| MLP神经网络:多层感知机实现波士顿房价预测 | 您所在的位置:网站首页 › 几种激活函数的优劣 › MLP神经网络:多层感知机实现波士顿房价预测 |
MLP神经网络:多层感知机实现波士顿房价预测
|
1、引言
本文我们将介绍如何实现多层感知机(MLP)来预测波士顿房价。 通过本文,将介绍一个完整的建模流程,包括如何清洗数据、探索数据、预处理数据以及建立一个强大的MLP模型来预测波士顿房价。还将展示如何评估模型的性能并对结果进行解释,不仅可以应用于波士顿房价数据集,而且适用于许多其他项目。 本期内容『数据+代码』已上传百度网盘。有需要的朋友可以关注公众号【小Z的科研日常】,后台回复关键词[MLP]获取。 2、数据清洗在开始构建MLP模型之前,首先需要对数据进行清洗。这一步骤非常重要,因为它有助于确保数据的质量和准确性。 首先,观察数据集的形状、列名称、前10行数据以及每一列中唯一值的数量。通过这些信息,我们可以了解数据集的概貌,并发现其中的问题。 # 输出数据集大小 print("[Boston数据集大小:]\n{} rows and {} columns".format(dataframe_one.shape[0], dataframe_one.shape[1])) # 输出数据集各特征名称 print("\n[数据集各特征名称]") print(dataframe_one.columns) # 展示数据集前10行数据 print("\n[数据集前10行数据]") print(dataframe_one.head(10)) # 显示每一列中唯一值的数量 print("[每一列的唯一值]\n") print(dataframe_one.nunique())接下来,我们需要处理缺失值。在本文中,我们将介绍如何找到缺失值并进行填充。此外,我们还将演示如何四舍五入数字数据以提高数据的可读性(本实验不需要四舍五入数字数据)。 print("\n[缺失值填充前]------缺失值总数为{}".format(dataframe_one.isnull().sum().sum())) print("[缺失值填充前]------各栏的缺失值如下:") print(dataframe_one.isnull().sum()) # 将数据中的所有数值转换为数值 dataframe_one = dataframe_one.apply(pd.to_numeric, errors='coerce') # 用10%的修剪平均数来填补数据所有列中的缺失值 dataframe_one = dataframe_one.apply(lambda x: x.fillna(trim_mean(x, 0.1)), axis=0) # 打印数据中缺失值的总数 print("[填充方法]:Trimmed Mean 10%\n") print("[填充缺失值后]------缺失值总数为{}".format(dataframe_one.isnull().sum().sum())) print("[填充缺失值后]------各栏的缺失值如下:") print(dataframe_one.isnull().sum()) #CLEAN: 四舍五入 #本数据集无需四舍五入 print("[本数据集无需四舍五入]")完成这些步骤后,我们可以继续探索我们的数据,并准备将其放入MLP模型中。 3、数据探索分析EDA在进行数据建模之前,我们需要对数据进行一些探索性数据分析(EDA),以确定数据中是否存在某些关联和规律。 在本文中,我们将演示如何使用Spearman相关系数热图和小提琴图来探索波士顿房价数据集。这些图表可以帮助我们了解各个变量之间的相关性,并找出影响房价的最重要因素。
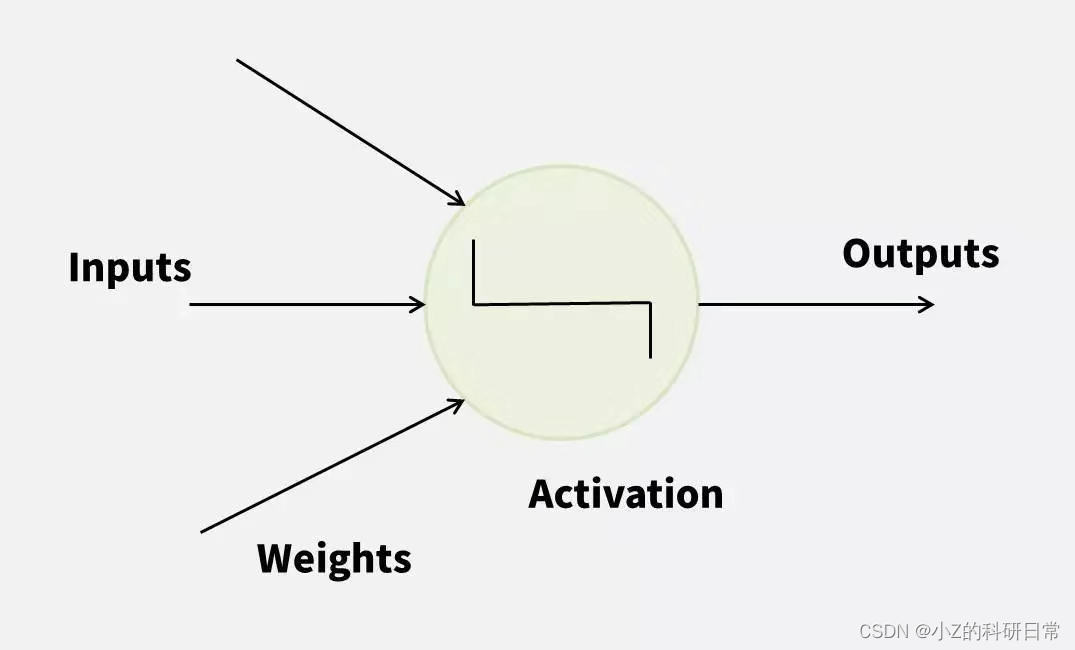
通过相关性热图,我们可以看到所有特征之间的关系。颜色越浅表示相关性越强,而颜色越深则表示相关性越弱。此外,我们还将使用小提琴图来比较不同房屋类型之间的价格差异,并可视化一些必要的统计数据。 4、数据预处理在开始使用多层感知机(MLP)构建模型之前,需要进行一些数据预处理。这一步骤可以帮助我们提高模型的性能和准确性。 在本小节中,将介绍如何进行异常值处理,并创建一个训练/测试集来评估模型性能。此外,我们还将演示如何使用Z-score标准化对数据进行扩展,以便更好地利用它们。 isolation_forest = IsolationForest(n_estimators=100, contamination=0.1, random_state=42) isolation_forest.fit(features) y_noano = isolation_forest.predict(features) cleaned_feature_indices = features.index[y_noano == 1]在异常值处理方面,使用孤立森林算法找到和删除离群点。接下来,我们将随机分配数据集到训练集和测试集中,并将其用于模型训练和评估。最后,我们将使用Z-score标准化缩放数据,使其具有相同的均值和标准差,以便更好地利用它们。 # 使用ZScoreScaler对训练和测试数据进行扩展 scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) print("[使用Z-score缩放器对数据进行缩放]")完成这些步骤后,我们的数据将被清理、处理和准备好,可以供我们使用多层感知机模型进行预测了。 5、多层感知机(MLP) 5.1 神经网络基本知识神经网络由许多人工神经元组成,每个神经元都有多个输入和一个输出。我们可以通过调整它们之间的权重和偏置来训练神经网络,并使其能够准确地预测未来的结果。 下图展示了一个简单的神经元模型:
神经元接收输入x1、x2、...、xn,并将它们与相应的权重w1、w2、...、wn相乘,然后将它们加起来。这个总和加上偏置b并传递给激活函数f(x)。激活函数f(x)产生一个非线性的输出,将其传递给下一层神经元或作为最终输出。 在实际构建神经网络时,通常需要设计多层神经元堆叠而成的结构。MLP就是一种多层神经网络模型,其中包含至少三层神经元:一个输入层、至少一个隐藏层和一个输出层。 下图展示了一个简单的MLP模型:
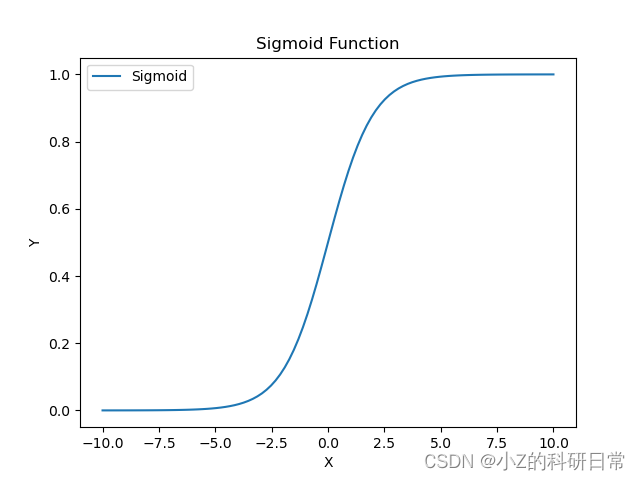
在训练MLP模型时,我们需要自己选择神经元的数量、隐藏层数量以及激活函数类型等超参数。选择适当的超参数可以显著提高模型的性能和准确性。 5.2 激活函数激活函数是神经网络中的一种非线性变换,可以将神经元的输入映射到输出。常用的激活函数包括Sigmoid、ReLU和Tanh等。 Sigmoid函数Sigmoid函数可以将任何实数值映射到[0, 1]区间内的值。 它的公式如下:
Sigmoid函数的图像如下所示:
虽然Sigmoid函数具有很好的性质,但它也存在一些问题。当输入非常大或非常小时,Sigmoid函数的导数趋近于零,这会导致反向传播时梯度消失的问题。 ReLU函数ReLU函数定义为输入为正时返回该输入,否则返回0,即:
ReLU函数的图像如下所示:
ReLU函数有一个明显的优点,就是它可以减轻梯度消失问题。当输入为正数时,导数始终为1,而当输入为负数时,导数为0。因此,ReLU函数在许多神经网络架构中被广泛使用。 Tanh函数Tanh函数可以将任何实数值映射到[-1, 1]区间内的值。它的公式如下:
Tanh函数的图像如下所示:
与Sigmoid函数类似,Tanh函数也存在梯度消失问题。但是,对于某些问题,它可能比Sigmoid函数更适合使用,因为它具有更大的输出范围和更强的非线性特性。 5.3 误差反向传播算法误差反向传播是一种用于训练神经网络的优化方法。它可以通过计算误差梯度来更新神经元之间的权重和偏置,以便更好地预测未来的结果。 在使用误差反向传播算法训练神经网络时,我们首先需要定义一个损失函数(Loss Function),用于衡量模型预测结果与真实数据之间的差距。常见的损失函数包括均方误差(Mean Squared Error)和交叉熵(Cross-Entropy)等。 然后,我们需要使用反向传播算法计算每个神经元的误差梯度,并根据其值更新神经元之间的权重和偏置。 下图展示了一个典型的误差反向传播算法流程:
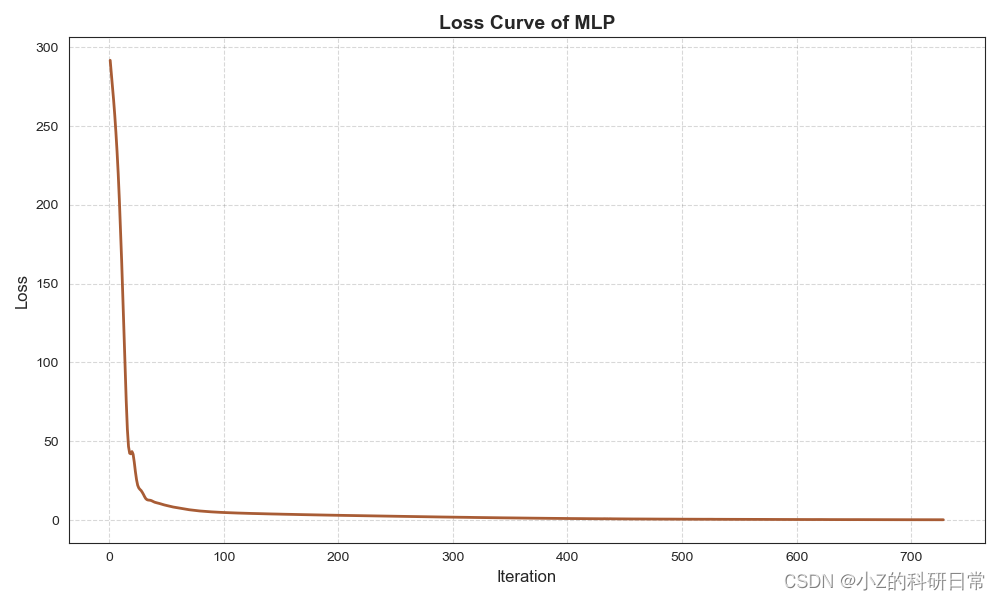
在误差反向传播算法中,我们首先进行前向传播计算,将输入数据x通过神经网络,得到输出y。然后,我们计算损失函数L(Y, Y0),其中Y0是真实数据。接下来,我们通过反向传播计算每个神经元的误差梯度,并使用梯度下降法更新神经元之间的权重和偏置,以最小化损失函数。 5.4 多层感知机(MLP)实现接下来,我们将使用Scikit-learn库中的MLPRegressor类创建一个具有多个隐藏层的MLP模型,并对数据进行训练和预测。我们还将展示如何通过调整超参数和绘制损失函数曲线来优化模型性能,以及如何使用测试集数据来评估模型的准确性。 首先,我们需要将数据集划分为训练集和测试集,然后对数据进行标准化处理: X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)然后,我们使用MLPRegressor类创建一个具有多个隐藏层的MLP模型,并在训练集上拟合该模型: mlp = MLPRegressor(hidden_layer_sizes=(100, 50), activation='relu', solver='adam', max_iter=5000) mlp.fit(X_train_scaled, y_train)我们可以使用score()方法在测试集上评估模型的准确性: score = mlp.score(X_test_scaled, y_test) print("R^2 score:", score)接下来,我们将演示如何使用损失函数曲线来优化模型性能。我们可以通过max_iter参数控制训练次数,并使用validation_fraction参数指定验证集的比例。 mlp = MLPRegressor(hidden_layer_sizes=(100, 50), activation='relu', solver='adam', max_iter=5000, validation_fraction=0.2) mlp.fit(X_train_scaled, y_train) plt.plot(mlp.loss_curve_) plt.title('Loss Curve') plt.xlabel('Iterations') plt.ylabel('Loss') plt.show()绘制出的损失函数曲线如下所示:
我们可以看到,随着训练次数的增加,损失函数逐渐减小,这说明模型正在逐步优化。 最后,我们将使用该模型进行预测,并计算指标,如平均绝对误差、均方误差、均方根误差和R²。这些指标可以帮助我们评估模型的性能和准确性,并为我们提供更好的预测结果。 y_pred = mlp.predict(X_test_scaled) mae = np.mean(np.abs(y_pred - y_test)) mse = np.mean((y_pred - y_test) ** 2) rmse = np.sqrt(mse) r2_score = mlp.score(X_test_scaled, y_test) print("MAE: ", mae) print("MSE: ", mse) print("RMSE: ", rmse) print("R^2 score: ", r2_score) 5.5 MLP结果展示下面是模型评估结果: [训练集指标] 平均绝对误差: 0.38879509574965837 均方误差: 0.40576690833503276 均方根误差: 0.6369983581886477 R²: 0.9947499001495308 [测试集指标] 平均绝对误差: 2.1150030094641554 均方误差: 8.50702069372193 均方根误差: 2.9166797379420886 R²: 0.8301706480358201 损失曲线及拟合曲线如下:
从以上结果可以看出,我们的模型表现良好,能够较准确地预测波士顿房价。同时,在预测曲线中,预测值和真实值非常接近,说明我们的模型具有较高的精度和可靠性。 感谢您阅读本篇文章!如果您对神经网络与深度学习等方面感兴趣,欢迎关注我们的微信公众号(小Z的科研日常)。 |










【本文地址】