| 列表(list)、元组(tuple)、字典(dictionary)、array(数组) | 您所在的位置:网站首页 › 列表数组字典集合的区别 › 列表(list)、元组(tuple)、字典(dictionary)、array(数组) |
列表(list)、元组(tuple)、字典(dictionary)、array(数组)
|
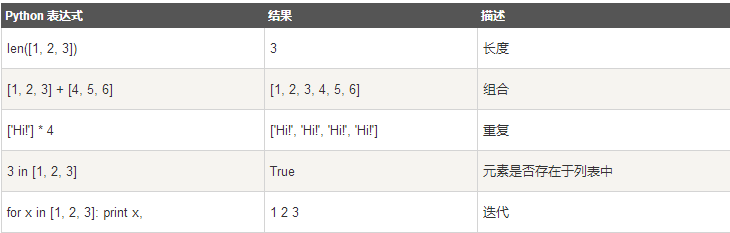
一、列表(list) 一组有序项目的集合。可变的数据类型【可进行增删改查】 列表是以方括号“[]”包围的数据集合,不同成员以“,”分隔。 列表中可以包含任何数据类型,也可包含另一个列表 列表可通过序号访问其中成员 Python列表脚本操作符列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
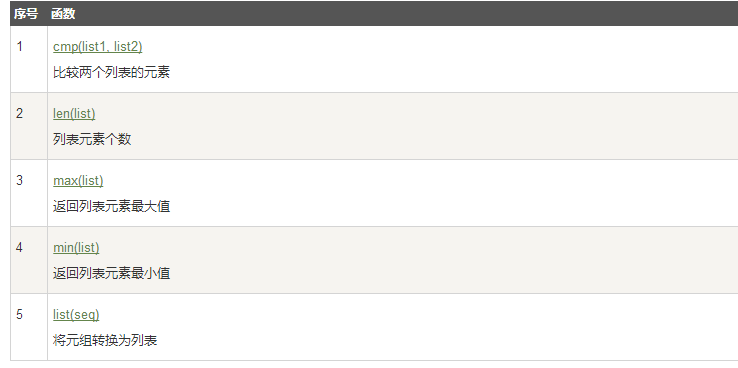
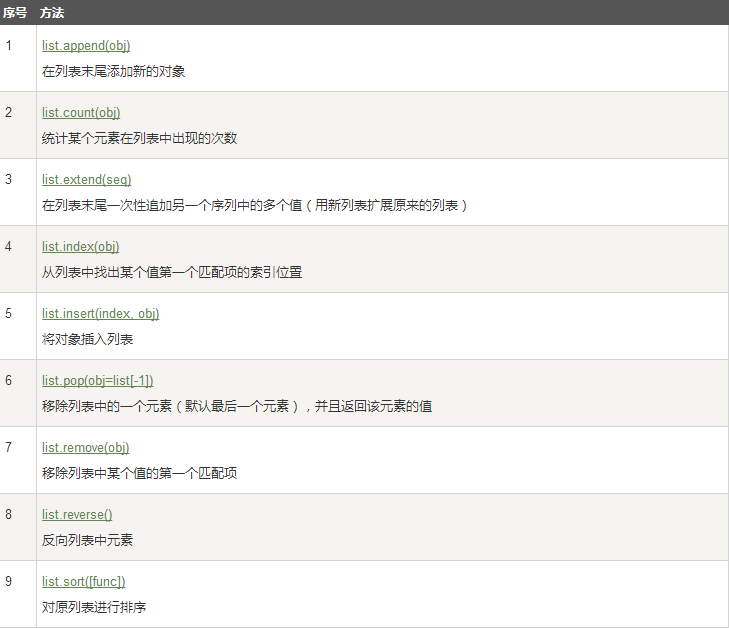
Python列表函数&方法
n=[1,2,3,4,5,6] m=[7,8,9,10] n.extend(m) print n out:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 7, 8, 9, 10] n.index(5)out:4 #列表操作补充--切片操作 example = [0,1,2,3,4,5,6,7,8,9] #打印某一区间 左闭右开 print(example[4:8]) #想包含最后一个 print(example[4:]) #包含首个 print(example[:8]) #所有的 print(example[:]) #第三个参数为步长 print(example[1:8:2]) #倒序输出 print(example[::-1]) #列表合并 a = [1,2,3] b = [4,5,6] print(a+b) #替换 ex = [1,2,3,4,5,6] ex[4:]=[9,8,7] print(ex)#将56换为987 >>> list4=[123,["das","aaa"],234] >>> list4 >>> "aaa" in list4 #in只能判断一个层次的元素 False >>> "aaa" in list4[1] #选中列表中的列表进行判断 True >>> list4[1][1] 'aaa'
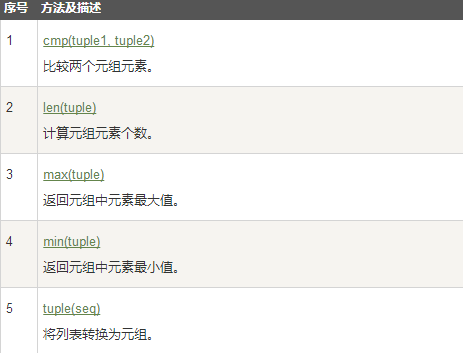
二、元组(tuple) 不可变序列 元组是以圆括号“()”包围的数据集合,不同成员以“,”分隔 与列表不同:元组中数据一旦确立就不能改变 通过下标进行访问 声明: L=(1,2,3) 含0个元素的元组: L = () 含1个元素的元组:L=(1,) 注意有逗号 访问元组: o =('a','b','c',('d1','d2')) print o[0] print o[3][0] a d1 age=22 name='sandra' print'%s is %d years old'%(name,age) sandra is 22 years old修改元组:元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例: tup1 = (12, 34.56); tup2 = ('abc', 'xyz'); # 以下修改元组元素操作是非法的。 # tup1[0] = 100; # 创建一个新的元组 tup3 = tup1 + tup2; print tup3;删除元组: del tup1添加元组: #通过切片方法添加a=(1,2,3,4,5,6) a=a[:2]+(10,)+a[2:] a Out:(1, 2, 10, 3, 4, 5, 6)元组运算符 与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
无关闭分隔符 任意无符号的对象,以逗号隔开,默认为元组,如下实例: print 'abc', -4.24e93, 18+6.6j, 'xyz'; x, y = 1, 2; print "Value of x , y : ", x,y; 元组内置函数
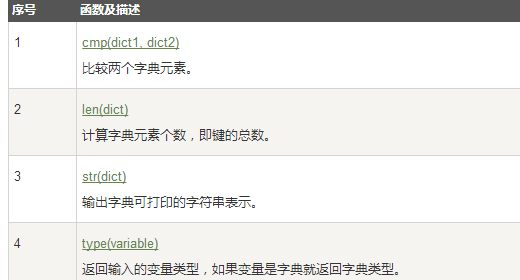
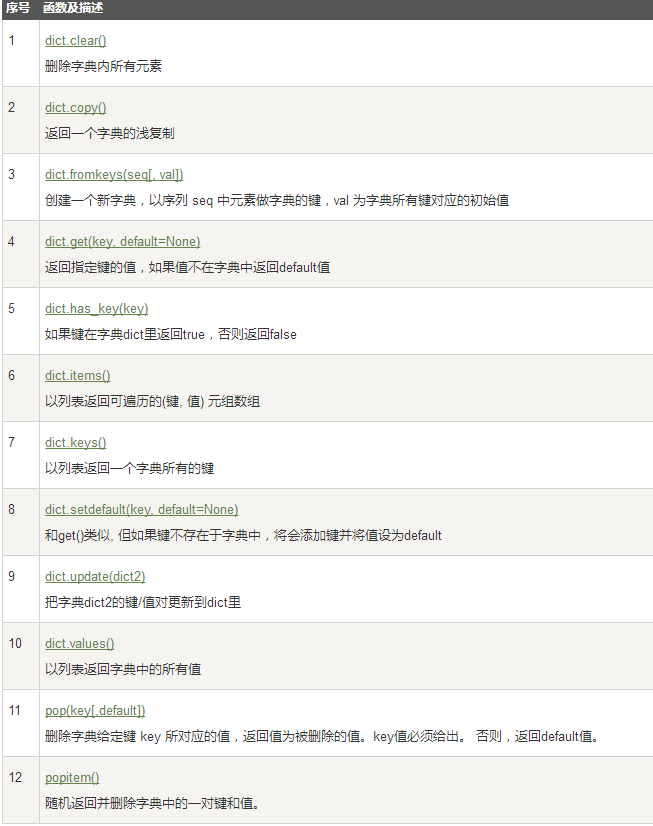
三、字典(dictionary) 字典是另一种可变容器模型,且可存储任意类型对象。 字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示: d = {key1 : value1, key2 : value2 }键必须是唯一的,但值则不必。 值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。 访问字典里的值 dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}; dict['Name'] dict['Age'] 修改字典 dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}; dict['Age'] = 8; dict['School'] = "DPS School" 删除字典元素能删单一的元素也能清空字典,清空只需一项操作。 显示删除一个字典用del命令,如下实例: dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}; del dict['Name']; # 删除键是'Name'的条目 dict.clear(); # 清空词典所有条目 del dict ; # 删除词典 字典键的特性字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。 两个重要的点需要记住: 1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例: dict = {'Name': 'Zara', 'Age': 7, 'Name': 'Manni'}; print "dict['Name']: ", dict['Name']; dict['Name']: Manni2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行,如下实例: dict = {['Name']: 'Zara', 'Age': 7}; print "dict['Name']: ", dict['Name']; 字典内置函数&方法
四、array(数组)--numpy python中的list是python的内置数据类型,list中的数据类不必相同的,而array的中的类型必须全部相同。在list中的数据类型保存的是数据的存放的地址,简单的说就是指针,并非数据,这样保存一个list就太麻烦了,例如list1=[1,2,3,'a']需要4个指针和四个数据,增加了存储和消耗cpu。numpy中封装的array有很强大的功能,里面存放的都是相同的数据类型 1)numpy array 必须有相同数据类型属性 ,Python list可以是多种数据类型的混合 2)numpy array有一些方便的函数 3)numpy array数组可以是多维的 二维numpy数组 mean(),std()等函数,在二维数组中,这些函数将在整个数组上运行 b=np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]]) print b b.mean() [[ 1 2 3] [ 4 5 6] [ 7 8 9] [10 11 12]]6.5 b.reshape(2,6) #这里的数字相乘等于12,可以任意reshape array([[ 1, 2, 3, 4, 5, 6], [ 7, 8, 9, 10, 11, 12]])numpy轴 b.mean(axis=0) #列 array([ 5.5,6.5,7.5]) b.mean(axis=1) #行 array([2.,5.,8.,11.]) 五、dataframe-pandas定义:DataFrame提供的是一个类似表的结构,由多个Series组成,而Series在DataFrame中叫columns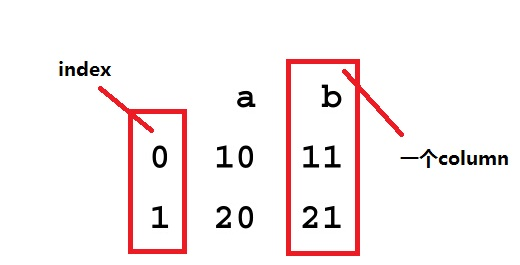
import pandas as pd from pandas import Series, DataFrame import numpy as np data = DataFrame(np.arange(15).reshape(3,5),index=['one','two','three'],columns=['a','b','c','d','e']) print data a b c d e one 0 1 2 3 4 two 5 6 7 8 9 three 10 11 12 13 14 二维array: import pandas as pd import numpy as np s1=np.array([1,2,3,4]) s2=np.array([5,6,7,8]) df=pd.DataFrame([s1,s2]) print df
使用.ix[] df.ix[条件,then操作区域] df.ix[df.a>1,'b']=9 print df a b 0 1 5 1 2 9 2 3 9 3 4 9 使用numpy.where,添加新列‘then’np.where(条件,then,else) df['new']=np.where(df.a=2] print df 使用.loc[] df=pd.DataFrame({"A":[1,2,3,4],"B":[5,6,7,8],"C":[1,1,1,1]}) df=df.loc[df.A>2] print df Grouping groupby 形成group df = pd.DataFrame({'animal': 'cat dog cat fish dog cat cat'.split(), 'size': list('SSMMMLL'), 'weight': [8, 10, 11, 1, 20, 12, 12], 'adult' : [False] * 5 + [True] * 2}); #列出动物中weight最大的对应size group=df.groupby("animal").apply(lambda subf: subf['size'][subf['weight'].idxmax()]) print group
使用get_group 取出其中一分组 df = pd.DataFrame({'animal': 'cat dog cat fish dog cat cat'.split(), 'size': list('SSMMMLL'), 'weight': [8, 10, 11, 1, 20, 12, 12], 'adult' : [False] * 5 + [True] * 2}); group=df.groupby("animal") cat=group.get_group("cat") print catpandas series vs numpy array 1.pandas series可以通过describe()函数打出均值等 data.describe() 2.pandas series 和numpy array的区别还包括:pandas series有索引 七、集合(set())集合中包含一系列的元素,在Python中这些元素不需要是相同的类型,且这些元素在集合中是没有存储顺序的。 集合的赋值集合的表示方法是花括号,这与字典是一样的,可以通过括号或构造函数来初始化一个集合,如果传入的参数有重复,会自动忽略: >>> {1,2,"hi",2.23} {2.23, 2, 'hi', 1} >>> set("hello") {'l', 'h', 'e', 'o'}注:由于集合和字典都用{}表示,所以初始化空的集合只能通过set()操作,{}只是表示一个空的字典 集合的增加集合元素的增加支持两种类型,单个元素的增加用add方法,对序列的增加用update方法。add的作用类似列表中的append,而update类似extend方法。update方法可以支持同时传入多个参数: >>> a={1,2} >>> a.update([3,4],[1,2,7]) >>> a {1, 2, 3, 4, 7} >>> a.update("hello") >>> a {1, 2, 3, 4, 7, 'h', 'e', 'l', 'o'} >>> a.add("hello") >>> a {1, 2, 3, 4, 'hello', 7, 'h', 'e', 'l', 'o'} 集合的删除集合删除单个元素有两种方法,两者的区别是在元素不在原集合中时是否会抛出异常,set.discard(x)不会,set.remove(x)会抛出KeyError错误: >>> a={1,2,3,4} >>> a.discard(1) >>> a {2, 3, 4} >>> a.discard(1) >>> a {2, 3, 4} >>> a.remove(1) Traceback (most recent call last): File "", line 1, in KeyError: 1集合也支持pop()方法,不过由于集合是无序的,pop返回的结果不能确定,且当集合为空时调用pop会抛出KeyError错误,可以调用clear方法来清空集合: >>> a={3,"a",2.1,1} >>> a.pop() 1 >>> a.pop() 3 >>> a.clear() >>> a set() >>> a.pop() Traceback (most recent call last): File "", line 1, in KeyError: 'pop from an empty set' 集合操作 并集:set.union(s),也可以用a|b计算 交集:set.intersection(s),也可以用a&b计算 差集:set.difference(s),也可以用a-b计算需要注意的是Python提供了一个求对称差集的方法set.symmetric_difference(s),相当于两个集合互求差集后再求并集,其实就是返回两个集合中只出现一次的元素,也可以用a^b计算。 >>> a={1,2,3,4} >>> b={3,4,5,6} >>> a.symmetric_difference(b) {1, 2, 5, 6} 1 2 3 4set.update(s)操作相当于将两个集合求并集并赋值给原集合,其他几种集合操作也提供各自的update版本来改变原集合的值,形式如intersection_update(),也可以支持多参数形式。 包含关系两个集合之间一般有三种关系,相交、包含、不相交。在Python中分别用下面的方法判断: set.isdisjoint(s):判断两个集合是不是不相交 set.issuperset(s):判断集合是不是包含其他集合,等同于a>=b set.issubset(s):判断集合是不是被其他集合包含,等同于a和>> a = frozenset("hello") >>> a frozenset({'l', 'h', 'e', 'o'}) 1 2 3需要注意的是frozenset仍然可以进行集合操作,只是不能用带有update的方法。如果要一个有frozenset中的所有元素的普通集合,只需把它当作参数传入集合的构造函数中即可: 集合的一大特性:没有重复值 set1={1,2,3,2,2,3,4} print type(set1) print set1 set1.add(6) print set1 set([1, 2, 3, 4]) set([1, 2, 3, 4, 6])
|

【本文地址】