| 知识图谱 | 您所在的位置:网站首页 › 北青p99电池 › 知识图谱 |
知识图谱
|
GitHub:https://github.com/awslabs/dgl-ke 这个库的开源已经是去年(2020)的事情了,突然感觉时间好快~,当时并没有在意,最近关注到这个库是因为自己在训练知识图谱 Embedding 的时候做的一些调研,考虑到后续大规模知识图谱的训练,需要更快的开源库,于是DGL-KE 重新回到我的视野! 结论就是速度是很快的啊!!! 我之前用的清华开源库 OpenKE,所以我将两者速度做了一个对比,下表是 TransE 的对比结果,训练数据的规模是10w+的数据。 开源库时间迭代次数OpenKE1小时1000DGL-KE15分钟100000哦!好像就快了四倍,还好吧~ 不对啊,这里需要脑爆一下,OpenKE 训练1000轮需要1个小时,可是DGL-KE是训练了100000轮啊,没错,是10万!!!那么结果就知道了,速度快了 40倍,不,是400倍!!! 所以我说速度确实快,中短期我会考虑用这个开源库。 不过两者有不同的优势,OpenKE 的速度其实也不慢,而且代码开源,可以修改模型代码,做对比实验,对于科研人是很不错的选择。DGL-KE 将模型嵌入在库里面,修改源码很难,只能通过外部开放的参数接口调整参数训练,不过好在可以快速迭代训练大规模知识图谱,在业界是个不错的选择,不过要做创新的话就要另觅它路了。 下面我们简单看看DGL-KE 是什么,支持什么,以及如何训练,更加关注的是怎么训练自己的大规模知识图谱数据。
DGL-KE 是一个高性能、易于使用且可扩展的知识图谱嵌入工具包,它是依赖 Deep Graph Library (DGL) 库实现的,支持 CPU、GPU、分布式训练,包括 TransE、TransR、RESCAL、DistMult、ComplEx 和 RotatE 等一系列经典模型。 DGL-KE 正在继续开发中,预计一个月之后会加入 SimplE 模型、图神经网络 GNN 等。
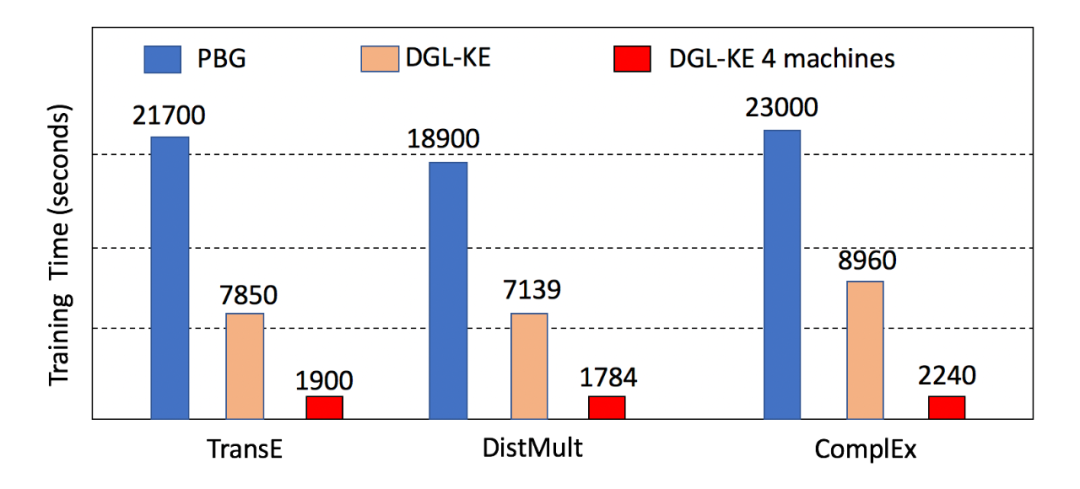
DGL-KE是为大规模知识图谱嵌入学习而设计,引入了各种新颖的优化方法,加速了拥有数百万节点和数十亿边的知识图谱的训练。对包含86M 实体 和 338M 边的知识图谱进行了测试,8个 GPU 的情况下,DGL-KE可以在100分钟内计算完成,在 4 台机器(48核/台)的集群中,可以在30分钟内计算完成,相比于业界公开的大规模知识图谱训练方法提升 2-5 倍的速度。
安装很简单,可以通过 pip 安装,也可以通过源码编译。 DGL-KE 现在在支持 python3.5 及其以上版本,内部基于 PyTorch 框架实现。 安装 PyTorch pip3 install torch 安装 DGL(基于0.4.3版本) pip3 install dgl==0.4.3 安装 DGL-KE pip3 install dglke 或者通过源码编译 git clone https://github.com/awslabs/dgl-ke.git cd dgl-ke/python python3 setup.py install 测试安装成功,运行下面命令,会下载 FB15K 数据集并训练。 mkdir my_task && cd my_task # Train transE model on FB15k dataset DGLBACKEND=pytorch dglke_train --model_name TransE_l2 --dataset FB15k --batch_size 1000 \ --neg_sample_size 200 --hidden_dim 400 --gamma 19.9 --lr 0.25 --max_step 500 --log_interval 100 \ --batch_size_eval 16 -adv --regularization_coef 1.00E-09 --test --num_thread 1 --num_proc 8 三、How to Train? 1、训练与评估命令dglke_train:单台机器上训练、支持 CPU 和 GPU。 dglke_dist_train:支持集群上分布式训练。 dglke_partition:将大规模知识图谱分为 N 个部分,每一部分采用分布式训练。 dglke_eval:评估链接预测的效果。 dglke_predict:知识推理,预测缺失的实体或者关系。 dglke_emb_sim:计算实体 Embedding 或者 关系 Embedding 的相似结果。 2、训练开放数据集DGL-KE 提供了5个开放的数据集,可以直接用命令行训练,无需准备数据,相对良心。 Dataset实体边关系FB15k14,951592,2131,345FB15k-23714,541310,116237wn1840,943151,44218wn18rr40,94393,00311Freebase86,054,151338,586,27614,824每个数据集都包含 5 个文件: train.txt: 训练集,每行一个三元组[h, r, t] valid.txt: 验证集,每行一个三元组[h, r, t] test.txt: 测试集,每行一个三元组[h, r, t] entities.dict: 实体对应的id文件 relations.dict: 关系对应的id文件 训练命令如下,修改参数 --dataset 可以下载训练不同的数据集。 # Train transE model on FB15k dataset DGLBACKEND=pytorch dglke_train --model_name TransE_l2 --dataset FB15k --batch_size 1000 \ --neg_sample_size 200 --hidden_dim 400 --gamma 19.9 --lr 0.25 --max_step 500 --log_interval 100 \ --batch_size_eval 16 -adv --regularization_coef 1.00E-09 --test --num_thread 1 --num_proc 8 3、训练自己的图谱数据训练自己的数据,命令和训练公开数据集的命令相似,只是需要按照要求的格式加载数据文件。 下面是我训练数据的命令,采用的是单个机器,在 GPU 上面训练,主要有几个参数和文件的格式要注意下。 DGLBACKEND=pytorch dglke_train --model_name TransE_l2 --data_path \ ./me/kg --dataset kg --data_files train.txt valid.txt test.txt \ --format raw_udd_htr --batch_size 1000 --neg_sample_size 200 \ --hidden_dim 400 --gamma 19.9 --lr 0.25 --max_step 100000 \ --log_interval 100 --batch_size_eval 16 -adv --regularization_coef 1.00E-09 \ --test --valid --num_thread 8 --gpu 0把数据放在 ./me/kg 的文件夹下就好了,然后 把 --data_path,--data_files,--format 这三个参数配置好 --data_path:数据的路径 --data_files:训练、验证、测试三个文件 --format:数据文件的存储格式,有两种形式 一种是以 raw_udd 开头的,代表使用的是自己原始的数据格式,仅仅需要提供三个数据文件,不需要提供实体和关系分别对应的 id 映射文件,DGL-KE 会自动生成,其中后面的 [h|r|t] 代表的是三元组的顺序,是【头实体,尾实体,关系】还是【头实体,关系,尾实体】,或者是其他的格式,可以自定义。三元组内部默认是分隔符 \t 分割,若是其他的分隔符,需要 --delimiter 指定分隔符。 另外一种是直接 udd 开头,需要提供五个文件,包括三个数据文件,以及实体和关系分别对应的id映射文件,其他的都和上面一样。 其他具体的可以参考文末的文档,还有很多的细节需要在实践中探索。 链接DGL-KE Github:https://github.com/awslabs/dgl-ke DGL-KE Documentation:/doc/ 参考资料DGL-KE: Training Knowledge Graph Embeddings at Scale https://github.com/thunlp/OpenKE DGL-KE:亚马逊开源知识图谱嵌入库,亲测快到飞起 |


【本文地址】