| 超详细解析python爬虫爬取京东图片 | 您所在的位置:网站首页 › 华为悦盒刷完想看iptv怎么办 › 超详细解析python爬虫爬取京东图片 |
超详细解析python爬虫爬取京东图片
|
超详细图片爬虫实战
实例讲解(京东商城手机图片爬取)1.创建一个文件夹来存放你爬取的图片2.第一部分代码分析3.第二部分代码分析
完整的代码如下所示:升级版代码:
爬取过程中首先你需要观察在手机页面变化的过程来使用正则表达式匹配源码中图片的链接然后在保存到本地 其次就是信息过滤,出除了你需要的手机图片以外的其他信息过滤掉:可通过查看网页代码找到图片的起始以及结束的代码 爬取过程: 1)建立一个爬取图片的自定义函数,该函数负责爬取一个页面下我们想要爬取的图片,爬取过程为:首先通过urli request uloen(ur),reado读取对应网页的全部源代码,然后根据上面的第一个正则表达式进行第一次信息过滤, 过滤完成之后, 在第一次过滤结果的基础上,根据上面的第二个正则表达式进行第二次信息过滤,提取出该网页上所有目标图片的链接,并将这些链接地址存储的- 个列表中,随后遍历该列表,分别将对应链接通过urlib.request.urlretrieve ( imageurl, filename imagename)存储到本地,为了避免程序中途异常崩溃,我们可以建立异常处理,若不能爬取某个图片,则会通过x+=1自动跳到下一个图片。 2)通过for循环将该分类下的所有网页都爬取一遍,链接可以构造为utI=t:/ist.jd.com/list.html?cat-9987.653,655&page "+str(i),在for循环里面, 每一次循环,对应的i会自动加1,每次循环的时候通过调用1 )中的函数实现该页图片的爬取。 实例讲解(京东商城手机图片爬取) 1.创建一个文件夹来存放你爬取的图片目标网页:https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&suggest=1.def.0.V07–12s0%2C38s0%2C97s0&wq=shouji&page=“1”&s=90&click=0 首先根据网址特征我们会发现"page="这个参数能够改变网页的页数 那我们接下来试着打印出京东手机前二十页的手机网址信息 (点开每个网址你会发现page对应的数字也就是手机网页对应的页数) for i in range(1,20): url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&suggest=1.def.0.V07--12s0%2C38s0%2C97s0&wq=shouji&page="+str(i)+"&s=90&click=0" print(url)
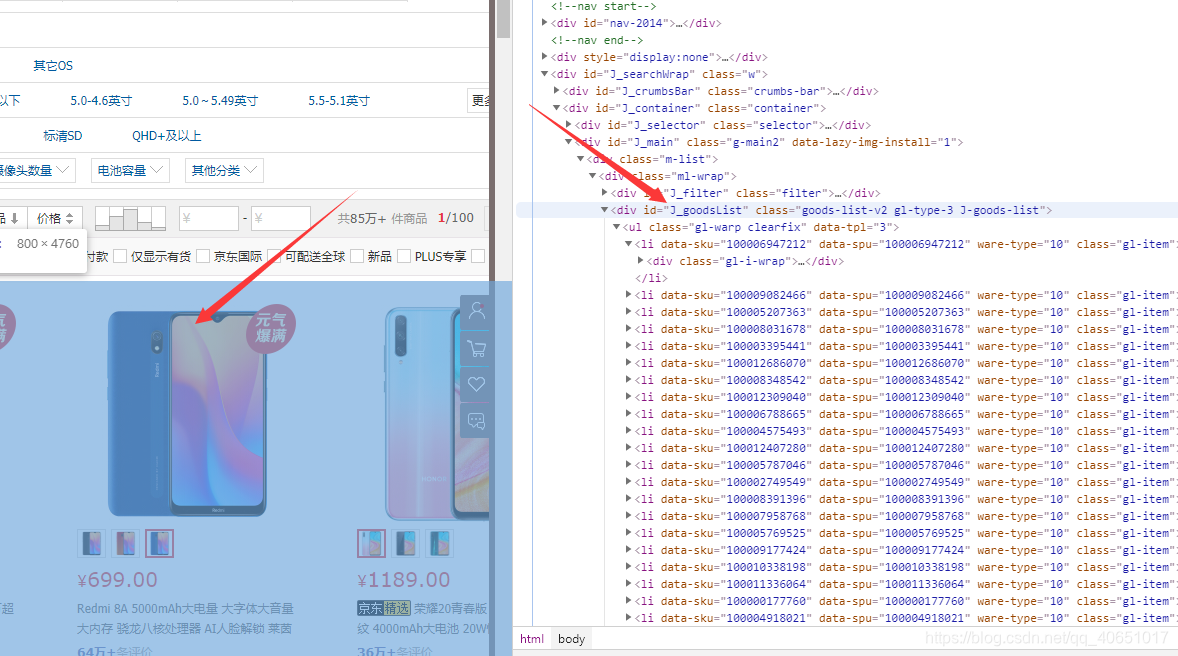
同时我们将此网页打开 按F12 我们将抓取的网页代码和真实网页代码进行对比发现: 除了一些编码的问题其余内容基本一致 说明第一步我们成功了!!! 3.第二部分代码分析根据网页里所需要抓取的代码特点来定义正则表达式 找到对应部分代码(鼠标指向代码块,网页会标记对应部分网页内容) 匹配模式1: |


【本文地址】