| python爬虫课程网络设计(对哔哩哔哩播放排行榜的爬取和数据可视化分析) | 您所在的位置:网站首页 › 动漫设计网络课程 › python爬虫课程网络设计(对哔哩哔哩播放排行榜的爬取和数据可视化分析) |
python爬虫课程网络设计(对哔哩哔哩播放排行榜的爬取和数据可视化分析)
|
一、选题的背景
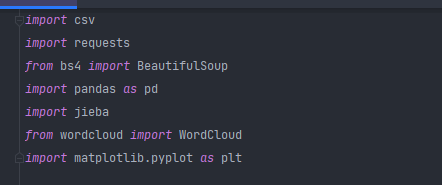
在当今社会中,人们更加注重精神需求,对二次元及动漫有着更深入的了解,此次选题围绕着哔哩哔哩动画来制作, 其目的是在最大的动漫聚集地收集用户对视频的喜好程度及播放量的一个爬取,从而了解用户的喜好及对视频类型的 一个喜好,从而对视频制作者能在今后对视频的一个制作方案有着更方便的路径,减少了视频制作者的一个成本节约, 能够更好,更快的拍取材料及后期的一些制作。 (二)、主题式网络爬虫设计方案 1.主题式网络爬虫名称对哔哩哔哩播放榜的爬取和数据可视化 2.主题式网络爬虫爬取的内容与数据特征分析二次元 https://www.bilibili.com/v/popular/rank/all项目提供了哔哩哔哩视频播放量的具体数值,该数据展示了视频播放量的前100, 及对视频播放量的一些图形等 3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)爬取哔哩哔哩排行榜下视频的排名、播放量、弹幕量,并且分析播放量与排名之间的关系 主要用到的库有python的csv、request、beautifulsoup、pandas、jieba、wordcloud、matplotlib。
三、主题页面的结构特征分析
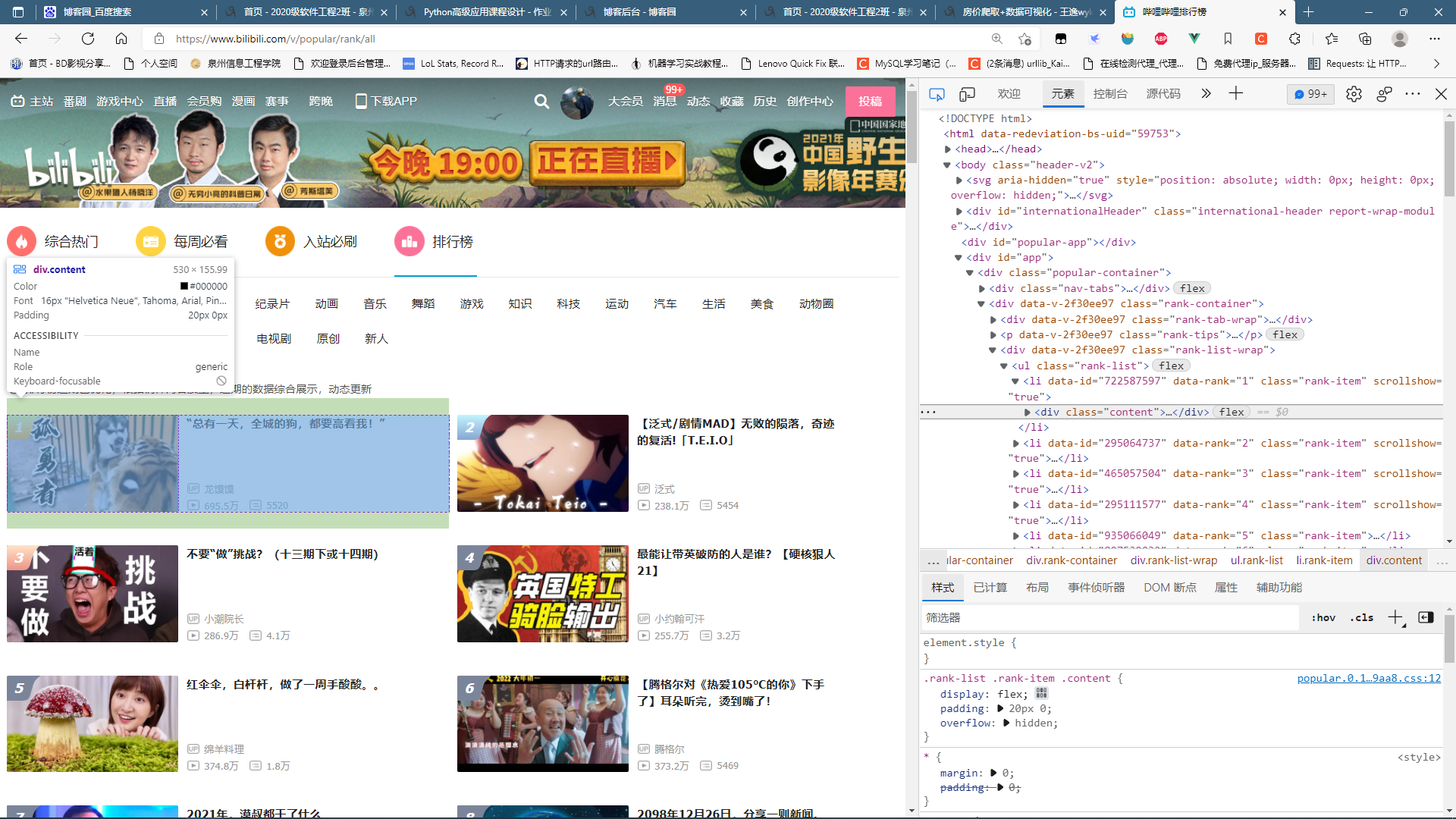
Htmls 页面解析 通过分析哔哩哔哩排行榜的页面(哔哩哔哩排行榜 (bilibili.com)),可以发现在排行榜中每一个视频都在div标签下class为content中。
可以看出标题的标签为a标签值为title 播放量的标签为div值为detail-state 弹幕数和up名的标签为span值为data-box。 (四)、网络爬虫程序设计 设计方案:根据作业的要求,制作爬虫程序爬取信息并进行数据处理,整个程序分成四个部分,包括数据爬取:(get_rank),数据清洗与处理:(rubbish),文本分析生成词云:(message),数据分析与可视化:(watch)四个部分,所用到的库有request,BeautifulSoup,csv,collections,jieba,io,wordcloud,matplotlib。使用的IDE为anaconda环境配置的pycharm,要附源代码及较详细注释。
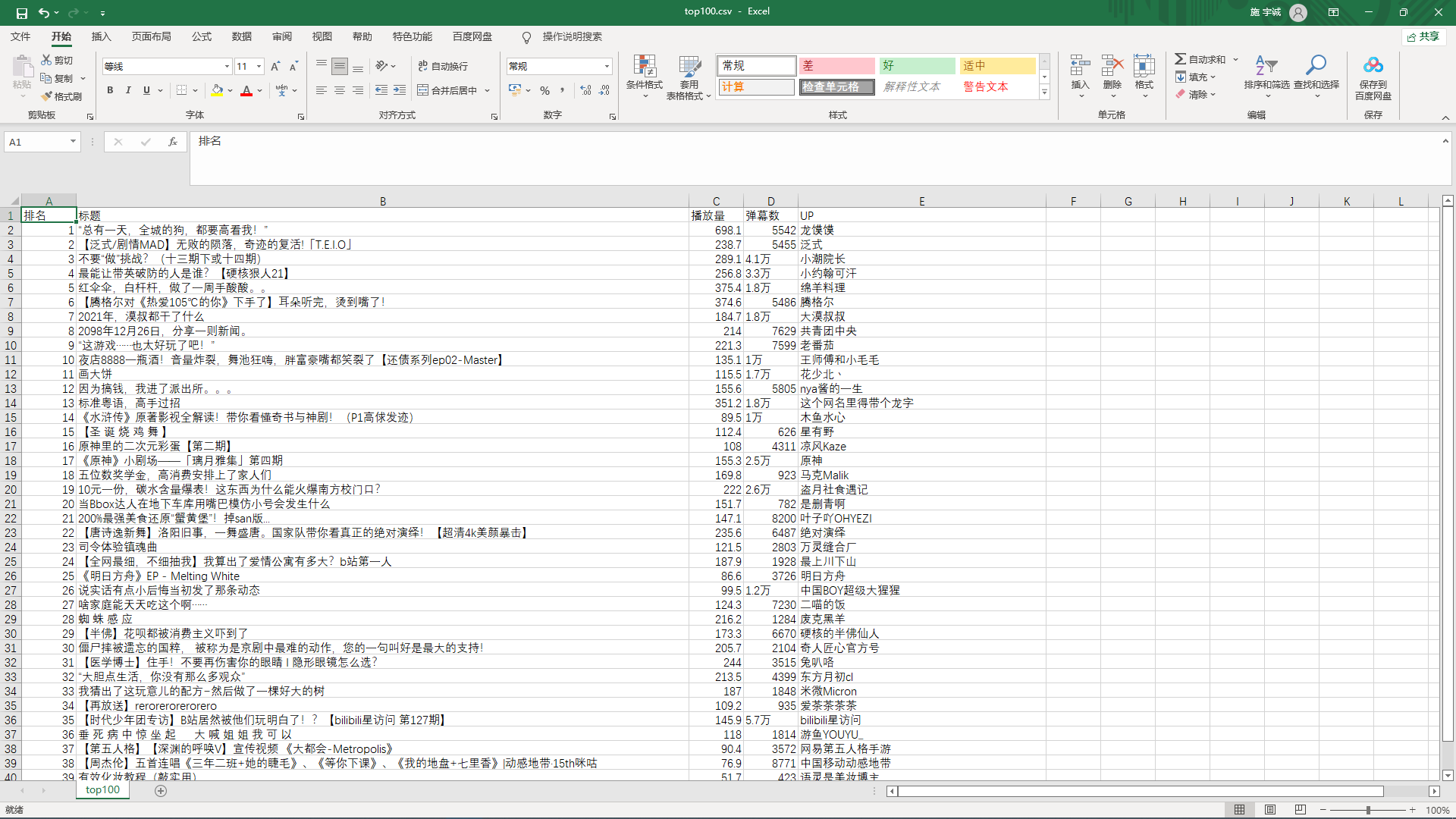
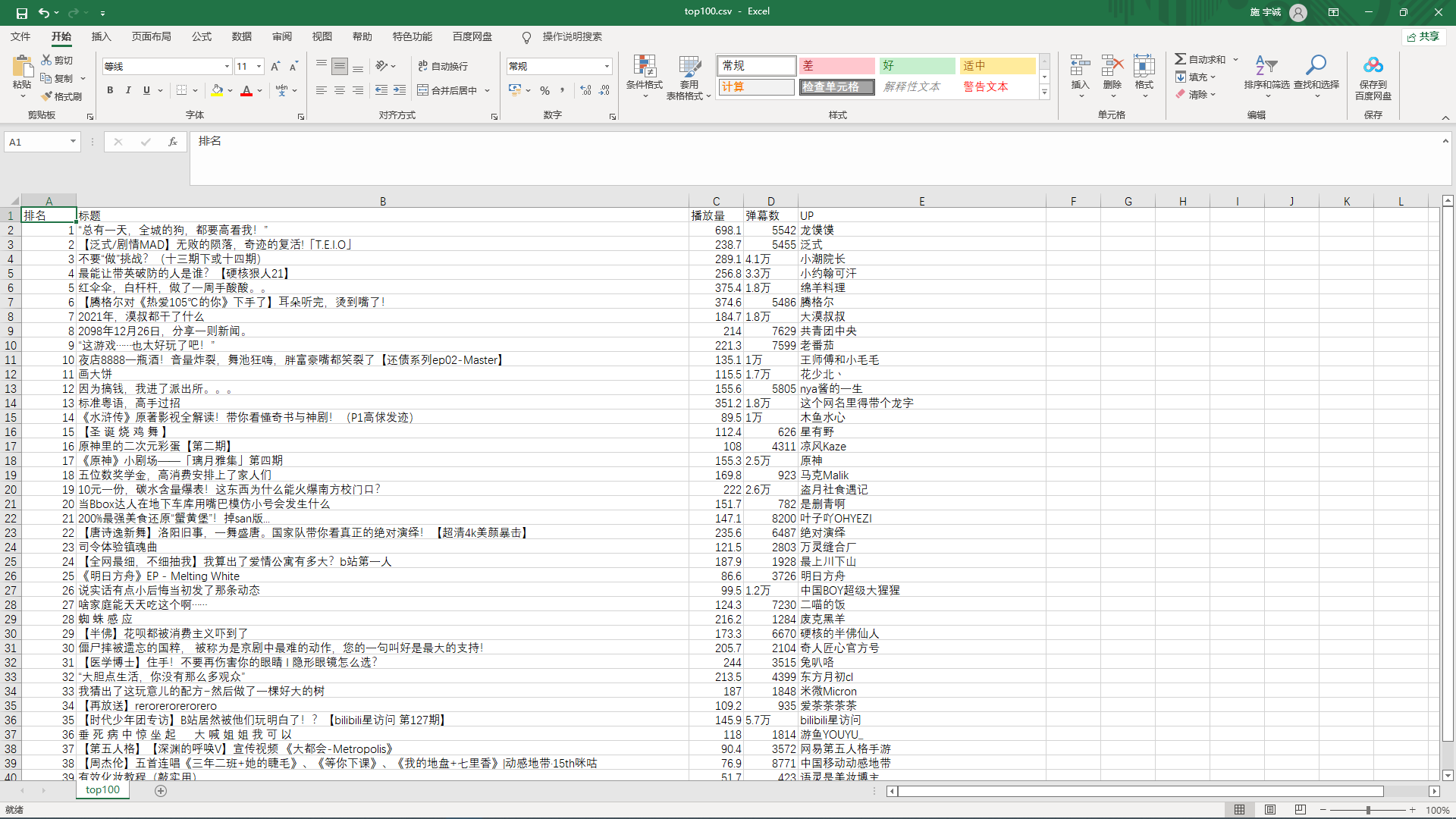
1.第一个部分,数据爬取(get_rank()): 此部分通过request来爬取需要的数据并且存入csv文件中来对数据持久化。在保存数据部分用了self函数创建数据对象来将数据读入video对象中并且放在一个列表里,最后保存在csv文件中 def get_rank(): # 数据爬取与采集 try: # 发起网络请求 url = 'https://www.bilibili.com/v/popular/rank/all' response = requests.get(url) html_text = response.text soup = BeautifulSoup(html_text, 'html.parser') # 用来保存视频信息的对象 class Video: def __init__(self, rank, title, visit, review, up): self.rank = rank self.title = title self.visit = visit self.review = review self.up = up def to_csv(self): return [self.rank, self.title, self.visit, self.review, self.up] # 使用静态方法 @staticmethod def csv_title(): return ['排名', '标题', '播放量', '弹幕数', 'UP'] rank = 1 # 提取列表 items = soup.find_all('li', {'class': 'rank-item'}) # print(items) videos = [] # 保存提取出来的video for itm in items: # print(itm) title = itm.find('a', {'class': 'title'}).text # 标题 # print(title) str = "万" visi = itm.find('div', {'class': 'detail-state'}).text.strip() # 播放量 visit = visi[:visi.index(str)] # print(visit) review = itm.find_all('span', {'class': 'data-box'})[2].text.strip() # 弹幕数 up = itm.find('span', {'class': 'data-box'}).text.strip() # up v = Video(rank, title, visit, review, up) videos.append(v) rank += 1 # 保存 file_name = f'top100.csv' with open(file_name, 'w', newline='') as f: pen = csv.writer(f) pen.writerow(Video.csv_title()) # 导出数据到csv文件中 for v in videos: pen.writerow(v.to_csv()) except: return '保存csv失败'生成的csv表格:
2.第二部分,数据清洗与处理(rubbish): def rubbish(): df=pd.read_csv('top100.csv', engine='python', encoding="GBK") # 检查是否有重复值 df.duplicated() # 检查是否有空值 df.isnull() # 异常值处理 df.describe()
3.第三个部分,文本分析生成词云:(message) 文本分析,包括使用jieba库进行分词和wouldcould生成词云,先用列的标题进行查询,读取标题所在的那一列保存在txt文档中,然后使用jieba库进行分词,使用wouldcould制作词云保存成图片 def message(): # 文本分析,包括使用jieba库进行分词和wouldcould生成词云 try: # 用DictReader读取csv的某一列,用列的标题查询 with open('top100.csv', 'rt') as csvfile: reader = csv.DictReader(csvfile) column = [row['标题'] for row in reader] # print(column) # 将标题列保存到txt文件中 file = open('top100标题.txt', 'w') file.write(str(column)) # 关闭文件 file.close() print('保存txt成功') except: print('保存txt失败') try: # 使用jieba库进行中文分词 final = "" # 文件夹位置 filename = r"top100标题.txt" # 打开文件夹,读取内容,并进行分词 with open(filename, 'r', encoding='gb18030') as f: for line in f.readlines(): word = jieba.cut(line) for i in word: final = final + i + " " # print(final) print('jieba分词成功') except: return 'jieba分词失败' try: # 使用worldcould制作词云 # 打开文本 text = open('top100标题.txt').read() # 生成对象 wc = WordCloud(font_path='C:\Windows\Fonts\simfang.ttf', width=800, height=600, mode='RGBA', background_color=None).generate(text) # 显示词云 plt.imshow(wc, interpolation='bilinear') plt.axis('off') plt.show() # 保存到文件 wc.to_file('标题词云.png') # 生成图像是透明的 print('保存词云成功') except: return '保存词云失败'生成的词云:
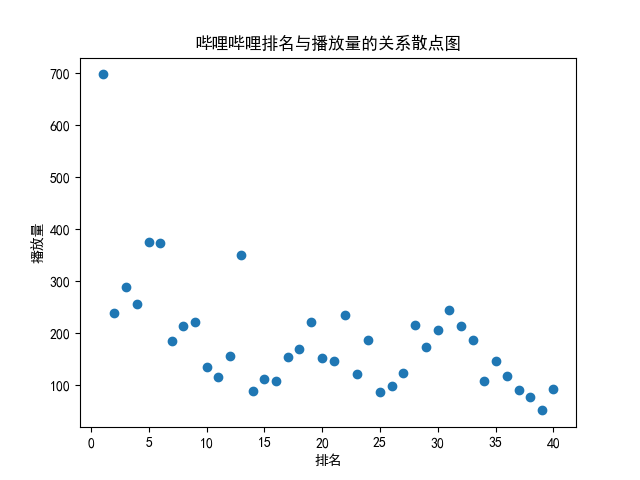
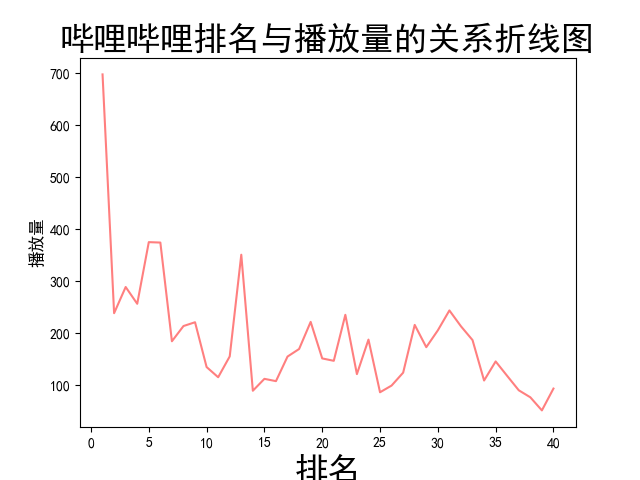
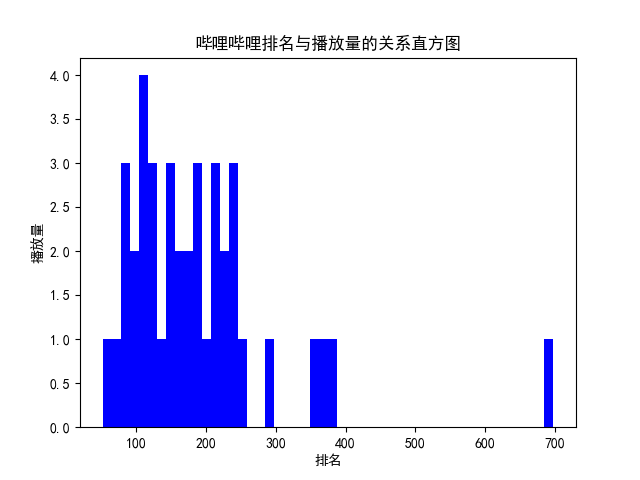
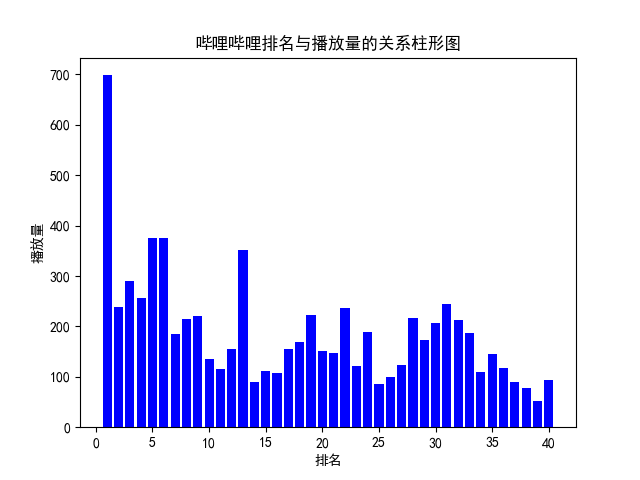
4.第四部分,数据分析与可视化:(watch) 此部分对保存的csv中的数据读出并且进行分析和可视化,包括绘制折线图,柱形图,直方图,散点图 def watch(): # 数据分析与可视化,包括绘制折线图,柱形图,直方图,散点图 try: # 获得绘图数据 point = pd.read_csv('top100.csv', engine='python', encoding="GBK") # print(data.isnull().sum) # print(type(point)) # 将字符串数据进行去除替换 rank = point['排名'].values.tolist() points = point['播放量'].values.tolist() # print(points) # 用来正常显示中文标签 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示负号 plt.rcParams['axes.unicode_minus'] = False print('获取绘图数据成功') except: return '获取数据失败' try: # 根据数据绘制折线图 plt.plot(rank, points, c='red', alpha=0.5) # 设置图形的格式 plt.title('哔哩哔哩排名与播放量的关系折线图', fontsize=24) plt.xlabel('排名', fontsize=24) plt.ylabel('播放量', fontsize=12) # 参数刻度线样式设置 plt.tick_params(axis='both', which='major', labelsize=10) # 保存图片 plt.savefig(fname="哔哩哔哩排名与播放量的关系折线图.png", figsize=[10, 10]) # 显示折线图 plt.show() print('折线图保存成功') except: return '折线图保存失败' try: # 根据数据绘制柱形图 # 创建基础图 fig = plt.figure() # 在基础图上仅绘制一个图,括号中的三个参数代表基础图中的统计图布局,参数一次代表:图的行数量、图的列数量、第几个图。本例中,为1行1列,第一个图 bar1 = fig.add_subplot(1, 1, 1) # 绘制柱形图,align表示条形与标签中间对齐。 bar1.bar(rank, points, align='center', color="blue") # 设置x、y轴标签 plt.xlabel("排名") plt.ylabel("播放量") # 设置统计图标题 plt.title("哔哩哔哩排名与播放量的关系柱形图") # 保存图片 plt.savefig(fname="哔哩哔哩排名与播放量的关系柱形图.png", figsize=[10, 10]) # 显示统计图 plt.show() print('柱形图保存成功') except: return '柱形图保存失败' try: # 绘制直方图 # 绘制基础图 fig = plt.figure() hist1 = fig.add_subplot(1, 1, 1) # 绘制直方图 # bins=50 表示每个变量的 值应该被分成 50 份。normed=False 表示直方图显示的是频率分布 hist1.hist(points, bins=50, color="blue", density=False) # 确定坐标轴位置 hist1.xaxis.set_ticks_position("bottom") hist1.yaxis.set_ticks_position("left") # 设置坐标轴标签 plt.xlabel("排名") plt.ylabel("播放量") # 设置标题 plt.title("哔哩哔哩排名与播放量的关系直方图") # 保存图片 plt.savefig(fname="哔哩哔哩排名与播放量的关系直方图.png", figsize=[10, 10]) # 显示图形 plt.show() print('直方图保存成功') except: return '直方图保存失败' try: # 绘制散点图 fig = plt.figure() scatter1 = fig.add_subplot(1, 1, 1) # 导入数据 scatter1.scatter(rank, points) # 确定坐标轴位置 scatter1.xaxis.set_ticks_position('bottom') scatter1.yaxis.set_ticks_position('left') # 设置坐标轴标签 plt.xlabel("排名") plt.ylabel("播放量") # 设置图表标题 plt.title("哔哩哔哩排名与播放量的关系散点图") # 保存图片 plt.savefig(fname="哔哩哔哩排名与播放量的关系散点图.png", figsize=[10, 10]) # 显示图形 plt.show() print('散点图保存成功') except: return '散点图保存失败'这一部分生成的图片:
以下是全部代码: import csv import requests from bs4 import BeautifulSoup import pandas as pd import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt # 注释部分的print都是为了调试用的 def get_rank(): # 数据爬取与采集 try: # 发起网络请求 url = 'https://www.bilibili.com/v/popular/rank/all' response = requests.get(url) html_text = response.text soup = BeautifulSoup(html_text, 'html.parser') # 用来保存视频信息的对象 class Video: def __init__(self, rank, title, visit, review, up): self.rank = rank self.title = title self.visit = visit self.review = review self.up = up def to_csv(self): return [self.rank, self.title, self.visit, self.review, self.up] # 使用静态方法 @staticmethod def csv_title(): return ['排名', '标题', '播放量', '弹幕数', 'UP'] rank = 1 # 提取列表 items = soup.find_all('li', {'class': 'rank-item'}) # print(items) videos = [] # 保存提取出来的video for itm in items: # print(itm) title = itm.find('a', {'class': 'title'}).text # 标题 # print(title) str = "万" visi = itm.find('div', {'class': 'detail-state'}).text.strip() # 播放量 visit = visi[:visi.index(str)] # print(visit) review = itm.find_all('span', {'class': 'data-box'})[2].text.strip() # 弹幕数 up = itm.find('span', {'class': 'data-box'}).text.strip() # up v = Video(rank, title, visit, review, up) videos.append(v) rank += 1 # 保存 file_name = f'top100.csv' with open(file_name, 'w', newline='') as f: pen = csv.writer(f) pen.writerow(Video.csv_title()) # 导出数据到csv文件中 for v in videos: pen.writerow(v.to_csv()) except: return '保存csv失败' def rubbish(): df=pd.read_csv('top100.csv', engine='python', encoding="GBK") # 检查是否有重复值 df.duplicated() # 检查是否有空值 df.isnull() # 异常值处理 df.describe() def message(): # 文本分析,包括使用jieba库进行分词和wouldcould生成词云 try: # 用DictReader读取csv的某一列,用列的标题查询 with open('top100.csv', 'rt') as csvfile: reader = csv.DictReader(csvfile) column = [row['标题'] for row in reader] # print(column) # 将标题列保存到txt文件中 file = open('top100标题.txt', 'w') file.write(str(column)) # 关闭文件 file.close() print('保存txt成功') except: print('保存txt失败') try: # 使用jieba库进行中文分词 final = "" # 文件夹位置 filename = r"top100标题.txt" # 打开文件夹,读取内容,并进行分词 with open(filename, 'r', encoding='gb18030') as f: for line in f.readlines(): word = jieba.cut(line) for i in word: final = final + i + " " # print(final) print('jieba分词成功') except: return 'jieba分词失败' try: # 使用worldcould制作词云 # 打开文本 text = open('top100标题.txt').read() # 生成对象 wc = WordCloud(font_path='C:\Windows\Fonts\simfang.ttf', width=800, height=600, mode='RGBA', background_color=None).generate(text) # 显示词云 plt.imshow(wc, interpolation='bilinear') plt.axis('off') plt.show() # 保存到文件 wc.to_file('标题词云.png') # 生成图像是透明的 print('保存词云成功') except: return '保存词云失败' def watch(): # 数据分析与可视化,包括绘制折线图,柱形图,直方图,散点图 try: # 获得绘图数据 point = pd.read_csv('top100.csv', engine='python', encoding="GBK") # print(data.isnull().sum) # print(type(point)) # 将字符串数据进行去除替换 rank = point['排名'].values.tolist() points = point['播放量'].values.tolist() # print(points) # 用来正常显示中文标签 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示负号 plt.rcParams['axes.unicode_minus'] = False print('获取绘图数据成功') except: return '获取数据失败' try: # 根据数据绘制折线图 plt.plot(rank, points, c='red', alpha=0.5) # 设置图形的格式 plt.title('哔哩哔哩排名与播放量的关系折线图', fontsize=24) plt.xlabel('排名', fontsize=24) plt.ylabel('播放量', fontsize=12) # 参数刻度线样式设置 plt.tick_params(axis='both', which='major', labelsize=10) # 保存图片 plt.savefig(fname="哔哩哔哩排名与播放量的关系折线图.png", figsize=[10, 10]) # 显示折线图 plt.show() print('折线图保存成功') except: return '折线图保存失败' try: # 根据数据绘制柱形图 # 创建基础图 fig = plt.figure() # 在基础图上仅绘制一个图,括号中的三个参数代表基础图中的统计图布局,参数一次代表:图的行数量、图的列数量、第几个图。本例中,为1行1列,第一个图 bar1 = fig.add_subplot(1, 1, 1) # 绘制柱形图,align表示条形与标签中间对齐。 bar1.bar(rank, points, align='center', color="blue") # 设置x、y轴标签 plt.xlabel("排名") plt.ylabel("播放量") # 设置统计图标题 plt.title("哔哩哔哩排名与播放量的关系柱形图") # 保存图片 plt.savefig(fname="哔哩哔哩排名与播放量的关系柱形图.png", figsize=[10, 10]) # 显示统计图 plt.show() print('柱形图保存成功') except: return '柱形图保存失败' try: # 绘制直方图 # 绘制基础图 fig = plt.figure() hist1 = fig.add_subplot(1, 1, 1) # 绘制直方图 # bins=50 表示每个变量的 值应该被分成 50 份。normed=False 表示直方图显示的是频率分布 hist1.hist(points, bins=50, color="blue", density=False) # 确定坐标轴位置 hist1.xaxis.set_ticks_position("bottom") hist1.yaxis.set_ticks_position("left") # 设置坐标轴标签 plt.xlabel("排名") plt.ylabel("播放量") # 设置标题 plt.title("哔哩哔哩排名与播放量的关系直方图") # 保存图片 plt.savefig(fname="哔哩哔哩排名与播放量的关系直方图.png", figsize=[10, 10]) # 显示图形 plt.show() print('直方图保存成功') except: return '直方图保存失败' try: # 绘制散点图 fig = plt.figure() scatter1 = fig.add_subplot(1, 1, 1) # 导入数据 scatter1.scatter(rank, points) # 确定坐标轴位置 scatter1.xaxis.set_ticks_position('bottom') scatter1.yaxis.set_ticks_position('left') # 设置坐标轴标签 plt.xlabel("排名") plt.ylabel("播放量") # 设置图表标题 plt.title("哔哩哔哩排名与播放量的关系散点图") # 保存图片 plt.savefig(fname="哔哩哔哩排名与播放量的关系散点图.png", figsize=[10, 10]) # 显示图形 plt.show() print('散点图保存成功') except: return '散点图保存失败' if __name__ == '__main__': get_rank() rubbish() message() watch()代码运行结果:
生成能持久保存的文件如下
五.总结
1.经过对主体数据的分析与可视化,可以得到那些结论?是否达到预期目标? 对哔哩哔哩动画中播放量的爬取及数据可视乎,基本完成了目标即对视频播放量的前100到可视化显示,了解了用户对新型有趣话题的兴趣较深,视频开发者可以以此推论,将话题变为大众了解且有趣的,使得既能做到在情理之中,又出乎意料。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议? (1)自己的数据分析这方面不太足,解析标签提取数据还比较生疏,要勤加练习。 (2)建议以多点进行展示,例如视频点赞量,视频转载量,视频下载量等多方面进行拓展,这样能更明确用户对视频的喜好及其学习方向等等。 |



【本文地址】