| 大数据毕业设计:基于python旅游景点推荐+酒店推荐系统+爬虫+Django框架 计算机毕业设计(附源码)✅ | 您所在的位置:网站首页 › 出境游旅社推荐理由 › 大数据毕业设计:基于python旅游景点推荐+酒店推荐系统+爬虫+Django框架 计算机毕业设计(附源码)✅ |
大数据毕业设计:基于python旅游景点推荐+酒店推荐系统+爬虫+Django框架 计算机毕业设计(附源码)✅
|
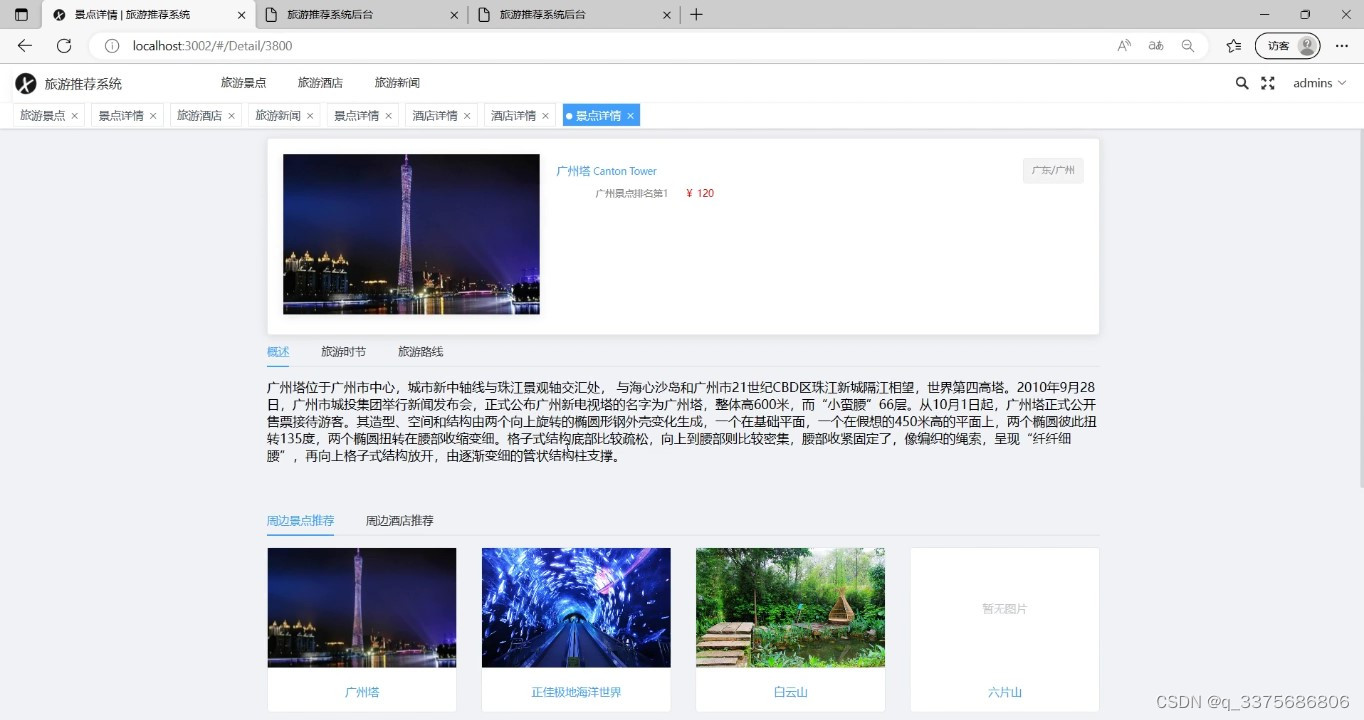
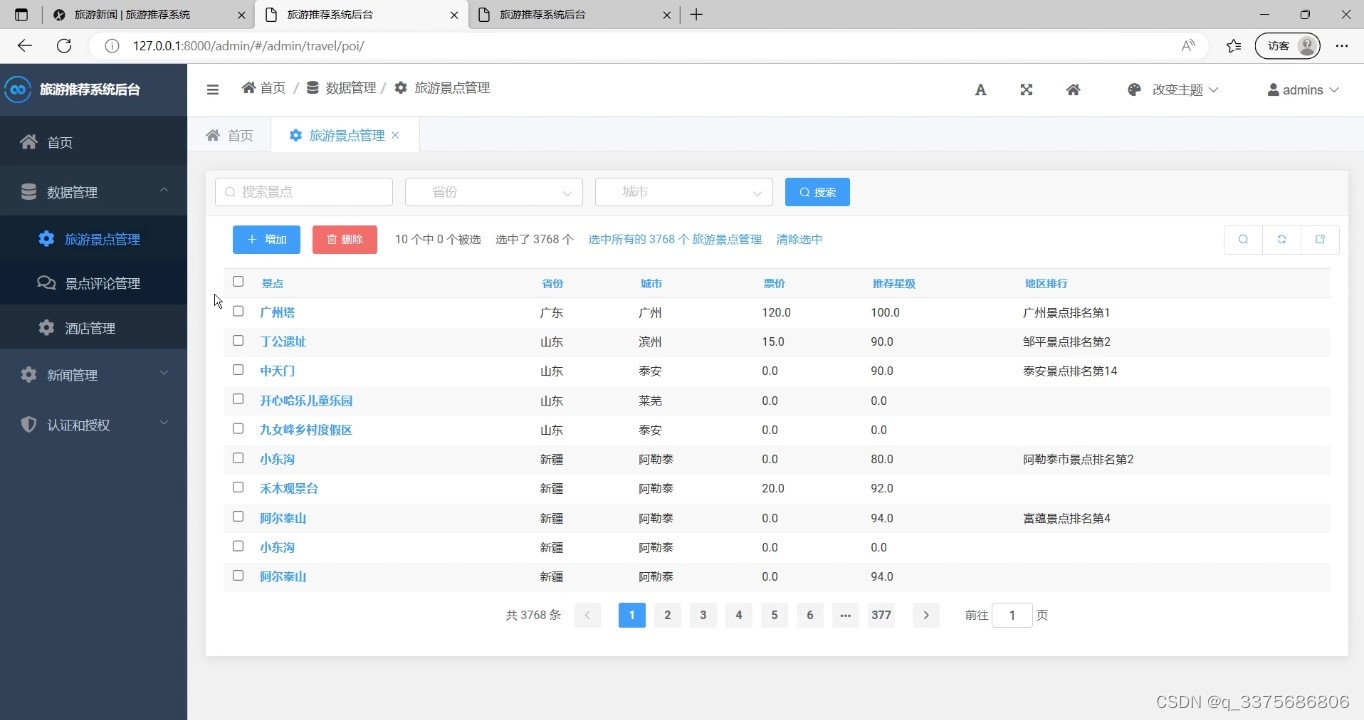
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏) 毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总 🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅 1、项目介绍技术栈: Django框架、scrapy爬虫、vue前端框架、MySQL数据库、去哪儿网景点信息、艺龙旅行酒店信息 旅游和酒店推荐系统是基于用户的旅游偏好和需求,利用各种数据和算法,为用户提供个性化的旅游和酒店推荐服务。该系统整合了Django框架、scrapy爬虫、vue前端框架、MySQL数据库以及去哪儿网景点信息和艺龙旅行酒店信息等技术和数据资源。 后端技术栈(python): - django - django-simpleui 后台ui框架 - mysql 数据库 - sqlite3 数据库 数据爬虫(python): - scrapy 爬虫框架 - requests 轻量爬虫工具 - xpath 页面数据抽取 前端技术栈(nodejs+vue3): - vue3 - element-plus vue3组件库 - element-plus-admin 页面框架 2、项目界面(1)旅游景点详情
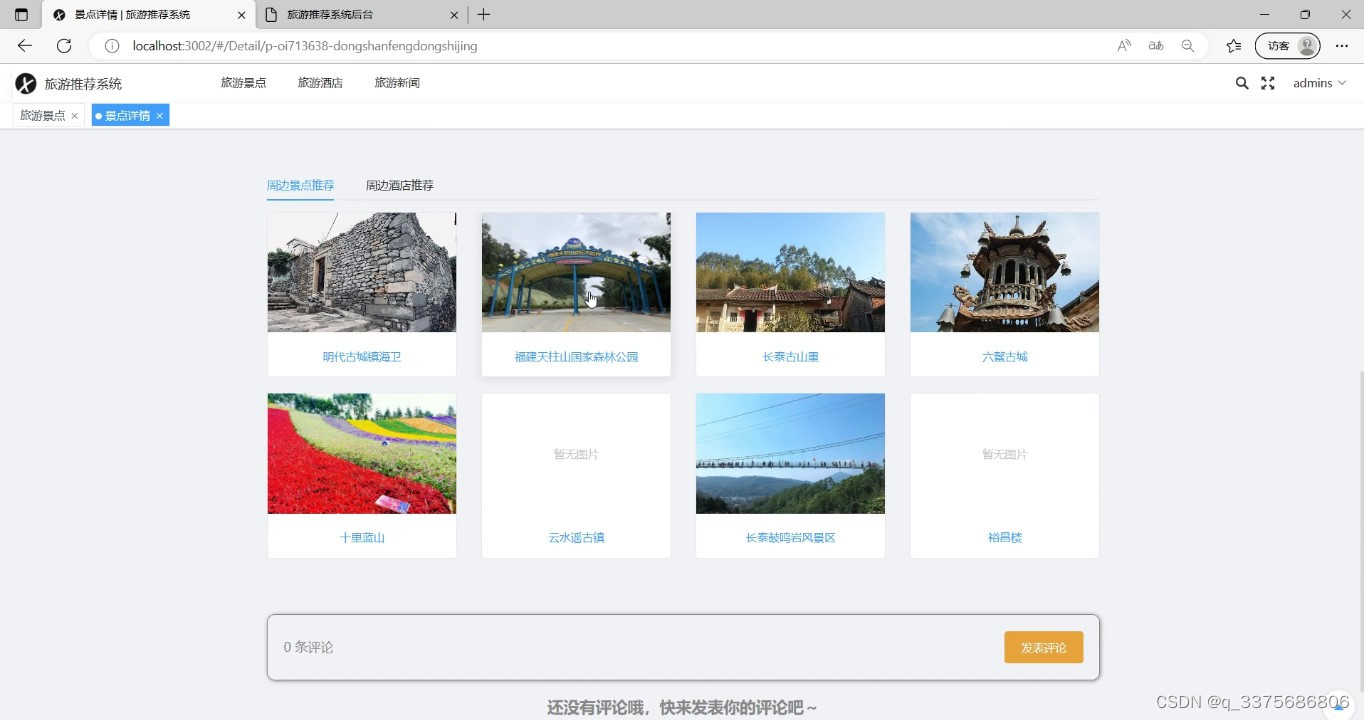
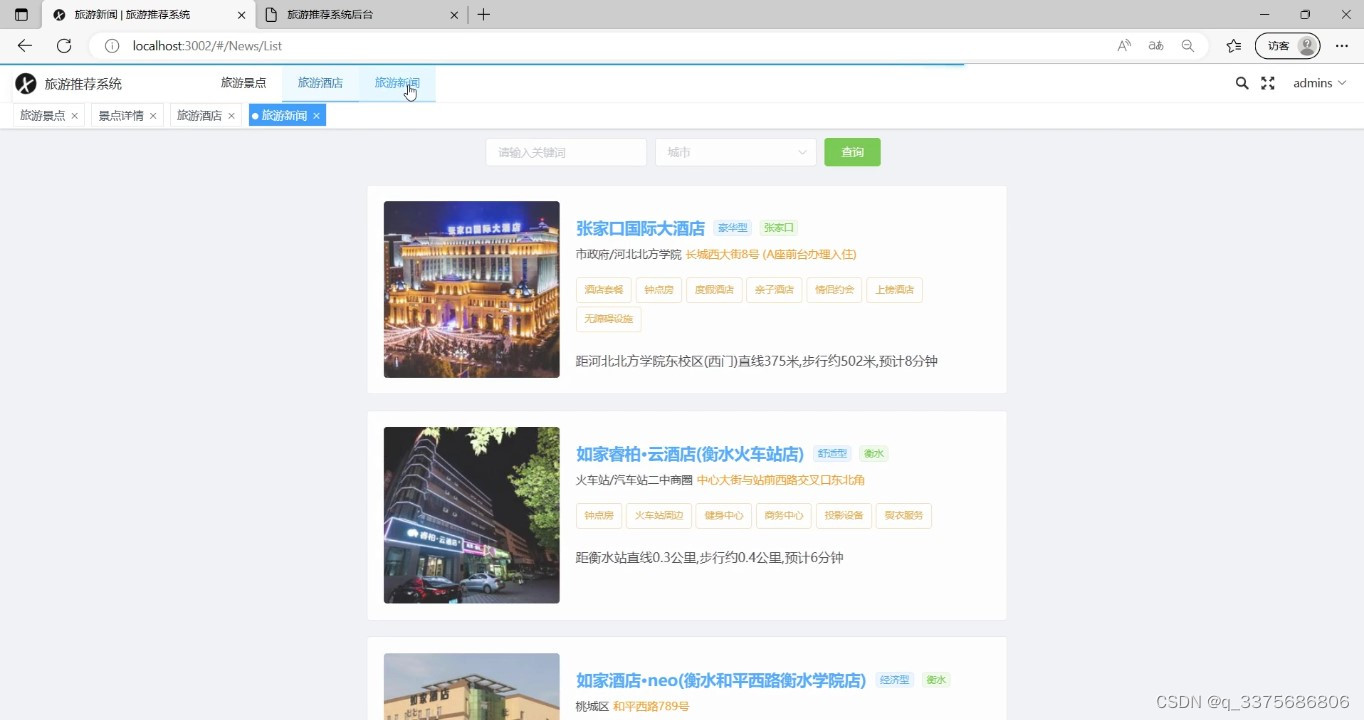
(2)景点推荐 (3)旅游酒店页面
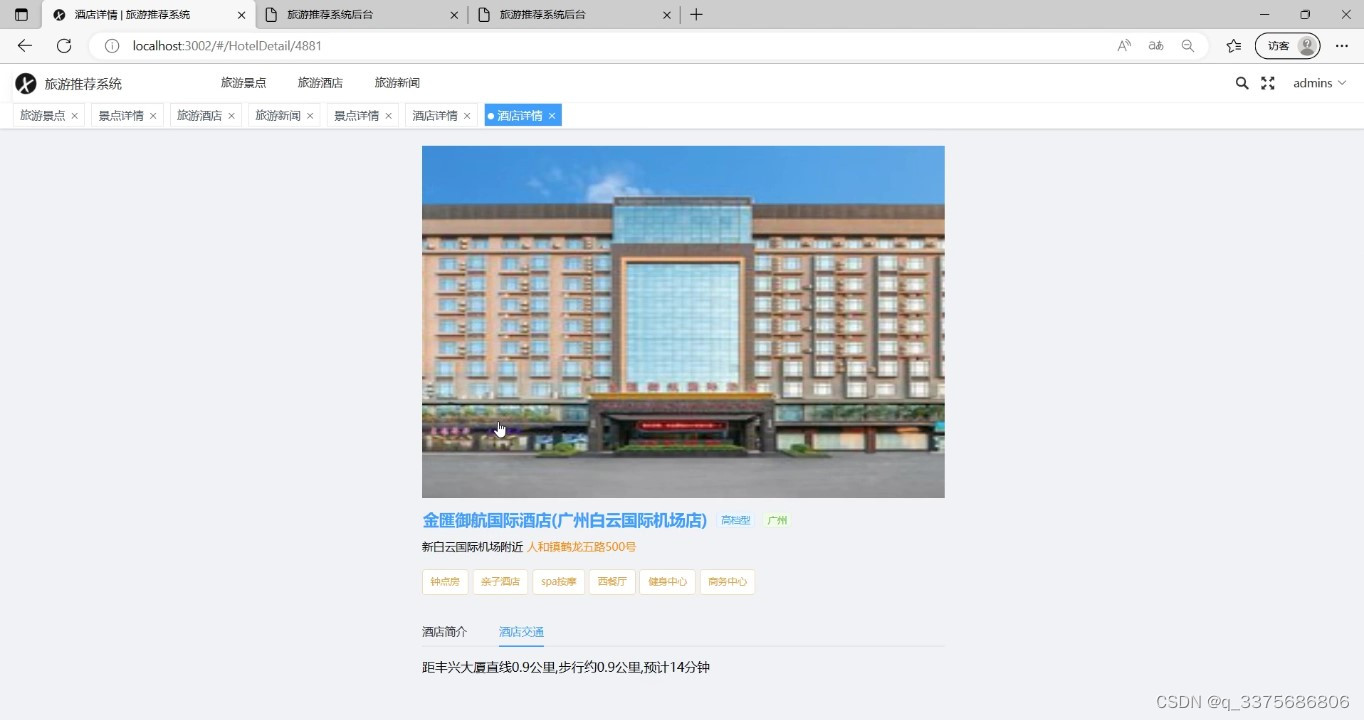
(4)酒店详情页面
(5)后台数据管理
(6)酒店信息管理
旅游和酒店推荐系统是基于用户的旅游偏好和需求,利用各种数据和算法,为用户提供个性化的旅游和酒店推荐服务。该系统整合了Django框架、scrapy爬虫、vue前端框架、MySQL数据库以及去哪儿网景点信息和艺龙旅行酒店信息等技术和数据资源。 首先,通过scrapy爬虫技术,系统可以定期从去哪儿网和艺龙旅行等旅游网站上获取最新的景点和酒店信息,并将其存储在MySQL数据库中。这些数据包括景点的名称、地址、介绍、评分等信息,以及酒店的名称、地理位置、价格、评分等信息。 然后,通过Django框架搭建系统的后端服务,包括用户管理、数据处理和推荐算法等功能。用户可以注册、登录和管理个人信息,系统可以根据用户的浏览历史、收藏夹、评分等数据,利用推荐算法为用户提供个性化的旅游和酒店推荐。 最后,通过vue前端框架搭建系统的前端界面,用户可以通过网页或移动端应用访问系统,并进行旅游和酒店的搜索、浏览、收藏和预订等操作。用户可以根据自己的需求和偏好,通过系统的推荐功能找到适合自己的旅游景点和酒店。 综上所述,旅游和酒店推荐系统利用Django框架、scrapy爬虫、vue前端框架、MySQL数据库以及去哪儿网景点信息和艺龙旅行酒店信息等技术和数据资源,为用户提供个性化的旅游和酒店推荐服务,提升用户的旅游体验和满意度。 4、核心代码 from django.shortcuts import get_object_or_404, render from django.core.paginator import Paginator from django.db.models import Q from lxml.html import HtmlComment from auth.views import login_required from .models import * from index.utils import success import simplejson from requests_html import HTMLSession from django.contrib.auth.models import User import re # Create your views here. def as_dict(objs): def _todict(o): r = {k: v for k, v in o.__dict__.items() if not k.startswith('_')} r['star'] = 20 return r return [_todict(i) for i in objs] def get_pois(request): try: data = simplejson.loads(request.body) except: data = {} keyword = data.get('keyword', '') city = data.get('city', '') ticket_min = data.get('ticket_min', None) ticket_max = data.get('ticket_max', None) page = data.get('page', 1) pagesize = data.get('pagesize', 9) orderby = data.get('orderby', 'en_name') filters = [] if keyword: filters.append(Q(name__contains=keyword) | Q(prov=keyword) | Q(city=keyword)) if city: filters.append(Q(city=city)) if ticket_min is not None: filters.append(Q(ticket__gte=ticket_min)) if ticket_max is not None: filters.append(Q(ticket__lte=ticket_max)) pois = Poi.objects.filter( *filters).exclude(img__contains="flight-feed").order_by('-star') pg = Paginator(pois, pagesize) page_obj = pg.get_page(page) data = dict(records=as_dict(page_obj.object_list), total=pg.count) return success(data) def get_comments(request): data = request.json pois = Comment.objects.filter(poi_id=data.get( 'poi_id')).order_by('-created_time') pg = Paginator(pois, data.get("pagesize", 5)) page_obj = pg.get_page(data.get("page", 1)) data = dict(records=as_dict(page_obj.object_list), total=pg.count) return success(data) def add_comment(request): data = request.json comment = Comment.objects.create(username=request.user.username, uid=request.user.id, poi_id=data.get( "poi_id"), text=data.get("text")) return success(as_dict([comment])[0]) def get_related_pois(request): data = request.json city = data.get('city') poi_id = data.get('poi_id') pois = Poi.objects.filter(city=city).exclude( poi_id=poi_id, img__contains="flight-feed").order_by('?')[:8] return success(as_dict(pois)) def get_top_pois(request): pois = Poi.objects.exclude(img__contains="flight-feed").order_by('?')[:6] return success(as_dict(pois)) def get_poi(request, poi_id): obj = get_object_or_404(Poi, poi_id=poi_id) result = as_dict([obj])[0] session = HTMLSession() res = session.get(obj.link) try: result['lysj'] = res.html.find('#lysj', first=True).html except: result['lysj'] = '暂无数据' try: result['jtzn'] = res.html.find('#jtzn', first=True).html except: result['jtzn'] = '暂无数据' try: gs = res.html.find('#gs', first=True).html short = res.html.find('#short', first=True) if short: gs = gs.replace(short.html, '').replace('收起', '') result['gs'] = gs except: result['gs'] = '暂无数据' return success(result) def get_hotel_list(request): try: data = simplejson.loads(request.body) except: data = {} not_q = ("total", "page", "pagesize", "keyword") pagesize = data.get("pagesize", 12) page = data.get("page", 1) keyword = data.get("keyword", None) params = {k: v for k, v in data.items() if k not in not_q and v} params_q = Q(**params) if keyword: params_q &= (Q(hotelName__icontains=keyword) | Q( city__icontains=keyword)) objs = Hotel.objects.filter(params_q).order_by("hotelId").all() pg = Paginator(objs, pagesize) page = pg.page(page) dt = dict(records=as_dict(page.object_list), total=pg.count) return success(dt) def get_hotel(request): data = request.json obj = get_object_or_404(Hotel, id=data['id']) return success(as_dict([obj])[0]) 5、源码获取方式🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅 感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻 |
【本文地址】