| 往hive导入查询数据全为NULL,但导入过程无报错,mysql/postgresql | 您所在的位置:网站首页 › 出现null › 往hive导入查询数据全为NULL,但导入过程无报错,mysql/postgresql |
往hive导入查询数据全为NULL,但导入过程无报错,mysql/postgresql
|
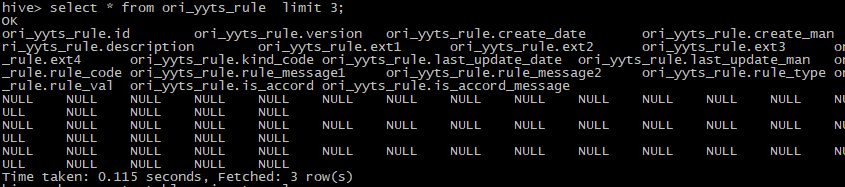
今天导数遇到一个问题,通过sqoop import从 postgresql导数据到hive中后,发现查询出来全部都是空的: 执行过程中也没有报错,顺利导入数据: #运行日志(部分): ....... File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=869101 19/06/06 11:32:16 INFO mapreduce.ImportJobBase: Transferred 848.7314 KB in 24.4734 seconds (34.6797 KB/sec) 19/06/06 11:32:16 INFO mapreduce.ImportJobBase: Retrieved 1266 records. 19/06/06 11:32:16 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM "rule" AS t LIMIT 1 19/06/06 11:32:16 WARN hive.TableDefWriter: Column create_date had to be cast to a less precise type in Hive 19/06/06 11:32:16 WARN hive.TableDefWriter: Column last_update_date had to be cast to a less precise type in Hive 19/06/06 11:32:16 INFO hive.HiveImport: Loading uploaded data into Hive 19/06/06 11:32:17 INFO hive.HiveImport: Hive import complete.那为什么会导致导入的数据全为NULL呢? 原因是在于,建hive表是设定的分割符不恰当,跟从postgresql导入过来的数据的分隔符不一样,所以导致hive切分不了数据,于是查询为空,但是这个过程,是不属于导入失败的,所以导入命令没有报错。 因为sqoop import实际上是把数据存放到hdfs对应路径上了,而不是“直接导入表里”,查询时,hive会从hdfs的路径上提取数据,再根据hive表的结构和定义,来向我们展示出类似表格的形式。因此,导入过程是不会报错的,但是因为hive定义的分隔符和存在hdfs上数据的分隔符不一致,所以查询是全为NULL的。 那么,是怎么样的不一样呢? 我们先来查询一下原来hive表的建表语句,用show create table xxxx即可: hive> show create table ori_yyts_rule; OK createtab_stmt CREATE TABLE `ori_yyts_rule`( `id` int, `version` int, `create_date` string, `create_man` string, `description` string, `ext1` string, `ext2` string, `ext3` string, `ext4` string, `kind_code` string, `last_update_date` string, `last_update_man` string, `rule_code` string, `rule_message1` string, `rule_message2` string, `rule_type` string, `rule_val` string, `is_accord` string, `is_accord_message` string) COMMENT 'rule_code explanation' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://dthost21:8020/user/hive/warehouse/lmj_test.db/ori_yyts_rule' TBLPROPERTIES ( 'COLUMN_STATS_ACCURATE'='true', 'numFiles'='5', 'numRows'='0', 'rawDataSize'='0', 'totalSize'='869101', 'transient_lastDdlTime'='1559791620') Time taken: 0.214 seconds, Fetched: 37 row(s)可以看到分隔符为:FIELDS TERMINATED BY '\t',而从postgresql或者mysql来的数据的分隔符则应该为:FIELDS TERMINATED BY '\u0001',那我们只要改回来就可以正常导入了。 这里有个小窍门,其实用sqoop import 从postgresql或者mysql导数据时,会在hive上自动建表,建表时的分隔符也会自动设为FIELDS TERMINATED BY '\u0001'。 引申一下,这个问题还会经常出现在从txt、excel或者其他数据源导入hive表这种场景下,原因其实都是原来的数据的分隔方式和hive表定义的不一致,大家以后遇到相似问题可以有意识地思考一下这种可能性。 |
 检查导入命令,没有错啊:
检查导入命令,没有错啊:【本文地址】
公司简介
联系我们