| 软考 | 您所在的位置:网站首页 › 分布式数据架构 › 软考 |
软考
|
版权声明
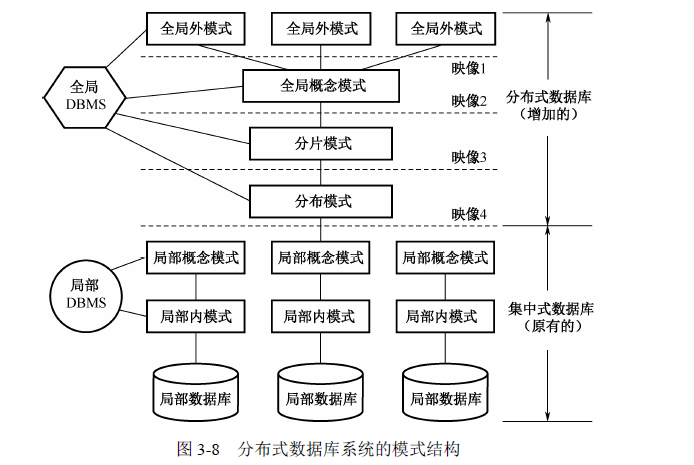
主要针对希赛出版的架构师考试教程《系统架构设计师教程(第4版)》,作者“希赛教育软考学院”。完成相关的读书笔记以便后期自查,仅供个人学习使用,不得用于任何商业用途。 版权声明第十三节 分布式数据库系统架构 概念结构分布式数据库系统与并行数据库系统的区别 应用目标不同实现方式不同各结点的地位不同最主要的区别 数据分片和透明性 分片分片的方式 分布透明性 分片透明性是分布透明性的最高层次位置透明性是分布透明性的下一层次局部数据模型透明性 分布式数据库管理系统的任务 DDBMS 组成 LDBMS(局部 DBMS)GDBMS(全局 DBMS)全局数据字典CM(Communication Management,通信管理) 架构方案 全局控制集中的 DDBMS全局控制分散的 DDBMS全局控制、部分分散的 DDBMS 第十三节 分布式数据库系统架构 概念结构分布式数据库系统的模式结构有六个层次。 图 3-8 的模式结构从整体上可以分为两大部分:下半部分是集中式数据库的模式结构,代表了各局部场地上局部数据库系统的基本结构;上半部分是分布式数据库系统增加的模式级别。 (1)全局外模式。它们是全局应用的用户视图,是全局概念模式的子集。 (2)全局概念模式。它定义分布式数据库中数据的整体逻辑结构,数据就如同根本没有分布一样,可用传统的集中式数据库中所采用的方法定义。全局概念模式中所用的数据模型应该易于向其他层次的模式映像,通常采用关系模型。这样,全局概念模式包括一组全局关系的定义。 (3)分片模式。每一个全局关系可以划分为若干不相交的部分,每一部分称为一个片段,即“数据分片”。分片模式就是定义片段及全局关系到片段的映像。这种映像是一对多的,即每个片段来自一个全局关系,而一个全局关系可对应多个片段。 (4)分布模式。由数据分片得到的片断仍然是 DDB 的全局数据,是全局关系的逻辑部分,每一个片段在物理上可以分配到网络的一个或多个不同结点上。分布模式定义片段的存放结点。分布模式的映像类型确定了分布式数据库是冗余的还是非冗余的。若映像是一对多的,即一个片段分配到多个结点上存放,则是冗余的分布数据库,否则是不冗余的分布数据库。 根据分布模式提供的信息,一个全局查询可分解为若干子查询,每一子查询要访问的数据属于同一场地的局部数据库。由分布模式到各局部数据库的映像(映像 4)把存储在局部场地的全局关系或全局关系的片段映像为各局部概念模式采用局部场地的 DBMS 所支持的数据模型。 分片模式和分布模式均是全局的,分布式数据库系统中增加的这些模式和相应的映像使分布式数据库系统具有了分布透明性。 (5)局部概念模式。一个全局关系经逻辑划分成一个或多个逻辑片断,每个逻辑片断被分配在一个或多个场地上,称为该逻辑片断在某场地上的物理映像或物理片断。分配在同一场地上的同一个全局概念模式的若干片断(物理片断)构成了该全局概念在该场地上的一个物理映像。 一个场地上的局部概念模式是该场地上所有全局概念模式在该场地上物理映像的集合。由此可见,全局概念模式与场地独立,而局部概念模式与场地相关。 (6)局部内模式。局部内模式是 DDB 中关于物理数据库的描述,类似于集中式 DB 中的内模式,但其描述的内容不仅包含局部本场地的数据的存储描述,还包括全局数据在本场地的存储描述。 这种分层的模式结构为理解 DDB 提供了一种通用的概念结构。它有三个显著的特征: (1)数据分片和数据分配概念的分离,形成了“数据分布独立型”概念。 (2)数据冗余的显示控制。数据在各个场地的分配情况在分配模式中一目了然,便于系统管理。 (3)局部 DBMS 的独立性。这个特征也称为“局部映射透明性”。此特征允许在不考虑局部 DBMS 专用数据模型的情况下研究 DDB 管理的有关问题。 分布式数据库系统与并行数据库系统的区别分布式数据库系统与并行数据库系统具有很多相似点:它们都是通过网络连接各个数据处理结点的,整个网络中的所有结点构成一个逻辑上统一的整体,用户可以对各个结点上的数据进行透明存取等。但分布式数据库系统与并行数据库系统之间还是存在着显著的区别的。 应用目标不同并行数据库系统的目标是充分发挥并行计算机的优势,利用系统中的各个处理机结点并行地完成数据库任务,提高数据库的整体性能。分布式数据库系统主要目的在于实现各个场地自治和数据的全局透明共享,而不要求利用网络中的各个结点来提高系统的整体性能。 实现方式不同由于应用目标各不相同,在具体实现方法上,并行数据库与分布式数据库之间也有着较大的区别。在并行数据库中,为了充分发挥各个结点的处理能力,各结点间采用高速通信网络互联,结点间数据传输代价相对较低。当负载不均衡时,可以将工作负载过大的结点上的任务通过高速通信网络送给空闲结点处理,从而实现负载平衡。在分布式数据库系统中,各结点(场地)间一般通过局域网或广域网互联,网络带宽比较低,各场地之间的通信开销较大,因此在查询处理时一般应尽量减少结点间的数据传输量。 各结点的地位不同在并行数据库中,各结点之间不存在全局应用和局部应用的概念。各个结点协同作用,共同处理,而不可能有局部应用。 最主要的区别在分布式数据库系统中,各结点除了能通过网络协同完成全局事务外,还有自己结点场地的自治性。也就是说,分布式数据库系统的每个场地又是一个独立的数据库系统,除了拥有自己的硬件系统(CPU、内存和磁盘等)外,还拥有自己的数据库和自己的客户,可运行自己的 DBMS,执行局部应用,具有高度的自治性。 数据分片和透明性 分片将数据分片,使数据存放的单位不是关系而是片段,这既有利于按照用户的需求较好地组织数据的分布,也有利于控制数据的冗余度。 分片的方式水平分片和垂直分片是两种基本的分片方式,混合分片和导出分片是较复杂的分片方式。 分布透明性用户不必关心数据的逻辑分片,不必关心数据存储的物理位置分配细节,也不必关心局部场地上数据库的数据模型。 分布透明性包括:分片透明性、位置透明性和局部数据模型透明性。 分片透明性是分布透明性的最高层次所谓分片透明性是指用户或应用程序只对全局关系进行操作而不必考虑数据的分片。当分片模式改变时,只要改变全局模式到分片模式的映像(映像2),而不影响全局模式和应用程序。全局模式不变,应用程序不必改写,这就是分片透明性。 位置透明性是分布透明性的下一层次所谓位置透明性是指,用户或应用程序应当了解分片情况,但不必了解片段的存储场地。当存储场地改变时,只要改变分片模式到分配模式的映像(映像 3),而不影响应用程序。同时,若片段的重复副本数目改变了,那么数据的冗余也会改变,但用户不必关心如何保持各副本的一致性,这也提供了重复副本的透明性。 局部数据模型透明性用户或应用程序应当了解分片及各片断存储的场地,但不必了解局部场地上使用的是何种数据模型。 分布式数据库管理系统的任务首先就是把用户与分布式数据库隔离开来,使其对用户而言,整个分布式数据库就好像是一个传统的集中式数据库。换句话说,一个分布式数据库管理系统与用户之间的接口,在逻辑上与集中式数据库管理系统是一致的。但是考虑到分布式数据库的特点,其物理实现上又与集中式数据库不同。下面以一种分布式数据库管理。
局部场地上的数据库管理系统的功能是建立和管理局部数据库,提供场地自治能力、执行局部应用及全局查询的子查询。 GDBMS(全局 DBMS)全局数据库管理系统的主要功能是提供分布透明性,协调全局事务的执行,协调各局部 DBMS 以完成全局应用,保证数据库的全局一致性,执行并发控制,实现更新同步,提供全局恢复功能。 全局数据字典存放全局概念模式、分片模式、分布模式的定义及各模式之间映像的定义;存放有关用户存取权限的定义,以保证全局用户的合法权限和数据库的安全性;存放数据完整性约束条件的定义,其功能与集中式数据库的数据字典类似。 CM(Communication Management,通信管理)在分布数据库各场地之间传送消息和数据,完成通信功能。 架构方案 全局控制集中的 DDBMS这种结构的特点是全局控制成分 GDBMS 集中在某一结点上,由该结点完成全局事务的协调和局部数据库转换等一切控制功能,全局数据字典只有一个,也存放在该结点上,它是 GDBMS 执行控制的依据。它的优点是控制简单,易实现更新一致性。但由于控制集中在某一特定的结点上,不仅容易形成瓶颈而且系统较脆弱,一旦该结点出故障,整个系统就会瘫痪。 全局控制分散的 DDBMS这种结构的特点是全局控制成分 GDBMS 分散在网络的每一个结点上,全局数据字典也在每个结点上有一份,每个结点都能完成全局事务的协调和局部数据库转换,每个结点既是全局事务的参与者又是协调者,一般称这类结构为完全分布的 DDBMS。它的优点是结点独立,自治性强,单个结点退出或进入系统均不会影响整个系统的运行,但是全局控制的协调机制和一致性的维护都比较复杂。 全局控制、部分分散的 DDBMS这种结构是根据应用的需要将 GDBMS 和全局数据字典分散在某些结点上,是介于前两种情况之间的架构。 局部 DBMS 的一个重要性质是:局部 DBMS 是同构的还是异构的。同构和异构的级别可以有三级:硬件、操作系统和局部 DBMS。其中最主要的是局部 DBMS 这一级,因为硬件和操作系统的不同将由通信软件处理和管理。 异构型 DDBMS 的设计和实现比同构型 DDBMS 更加复杂,它要解决不同的 DBMS 之间及不同的数据模型之间的转换。因此在设计和实现 DDBMS 时,若是用自顶向下的方法进行,即并不存在已运行的局部数据库,则采用同构型的结构比较方便。若是采用自底向上设计 DDBMS 的方法,即现已存在的局部数据库,而这些数据库可能采用不同的数据模型(层次、网状或关系),或者虽然模型相同但它们是不同厂商的 DBMS(如 Informix、 Sybase、Db2、Oracle),这就必须开发异构型的DDBMS。要解决异构数据库模型的同种化问题,是研制异构型 DDBMS 的关键所在,所谓同种化就是寻找合适的公共数据模型,采用公共数据模型与异构数据模型(局部)之间的转换,不采用各结点之间的一对一转换。这样可以减少转移次数。设有 N 个结点,用公共数据模型时转换次数为 2N,而各结点之间一对一转换则需 N(N1)次。 |

【本文地址】