| stm32 | 您所在的位置:网站首页 › 单片机buffer溢出怎么解决 › stm32 |
stm32
|
STM32内存结构
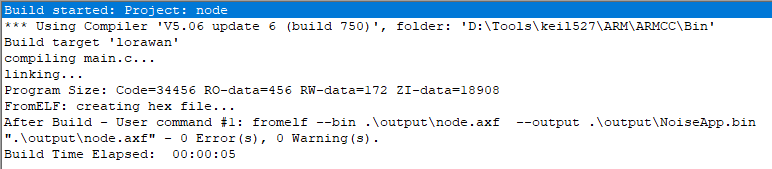
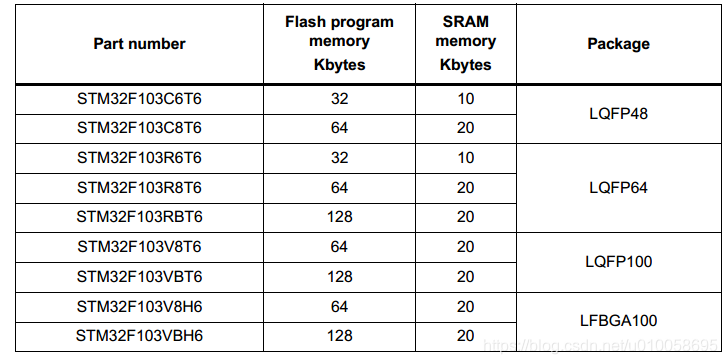
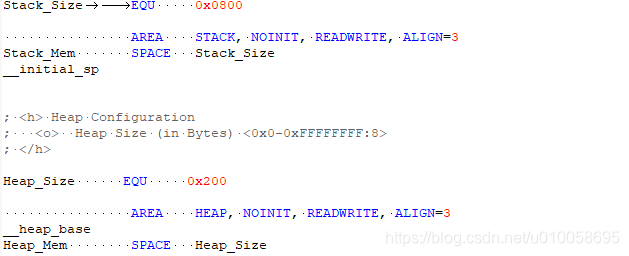
1.3 三种存储属性区: RO/RW/ZI RO (Read Only ): 只读区域, 需要长久保存,烧写到Rom/Flash段,上文数据段的.text段和.constdata段属于此属性区(有时.constdata 段也被叫做 RO-data段, 和这个广义的RO注意区分) RW (Read Write): 可读可写的初始化了的全局变量和静态变量段,上文中的.data段属于RW区 ZI (Zero Init): 没有进行初始化或者初始化为0,系统上电时会主动把此区域数据进行0初始化,上文的.bss段就是. 另外, 可翻看Keil工具编译的map文件,Heap和Stack区也进行了Zero的属性标注, 因此, Heap和Stack也可认为是ZI区域 RW区比较特别, 可读可写但又进行了初始化,因为RAM中的数据是掉电不可保存的,因此RW区的.data段数据也需要保存在Rom/Flash里面,上电时候再将此类数据复制到RAM区域读写使用。而ZI区域数据不需要掉电保存,直接上电时初始化为0即可使用,因此不需要保存在ROM中。这样,计算RAM/ROM占用空间的公式: ROM Size = .text + .constdata + .data (RO + RW) RAM Size = .bss + .data (ZI + RW) 这里RAM size计算时未考虑Stack和Heap区, 实际size是大于此的, 因为这两个区域具备动态变化的复杂性,难于估计。 定义一个全局数组变量举例: 1. static unsigned char test[1024]; //全局、未初始化, ZI区,不影响ROM size 2. static unsigned char test[1024] = {0}; //全局、初始化为0, ZI区,不影响ROM size 3. static unsigned char test[1024] = {1}; //全局、初始化为非0, RW(.data)区,ROM Size 扩大 1.4 扩展说说Heap 在STM32的启动代码startup_*.s文件中,一般这样定义了堆大小: Heap_Size EQU 0x200; 在实际使用中, 这个区域可能比1.2节提到的简洁描述更为复杂。 很多小项目没有使用内存分配器: 由于各种原因(RAM不足、程序简单、etc),一些所必须的大块或固定内存直接使用数组的方式定义使用,绕开了内存分配器。那么这个时候, Heap_Size 的存在是没有意义的, Heap_Size 定义越大,越浪费空间,可以直接Heap_Size定义为0。这个时候, 本来该堆区提供的空间可能定义在了.bss段(全局/静态数组没有初始化)、或.data(全局/静态数据初始化为非0)、或Stack上(使用了局部数组变量, Tips: 但大的数组不建议定义在stack, 否则可能栈溢出) 重新实现内存分配器:没有直接将内存分配器直接映射在堆区,而是先定义大的数组内存(可能在.bss或.data, 为避免在ROM存储, 最好在.bss), 再将这块内存给内存分配器支配使用 内存分配器直接使用Heap区: 这个时候就要计算好预留多少空间给Stack区, 留多了,Stack用不上浪费;留少了极可能造成Stack溢出而程序崩溃 除了使用自带RAM外,同时使用外部扩展RAM: 这就需要内存分配器来管理好几块地址不连续的RAM空间了 Stm32的keil编译连接如上图所示。 编译信息包含以下几个部分: 1)Code: 代码段,存放程序的代码部分 2)RO-data:只读数据段, 存放程序中定义的常量; 3)RW-data: 读写数据段,存放初始化为非0值的全局变量 4)ZI-data: 零数据段,存放未初始化的全局变量及初始化为0的变量; 编译完工程会生成一个. map 的文件,该文件说明了各个函数占用的尺寸和地址,在文件的最后几行也说明了上面几个字段的关系: Total RO Size (Code + RO Data) 46052 ( 44.97kB) Total RW Size (RW Data + ZI Data) 36552 ( 35.70kB) Total ROM Size (Code + RO Data + RW Data) 46212 ( 45.13kB) 1)RO Size 包含了 Code 及 RO-data,表示程序占用Flash空间的大小 2)RW Size 包含了RW-data及ZI-data,表示运行时占用的RAM的大小 3)ROM Size 包含了Code, RO Data以及RW Data, 表示烧写程序所占用的Flash空间的大小 STM32中程序占用内存容量 Keil MDK下Code, RO-data,RW-data,ZI-data这几个段: Code存储程序代码。 RO-data存储const常量和指令。 RW-data存储初始化值不为0的全局变量。 ZI-data存储未初始化的全局变量或初始化值为0的全局变量。 占用的Flash=Code + RO Data + RW Data; 运行消耗的最大RAM= RW-data+ZI-data; 这个是MDK编译之后能够得到的每个段的大小,例如下图Program Size 中的Code R0 RW ZI
可以计算出占用的FLASH = 34456+456+172=34.26kB,占用的RAM=172+18908=18.63kB
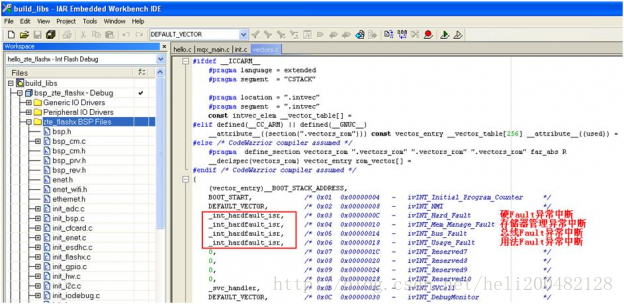
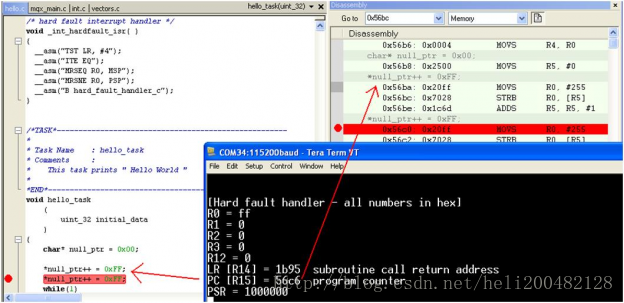
那么堆栈是如何分配的呢,堆栈的内存占用就是在上面RAM分配给RW-data+ZI-data之后的地址开始分配。 堆:编译器调用动态内存分配的内存区域。 栈:程序运行的时候局部变量的地方,先进后出,这种结构适合程序调用,所以局部变量用数组太大了都有可能造成栈溢出 堆栈溢出容易导致HaltFault。 堆栈大小的设置在启动文件start_stmf103xb.s中(以STM32F103为例): 全局变量被未知原因改变的解决方法 在开发的过程中总会碰到一些奇怪的问题,仿真的时候一看,发现是某个全局变量被莫名其妙改变了,导致整个函数判断都出了问题。 全局变量可能会被改变的原因有以下几点: 1.自己改的(废话~):好好查看这个变量被谁调用了 2.全局变量字节未对齐: 有一次调试的时候发现一个变量定义成局部变量就能正常运行,而定义成全局变量就不能运行了。局部变量能运行说明我程序的逻辑是没问题的,找原因的时候一看是我全局变量经常会莫名其妙被改变。找了一圈发现这个变量根本没被其他函数使用。 后面通过仿真,得到该变量的地址(假设为0x1002)。地址除以4之后发现不是一个整数,这才发现是这个变量字节未4字节对齐导致的。至于为什么不对齐,我也不知道! 解决方法:使用 attribute((aligned(4))) 修饰,使其4字节对齐,就完美解决了。 3.指针未初始化: 假如你定义的变量是指针类型的话,没有给他初始化则会导致该指针是个野指针,里面的值是不确定的。 总之开发的过程中,少用全局变量,要用的话尽量用结构体,做好分层,提高代码的可阅读性和移植性。 stm32-hardfault产生的原因分析其实野指针,数组越界,堆栈溢出等等,都是由于触发了总线异常、存储器管理异常、使用异常中的一个或多个,才触发了hardfault。 1.内存的溢出,包括堆栈的溢出。 其 中 单 片 机 内 存 和 堆 栈 的 关 系 , 可 以 参 考 http://blog.csdn.net/c12345423/article/details/53004747 2.越界访问。 这常指数组的使用,具体来说,访问只有5个元素的数组的第6个元素时,就出 现了越界访问。而这一错误,常常出现于数组作为函数参数传入时,由于只传入 指针,而函数中不确定指针访问的平移量,就可能出现越界访问的错误。值得注 意的是,C语言并没有越界访问的编译查询,也就是说,在编译时不会检测是否 存在越界访问。 3.错误使用flash造成的异常错误。 一是由于在使用flash存储数据时,其存储空间有可能和代码区重叠;二是由于 自身需求,需要转换指向flash的指针的指向类型,如转换成float*,使指针在 flash上以4个单位的间隔移动,但是由于flash是分区的,如果区首地址和被转 换指针之间的间隔不是4的倍数也会出现错误。 4.这一年大家都是自己画PCB,自己写程序,有时候会发现PCB的焊接也会造成 HardFault,并且这种错误从程序开始就会存在。 5.野指针寻址,除以0(也可能得出inf而不会产生错误)等常见C语法错误。 Kinetis MCU 采用 Cortex-M4 的内核,该内核的 Fault 异常可以捕获非法的内存访问和非法的编程行为。Fault异常能够检测到以下几类非法行为: 总线 Fault: 在取址、数据读/写、取中断变量、进入/退出中断时寄存器堆栈操作(入栈/出栈)时检测到内存访问错误。 存储器管理 Fault: 检测到内存访问违反了内存保护单元(MPU, MemoryProtection Unit)定义的区域。 用法 Fault: 检测到未定义的指令异常,未对其的多重加载/存储内存访问。如果使能相应控制位,还可以检测出除数为零以及其他未对齐的内存访问。 硬 Fault: 如果上述的总线 Fault、存储器管理 Fault、用法 Fault 的处理程序不能被执行(例如禁能了总线 Fault、存储器管理Fault、用法Fault 的异常或者在这些异常处理程序中又出现了新的Fault)则触发硬Fault。 为了解释所述的 Fault 中断处理程序的原理,这里重述一下当系统产生异常时 MCU 的处理过程: 1. 有一个压栈的过程,若产生异常时使用 PSP(进程栈指针),就压入到 PSP 中,若产生异常时使用MSP(主栈指针),就压入MSP 中。 2. 会根据处理器的模式和使用的堆栈,设置 LR 的值(当然设置完的LR 的值再压栈)。 3. 异常保存,硬件自动把 8 个寄存器的值压入堆栈(8 个寄存器依次为 xPSR、PC、LR、R12以及 R3~R0)。如果异常发生时,当前的代码正在使用PSP,则上面8 个寄存器压入PSP; 否则就压入MSP。 当系统产生异常时,我们需要两个关键寄存器值,一个是 PC ,一个是 LR (链接寄存器),通过 LR找到相应的堆栈,再通过堆栈找到触发异常的PC 值。将产生异常时压入栈的 PC 值取出,并与反汇编的代码对比就能得到哪条指令产生了异常。这里解释一下关于 LR 寄存器的工作原理。如上所述,当 Cortex-M4 处理器接受了一个异常后,寄存器组中的一些寄存器值会被自动压入当前栈空间里,这其中就包括链接寄存器(LR )。这时的 LR 会被更新为异常返回时需要使用的特殊值(EXC_RETURN)。 关于EXC_RETURN 的定义如下,其为 32 位数值,高 28 位置 1,第 0 位到第三位则提供了异常返回机制所需的信息,如下表所示。可见其中第 2 位标示着进入异常前使用的栈是 MSP还是PSP。在异常处理过程结束时,MCU 需要根据该值来分配 SP 的值。这也是本方法中用来判断所使用堆栈的原理,其实现方法可以从后面_init_hardfault_isr 中看到。 另外,我们可以利用 MQX 的控制台串口输出Fault 异常信息来帮助调试。编写Fault 处理程序时,将启动代码中默认的Fault 处理程序跟换成自己需要的Fault 处理程序。需要注意的是,由于是在中断中进行打印输出,MQX的控制台串口只能使用POLL 轮询模式的驱动,不能使用中断模式的驱动。 用户可以编写自定义的硬 Fault 处理程序_int_hardfault_isr,修改 MQX 的中断向量定义vector.c,把里面的DEFAULT_VECTOR 代码段换成下面的代码。当系统出现硬Fault 异常时,将会调用自定义的Fault 处理_int_hardfault_isr函数。在这个函数,我们可以通过StackTrace-back 回溯出现问题的代码。 我们可以在_int_hardfault_isr 函数里将出现异常时的寄存器、堆栈、状态寄存器等信息打印出来。如果系统出现异常时,一般情况都会通过串口控制台打印出LR,PC的值。然后根据编译器生成的map 文件,找到出现问题的具体函数。 从上图的串口输出我们可以看到 PC 和 LR 寄存器值,PC 的值为 0x56c6,我们根据汇编代码可以找到出现问题的指令。从而大大缩小了查找出现问题的范围,可以帮助开发人员快速定位问题的根本原因。 附录Fault异常中断处理代码: // hard fault handler in C, // with stack frame location as input parameter void hard_fault_handler_c (unsigned int * hardfault_args) { unsigned int stacked_r0; unsigned int stacked_r1; unsigned int stacked_r2; unsigned int stacked_r3; unsigned int stacked_r12; unsigned int stacked_lr; unsigned int stacked_pc; unsigned int stacked_psr; stacked_r0 = ((unsigned long)hardfault_args[0]); stacked_r1 = ((unsigned long)hardfault_args[1]); stacked_r2 = ((unsigned long)hardfault_args[2]); stacked_r3 = ((unsigned long)hardfault_args[3]); stacked_r12 = ((unsigned long)hardfault_args[4]); stacked_lr = ((unsigned long)hardfault_args[5]); stacked_pc = ((unsigned long)hardfault_args[6]); stacked_psr = ((unsigned long) hardfault_args[7]); printf ("\n\n[Hard faulthandler - all numbers in hex]\n"); printf ("R0 = %x\n",stacked_r0); printf ("R1 = %x\n",stacked_r1); printf ("R2 = %x\n",stacked_r2); printf ("R3 = %x\n",stacked_r3); printf ("R12 = %x\n",stacked_r12); printf ("LR [R14] = %x subroutine call return address\n",stacked_lr); printf ("PC [R15] = %x program counter\n", stacked_pc); printf ("PSR = %x\n",stacked_psr); /******************* Add yourdebug trace here ***********************/ _int_kernel_isr(); } /* hard fault interrupt handler */ void _int_hardfault_isr( ) { __asm("TST LR, #4"); __asm("ITE EQ"); __asm("MRSEQ R0,MSP"); __asm("MRSNE R0,PSP"); __asm("Bhard_fault_handler_c"); }在没有JTAG的情况下,通过串口打印出堆栈信息: /* Private typedef -----------------------------------------------------------*/ enum { r0, r1, r2, r3, r12, lr, pc, psr}; /* Private define ------------------------------------------------------------*/ /* Private macro -------------------------------------------------------------*/ /* Private variables ---------------------------------------------------------*/ extern __IO uint16_t ADC_InjectedConvertedValueTab[32]; uint32_t Index = 0; /* Private function prototypes -----------------------------------------------*/ void Hard_Fault_Handler(uint32_t stack[]); /* Private functions ---------------------------------------------------------*/ static void printUsageErrorMsg(uint32_t CFSRValue) { printf("Usage fault: \r\n"); CFSRValue >>= 16; // right shift to lsb if((CFSRValue & (1HFSR); printf(msg); if ((SCB->HFSR & (1 CFSR ); printf(msg); if((SCB->CFSR & 0xFFFF0000) != 0) { printUsageErrorMsg(SCB->CFSR); } if((SCB->CFSR & 0xFF00) != 0) { printBusFaultErrorMsg(SCB->CFSR); } if((SCB->CFSR & 0xFF) != 0) { printMemoryManagementErrorMsg(SCB->CFSR); } } stackDump(stack); __ASM volatile("BKPT #01"); //} while(1); } __ASM void HardFault_Handler_a(void) { IMPORT Hard_Fault_Handler TST lr, #4 ITE EQ MRSEQ r0, MSP MRSNE r0, PSP B Hard_Fault_Handler } /** * @brief This function handles Hard Fault exception. * @param None * @retval None */ void HardFault_Handler(void) { /* Go to infinite loop when Hard Fault exception occurs */ HardFault_Handler_a(); }另一种方法: 默认的HardFaudler 处理方法不是死循环么?将它改成BX LR直接返回的形式。然后再这条语句打个断点,一旦在断点中停下来,说明出错了,然后再返回,就可以返回到出错的位置的下一条语句哪里。 _asm void wait() { BX lr //BX无条件转移指令 } void HardFault_Handler(void) { wait(); } |

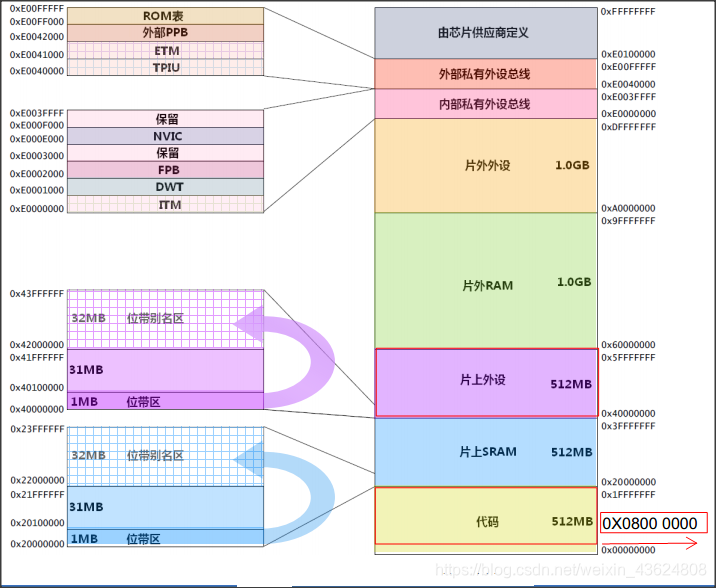
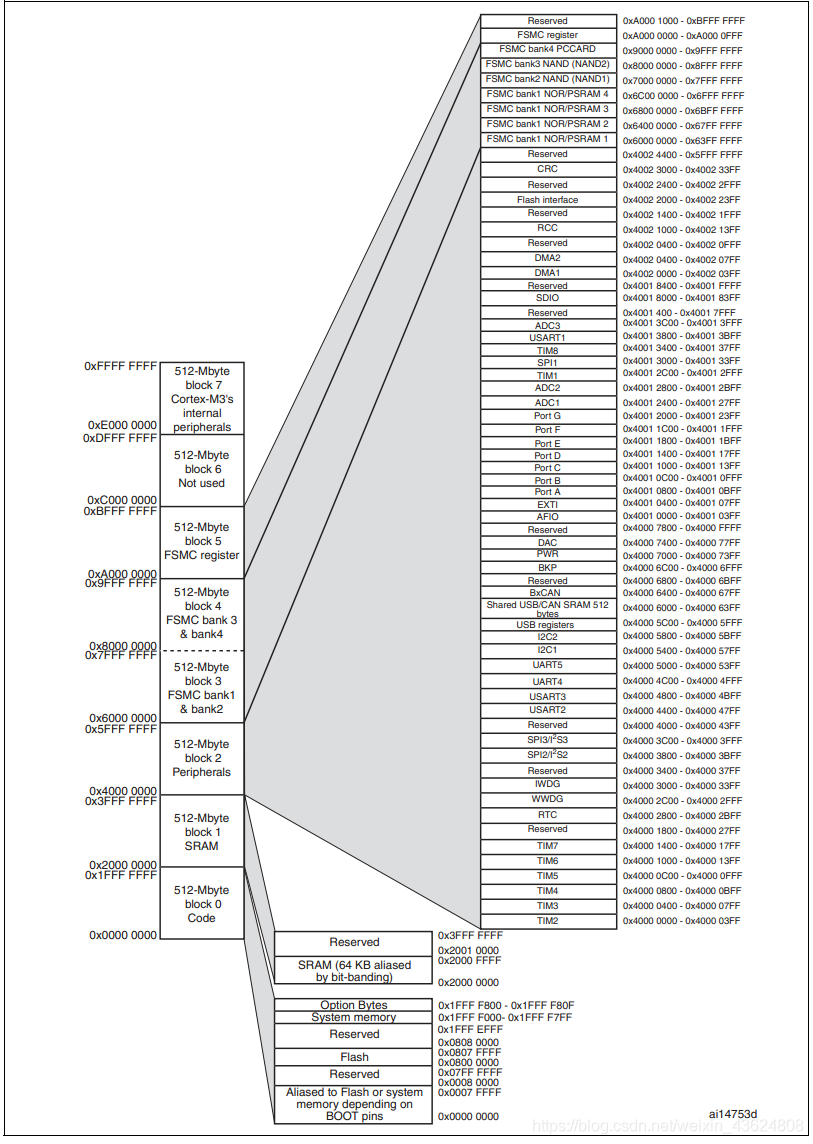 1.要点 1.1 两种存储类型: RAM 和 Flash RAM可读可写,在STM32的内存结构上,RAM地址段分布[0x2000_0000, 0x2000_0000 + RAM size) Flash只读,在STM32的内存结构上,Flash地址段[0x0800_0000, 0x2000_0000) 1.2 六类存储数据段: .data/.bss/.text/.constdata/heap/stack .data数据段: 用来存放初始化了但不是初始化为0的全局变量(global)和静态变量(static)。它是可读可写的 .bss(Block Started by Symbol)数据段: 用于存放没有初始化或初始化为0的全局变量和静态变量,可读可写,如果没有初始化, 系统会将变量初始化为0. .text代码段: 用来放程序代码(code), 在代码编译完成后, 长久只读存放于此. .constdata只读常量数据段: const限定的数据类型存放与此,只读. heap堆区: 通常只我们说的动态内存分配,使用内存分配器(memory allocator)管理, malloc/free进行申请和释放 stack栈区: 在代码执行时用来保存函数的局部变量和参数。其操作方式类似于数据结构中的栈,是一种“后进先出”(Last In First Out,LIFO)的数据结构。这意味着最后放到栈上的数据,将会是第一个从栈上移走的数据,对于哪些暂时存储的信息,和不需要长时间保存的信息来说,LIFO这种数据结构非常理想。在调用函数或过程后,系统通常会清除栈上保存的局部变量、函数调用信息及其它信息。栈的顶部通常在可读写的RAM区的最后,其地址空间通常“向下减少”,即当栈上保存的数据越多,栈的地址就越小。
1.要点 1.1 两种存储类型: RAM 和 Flash RAM可读可写,在STM32的内存结构上,RAM地址段分布[0x2000_0000, 0x2000_0000 + RAM size) Flash只读,在STM32的内存结构上,Flash地址段[0x0800_0000, 0x2000_0000) 1.2 六类存储数据段: .data/.bss/.text/.constdata/heap/stack .data数据段: 用来存放初始化了但不是初始化为0的全局变量(global)和静态变量(static)。它是可读可写的 .bss(Block Started by Symbol)数据段: 用于存放没有初始化或初始化为0的全局变量和静态变量,可读可写,如果没有初始化, 系统会将变量初始化为0. .text代码段: 用来放程序代码(code), 在代码编译完成后, 长久只读存放于此. .constdata只读常量数据段: const限定的数据类型存放与此,只读. heap堆区: 通常只我们说的动态内存分配,使用内存分配器(memory allocator)管理, malloc/free进行申请和释放 stack栈区: 在代码执行时用来保存函数的局部变量和参数。其操作方式类似于数据结构中的栈,是一种“后进先出”(Last In First Out,LIFO)的数据结构。这意味着最后放到栈上的数据,将会是第一个从栈上移走的数据,对于哪些暂时存储的信息,和不需要长时间保存的信息来说,LIFO这种数据结构非常理想。在调用函数或过程后,系统通常会清除栈上保存的局部变量、函数调用信息及其它信息。栈的顶部通常在可读写的RAM区的最后,其地址空间通常“向下减少”,即当栈上保存的数据越多,栈的地址就越小。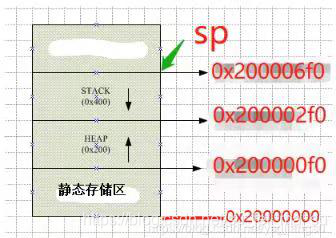

【本文地址】