| 【机器学习:数据集拆分】机器学习数据集的训练、验证、测试拆分 | 您所在的位置:网站首页 › 划分数据集的必要性 › 【机器学习:数据集拆分】机器学习数据集的训练、验证、测试拆分 |
【机器学习:数据集拆分】机器学习数据集的训练、验证、测试拆分
|
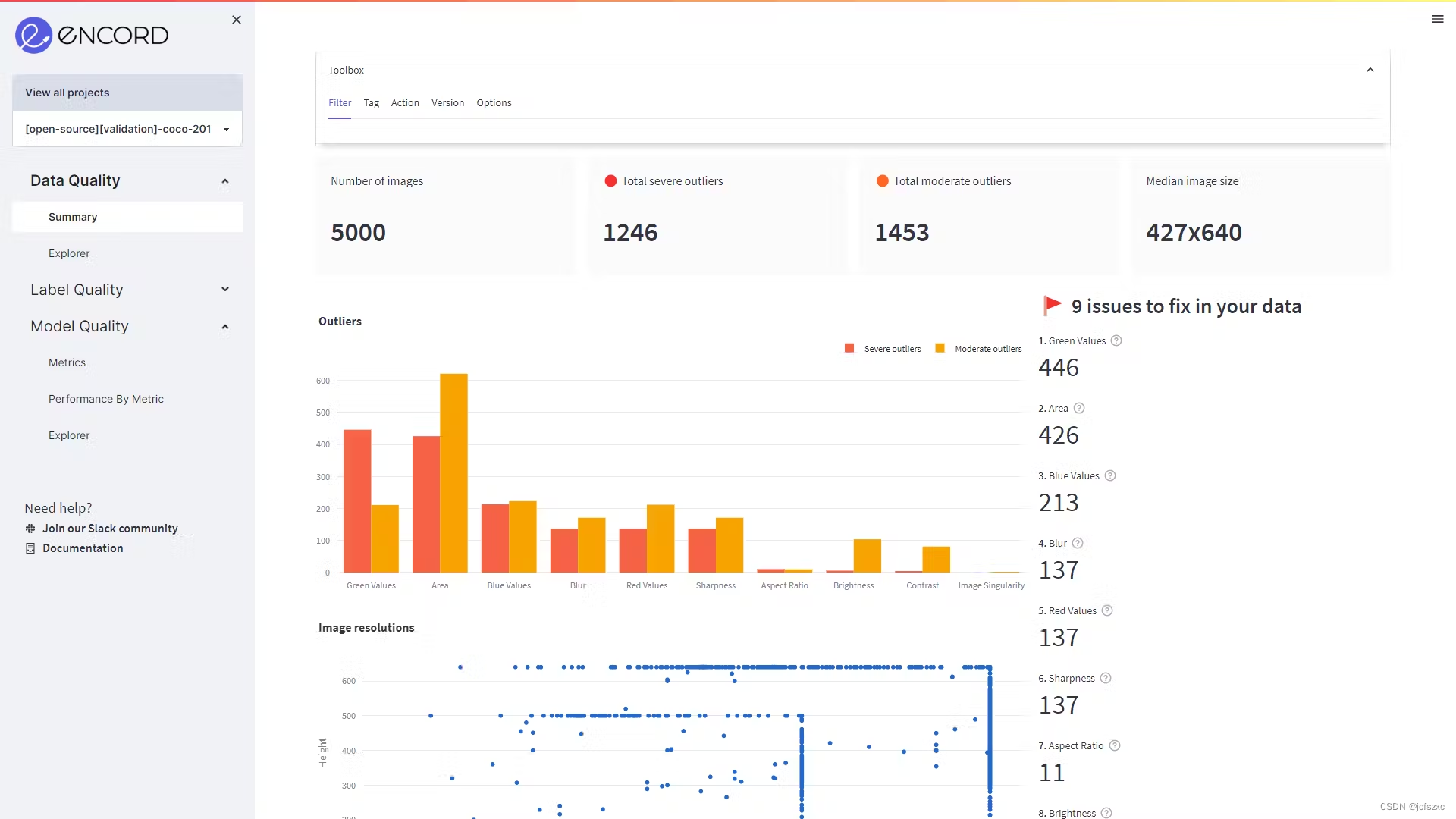
训练-验证-测试分离对于开发稳健且可靠的机器学习模型至关重要。 非常简单地说: 目标:创建一个能够很好地泛化新数据的神经网络座右铭:永远不要在测试数据上训练模型前提是直观的——避免使用相同的数据集来训练您用来评估它的机器学习模型。这样做将导致模型存在偏差,该模型会针对其训练的数据集报告人为的高模型准确性,而针对任何其他数据集报告的模型准确性较差。 为了确保机器学习算法的通用性,将数据集分为三个部分至关重要:训练集、验证集和测试集。这将使您能够通过确保用于训练模型的数据集和用于评估模型的数据集不同来实际衡量模型的性能。 在本文中,我们概述了: 训练集、验证集、测试集分割机器学习数据集的 3 种方法分割机器学习数据集时要避免的 3 个错误如何使用 Encord 进行计算机视觉中的训练、验证和测试拆分要点 训练集、验证集、测试集在我们深入研究机器学习模型的训练-验证-测试分割的最佳实践之前,让我们定义三组数据。 训练集训练集是为拟合模型而保留的数据集部分。换句话说,模型查看训练集中的数据并从中学习,以直接改进其参数。 为了最大限度地提高模型性能,训练集必须 (i) 足够大以产生有意义的结果(但不能太大以至于模型过度拟合)并且 (ii) 能够代表整个数据集。这将使经过训练的模型能够预测未来可能出现的任何未见过的数据。 当机器学习模型过于专业化和适应训练数据而无法概括并对新数据做出正确预测时,就会发生过度拟合。因此,过拟合模型在训练集上表现优异,但在验证集和测试集上表现不佳。 验证集验证集是在训练期间用于评估和微调机器学习模型的数据集,有助于评估模型的性能并进行调整。 通过在验证集上评估经过训练的模型,我们可以深入了解其泛化到未见过的数据的能力。此评估有助于识别潜在问题,例如过度拟合,这可能会对模型在现实场景中的性能产生重大影响。 验证集对于超参数调整也至关重要。超参数是控制模型行为的设置,例如学习率或正则化强度。通过试验不同的超参数值,在训练集上训练模型,并使用验证集评估其性能,我们可以确定产生最佳结果的最佳超参数组合。这个迭代过程对模型进行微调并最大限度地提高其性能。 测试装置测试集是用于评估训练模型最终性能的数据集。 它可以公正地衡量模型对未见过的数据的泛化程度,评估其在现实场景中的泛化能力。通过在整个开发过程中保持测试集独立,我们获得了模型性能的可靠基准。 测试数据集还有助于衡量经过训练的模型处理新数据的能力。由于它代表模型以前从未遇到过的未见过的数据,因此评估模型在测试集上的拟合度为其实际适用性提供了一个公正的指标。此评估使我们能够确定经过训练的模型是否已成功学习相关模式,并且可以在训练和验证上下文之外做出准确的预测。 分割机器学习数据集的 3 种方法机器学习模型的数据集分割方法有多种。正确的数据分割方法和最佳分割比率都取决于多个因素,包括用例、数据量、数据质量和超参数的数量。 随机抽样划分数据集最常见的方法是随机抽样。顾名思义,该方法涉及对数据集进行混洗,并根据预定的比例将样本随机分配到训练集、验证集或测试集。对于类平衡数据集,随机采样可确保分割无偏差。 虽然随机采样是解决许多机器学习问题的最佳方法,但对于不平衡数据集来说,它并不是正确的方法。当数据由倾斜的类别比例组成时,随机抽样几乎肯定会在模型中产生偏差。 分层数据集分割分层数据集分割是一种常用于不平衡数据集的方法,其中某些类或类别的实例明显少于其他类或类别。在这种情况下,确保训练、验证和测试集充分代表类别分布以避免最终模型出现偏差至关重要。 在分层分割中,数据集被分割,同时保留分割中每个类的相对比例。因此,训练、验证和测试集包含每个类别的代表性子集,保持原始类别分布。通过这样做,模型可以学习识别模式并对所有类别进行预测,从而形成更强大、更可靠的机器学习算法。 交叉验证分割交叉验证采样是一种用于将数据集拆分为训练集和验证集以进行交叉验证的技术。它涉及创建数据的多个子集,每个子集在交叉验证过程的不同迭代期间用作训练集或验证集。 K 折交叉验证和分层 k 折交叉验证是常用技术。通过利用这些交叉验证采样技术,研究人员和机器学习从业者可以获得更可靠、更公正的机器学习模型性能指标,使他们能够在模型开发和选择过程中做出更明智的决策。 数据拆分时要避免的 3 个错误数据科学家和机器学习工程师在分割数据集进行模型训练时会犯一些常见的陷阱。 样本量不足训练、验证或测试集中的样本量不足可能会导致模型性能指标不可靠。如果训练集太小,模型可能无法捕获足够的模式或不能很好地概括。同样,如果验证集或测试集太小,性能评估可能缺乏统计意义。 数据泄露当验证集或测试集的信息无意中泄漏到训练集中时,就会发生数据泄漏。这可能会导致性能指标过于乐观,并对最终模型的准确性产生夸大的感觉。为了防止数据泄漏,确保训练集、验证集和测试集之间的严格分离至关重要,确保模型训练期间不使用评估集中的信息。 不正确的随机播放或排序在分割之前错误地对数据进行洗牌或排序可能会引入偏差并影响最终模型的泛化。例如,如果数据集在分成训练集和验证集之前没有随机洗牌,则可能会引入模型在训练期间可以利用的偏差或模式。因此,经过训练的模型可能会过度拟合这些特定模式,并且无法很好地泛化到新的、未见过的数据。 如何使用 Encord 进行训练、验证和测试拆分要开始机器学习项目,Encord 的平台可用于数据拆分。 要下载 Encord Active,请在您首选的 Python 环境中运行以下命令: python3.9 -m venv ea-venv source ea-venv/bin/activate # within venv pip install encord-active或者,运行以下命令以使用 GitHub 安装 Encord Active: pip install git+https://github.com/encord-team/encord-active要确认 Encord Active 已安装,请运行以下命令: encord-active --helpEncord Active 拥有许多沙盒数据集,例如 COCO、Rareplanes、BDD100K、TACO 数据集等等。这些沙箱数据集通常在计算机视觉应用程序中用于构建基准模型。 Encord Active 安装完成后,请使用以下命令下载 COCO 数据集: encord-active download该脚本会提示您选择一个项目,导航选项 ↓ 和 ↑ 选择 COCO 数据集,然后按 Enter。这里引用的 COCO 数据集与 COCO 网页中提到的 COCO 验证数据集相同。此数据集用于演示 Encord Active 如何轻松过滤和拆分数据集。 要在浏览器中可视化数据,请运行以下命令: cd /path/to/downloaded/project encord-active visualize下面显示的图像是在浏览器中打开的网页,其中显示了数据及其属性。让我们检查一下属性:
COCO 数据集包含 5000 张图像,其中 3500 张图像用于训练集,1000 张图像用于验证集,500 张图像用于测试集。 该过滤器可用于根据图像的特征选择图像,确保数据子集是平衡的。 如下图所示,在“数据质量→资源管理器”中,使用这些功能筛选出图像。
通过“工具箱”中的“操作”选项卡,单击“创建子集”以创建新的训练子集。您可以下载 CSV 或 COCO 格式的子集,也可以在 Encord 平台中使用它来训练和评估您的机器学习模型。 与训练子集类似,创建验证集和测试集。请记住选择相同的功能,但按不同的值进行过滤,以避免数据泄露。 训练、验证和测试集:关键要点以下是关键要点: 为了创建能够很好地泛化到新数据的模型,请务必将数据拆分为训练集、验证集和测试集,以防止在用于训练模型的相同数据上评估模型。训练集数据必须足够大,以捕获数据中的变异性,但又不能太大,以至于模型过度拟合训练数据。最佳分流比取决于各种因素。训练-验证-测试拆分的粗略标准是 60-80% 的训练数据、10-20% 的验证数据和 10-20% 的测试数据。 常见问题解答 什么是训练测试拆分?训练-测试拆分是机器学习中的一种技术,其中数据集分为两个子集:训练集和测试集。训练集用于训练模型,而测试集用于评估最终模型的性能和泛化能力。 验证集的用途是什么?在最终确定之前,验证集可以对模型在看不见的数据上的性能进行公正的评估。它有助于微调模型的超参数、选择最佳模型并防止过度拟合。 为什么拆分数据很重要?请务必将数据拆分为训练集和测试集,以评估机器学习算法的模型性能和泛化能力。通过使用单独的集合,您可以在看不见的数据上模拟模型的性能,检测过拟合,优化模型参数,并在部署之前就其有效性做出明智的决策。 什么是过拟合?当机器学习模型在训练数据上表现良好,但无法泛化到新的、看不见的数据时,就会发生过度拟合。当经过训练的模型从训练集中学习噪声或不相关的模式时,就会发生这种情况,从而导致模型在测试集或验证集上的性能不佳。 什么是交叉验证?交叉验证是一种用于评估机器学习算法的模型性能和泛化能力的技术。它涉及将数据集划分为多个子集或折叠。机器学习模型在这些子集的组合上进行训练,同时在其余子集上进行测试。重复此过程,并对性能指标进行平均以评估模型性能。 |

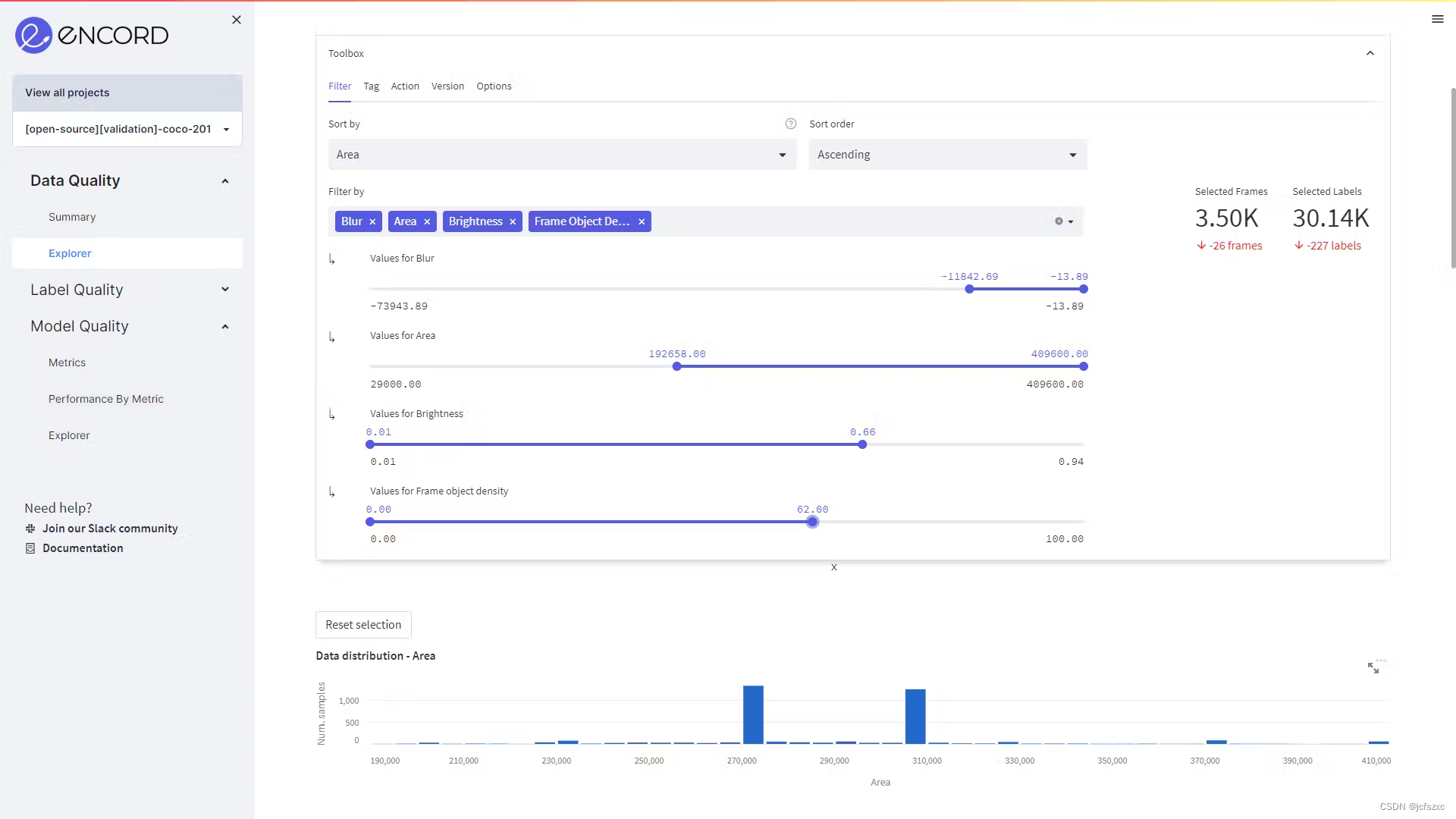 根据训练集的模糊、面积、亮度和帧对象密度值筛选数据集
根据训练集的模糊、面积、亮度和帧对象密度值筛选数据集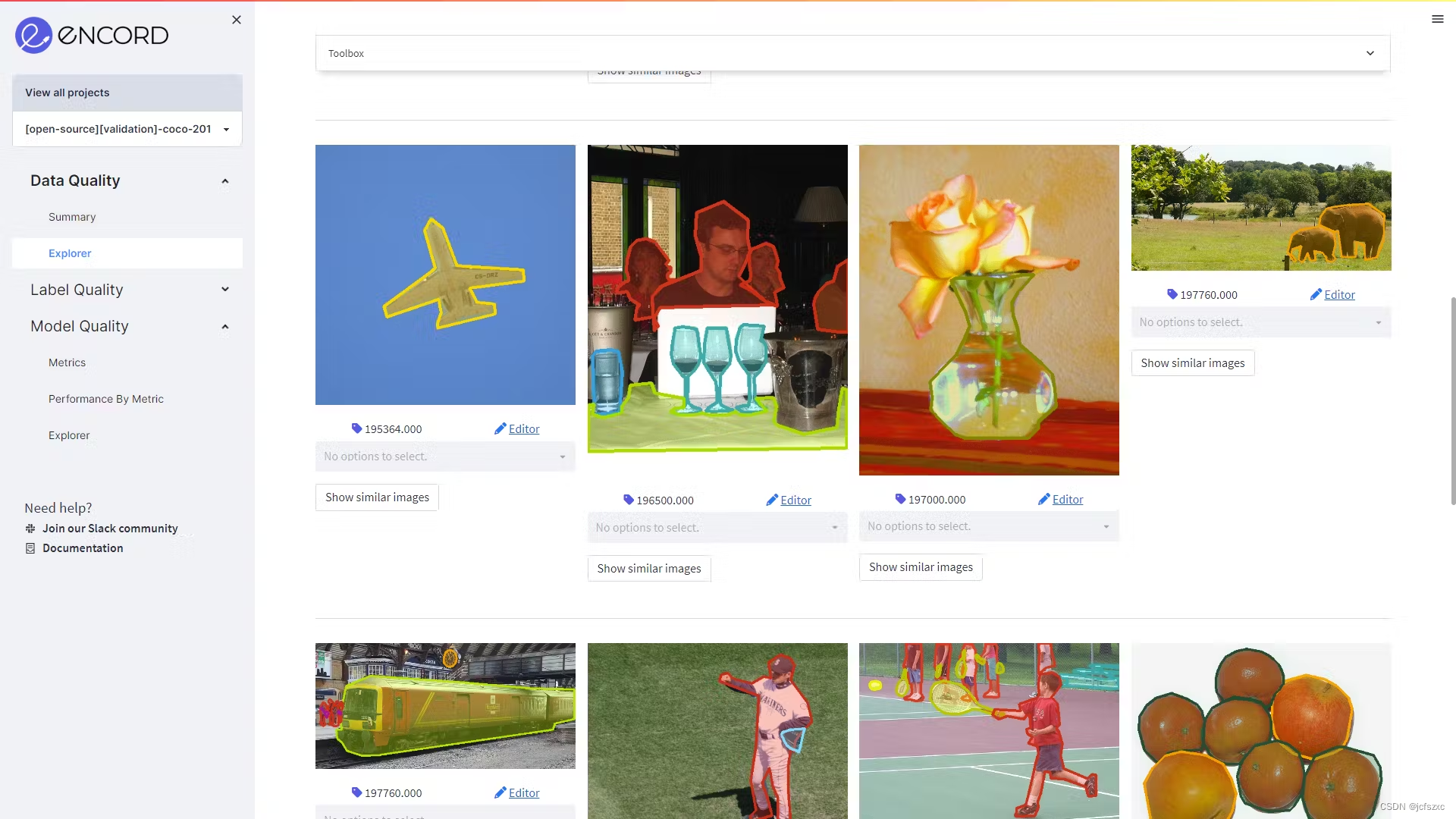
【本文地址】