图2中展示了最终数据集中的示例帧。 尺度和偏移不变的损失函数视差空间中的预测: 研究提出在视差空间中进行预测,即在尺度和偏移变化不变的情况下进行预测。视差是深度的逆表示,因此称为逆深度。 定义尺度和偏移不变的损失函数: 尺度和偏移估计:  对齐方法:  定义损失函数类型:  
这部分内容提出了在深度估计训练中应对尺度和偏移不确定性的方法,即在视差空间中进行预测,并设计了尺度和偏移不变的损失函数。这些损失函数通过对预测值和地面真实值进行尺度和偏移对齐,使得模型能够在多样化的数据源上鲁棒地训练和预测,提升了模型的准确性和鲁棒性。 相关损失函数这部分内容介绍了现有相关损失函数以及它们在单目深度估计中的应用和局限性,随后阐述了本文提出的损失函数的优势。 现有的尺度不变损失函数:
相对深度估计的普遍适用损失函数:  Wang等人提出的归一化多尺度梯度(NMG)损失:  本文提出的损失函数的优势: 本文提出的尺度和偏移不变损失函数直接在地面真实视差值上评估,同时考虑未知的尺度和偏移。 虽然序数损失和NMG损失在概念上也适用于任意深度表示并适合混合多样的数据集,但实验结果表明,本文的尺度和偏移不变损失变体在性能上始终更佳。 这部分内容比较了现有的几种单目深度估计损失函数,包括它们的优势和局限性,并解释了本文提出的损失函数如何在处理未知尺度和偏移方面具有优势,最终在性能上表现出更好的结果。 最终损失函数提出的最终损失函数和混合训练策略。 最终损失函数: 多尺度、尺度不变的梯度匹配项: 
为了在视差空间中定义完整的损失函数,研究将多尺度、尺度不变的梯度匹配项应用于视差空间。 这个梯度匹配项的目的是使不连续性保持锐利,并与地面真实值中的不连续性一致。 最终损失函数的定义: 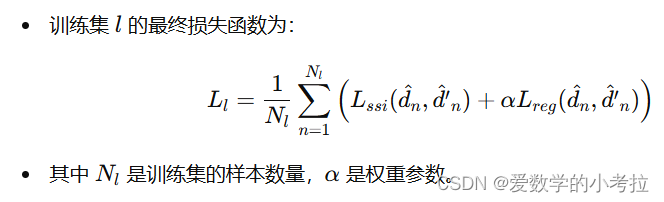 混合训练策略: 朴素策略: 第一种策略是将数据集按相等比例混合在每个小批量中。在大小为 B 的小批量中,从每个数据集中抽取 B/L 个训练样本,其中 L 表示不同数据集的数量。 这种策略确保所有数据集在有效训练集中均匀代表,不论其个体规模如何。 更为原则的方法: 
第二种策略采用最近的帕累托最优多任务学习程序,并将其适应本文的设置。 将每个数据集的学习定义为一个独立任务,寻求数据集上的帕累托最优解(即无法在不增加至少一个数据集损失的情况下减少任何训练集的损失)。 独立任务:每个数据集作为一个独立任务,拥有自己的损失函数。 共享参数:模型参数 uuu 在所有任务(数据集)之间共享。 帕累托最优:目标是找到一个帕累托最优解,使得在不增加某个任务损失的情况下,不能减少其他任务的损失。 多目标优化:通过多目标优化准则,使用特定算法来实现这一点。 这部分内容提出了本文的最终损失函数,该函数结合了多尺度、尺度和偏移不变的梯度匹配项,以处理视差数据的尺度和偏移不确定性。此外,介绍了两种混合训练策略:一种是朴素的等比例混合策略,另一种是基于帕累托最优多任务学习的方法。实验表明,第二种策略在处理多个数据集时更加有效,提升了模型的性能和泛化能力。 损失函数总结 尺度和偏移不变的损失函数 提出的损失函数: Lssi_mse:在视差空间中计算,考虑了未知的尺度和全局视差偏移。通过最小二乘准则对齐预测值和地面真实值,定义了尺度和偏移不变的均方误差(MSE)损失。 Lssi_mae:基于绝对偏差的鲁棒损失函数,处理地面真实数据中的异常值。 Lssi_trim:裁剪每张图像中20%的最大残差,进一步提升鲁棒性。 相关现有损失函数 Eigen等人的尺度不变损失:在对数深度空间中计算,考虑了预测值的未知尺度,但没有考虑全局视差偏移。 Chen等人的序数关系损失:基于相对深度估计的普遍适用损失,通过编码点对的序数关系来鼓励点对分离或聚集。 Wang等人的归一化多尺度梯度(NMG)损失:通过在多个尺度上评估梯度差异,实现视差空间中的尺度和偏移不变性。 最终损失函数的定义 多尺度、尺度不变的梯度匹配项:结合了多尺度的梯度匹配项,确保不连续性保持锐利,并与地面真实值中的不连续性一致。
混合训练策略 朴素策略:在每个小批量中按相等比例混合数据集,确保所有数据集在有效训练集中均匀代表。 帕累托最优多任务学习策略:将每个数据集的学习定义为一个独立任务,使用多目标优化算法寻求帕累托最优解,确保在不增加某个任务损失的情况下,不能减少其他任务的损失。 |





【本文地址】