| 数据挖掘实战 | 您所在的位置:网站首页 › 八爪鱼采集京东商城评论 › 数据挖掘实战 |
数据挖掘实战
|
文章目录
引言一、评论预处理1.评论去重2.数据清洗
二、评论分词1.分词、词性标注、去除停用词2.提取含名词的评论3.绘制词云查看分词效果
三、构建模型1.评论数据情感倾向分析1.1 匹配情感词1.2 修正情感倾向1.3 查看情感分析效果
2.使用LDA主题模型进行主题分析2.1 建立词典及语料库2.2 寻找最优主题数2.3 评价主题分析结果
案例数据及notebook提取码:1234 传送门: 数据挖掘实战—财政收入影响因素分析及预测数据挖掘实战—航空公司客户价值分析数据挖掘实战—商品零售购物篮分析数据挖掘实战—基于水色图像的水质评价数据挖掘实战—家用热水器用户行为分析与事件识别数据挖掘实战—电商产品评论数据情感分析 引言本文主要针对用户在电商平台上留下的评论数据,对其进行分词、词性标注和去除停用词等文本预处理。基于预处理后的数据进行情感分析,并使用LDA主题模型提取评论关键信息,以了解用户的需求、意见、购买原因及产品的优缺点等,最终提出改善产品的建议。 定义如下挖掘目标: 对京东商城中美的电热水器的评论进行情感分析从评论文本中挖掘用户的需求、意见、购买原因及产品的优缺点根据模型结果给出改善产品的建议定义如下挖掘步骤: 利用Python对京东商城中美的电热水器的评论进行爬取。利用Python爬取的京东商城中美的电热水器的评论数据,对评论文本数据进行数据清洗、分词、停用词过滤等操作。对预处理后的数据进行情感分析,将评论文本数据按照情感倾向分为正面评论数据(好评)和负面评论数据(差评)。分别对正、负面评论数据进行LDA 主题分析,从对应的结果分析文本评论数据中有价值的内容。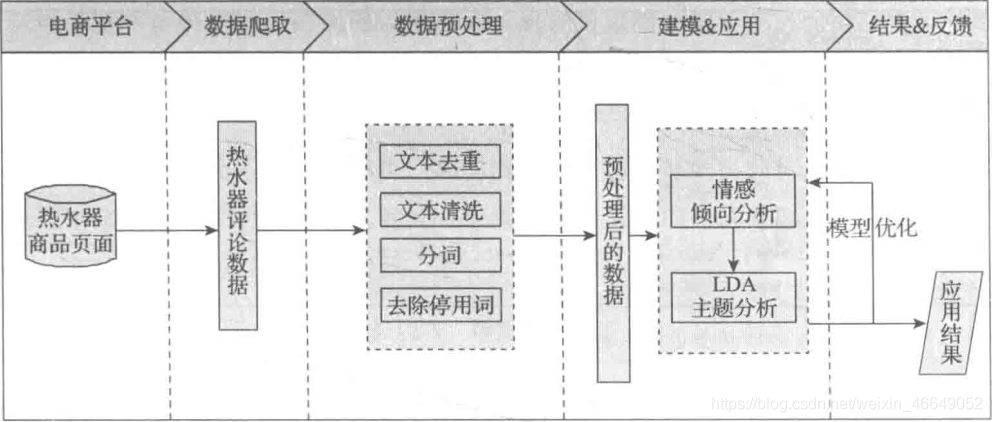 一、评论预处理
1.评论去重
一、评论预处理
1.评论去重
由语言的特点可知,在大多数情况下,不同购买者之间的有价值的评论是不会出现完全重复的,如果不同购物者的评论完全重复,那么这些评论一般都是毫无意义的。显然这种评论中只有最早的评论才有意义(即只有第一条有作用)。有的部分评论相似程度极高,可是在某些词语的运用上存在差异。此类评论即可归为重复评论,若是删除文字相近评论,则会出现误删的情况。由于相近的评论也存在不少有用的信息,去除这类评论显然不合适。因此,为了存留更多的有用语料,本节针对完全重复的语料下手,仅删除完全重复部分,以确保保留有用的文本评论信息。 %matplotlib inline import pandas as pd import numpy as np import re import jieba.posseg as psg # 加载评论数据 reviews = pd.read_csv('data/reviews.csv')
通过人工观察数据发现,评论中夹杂着许多数字与字母,对于本案例的挖掘目标而言,这类数据本身并没有实质性帮助。另外,由于该评论文本数据主要是围绕京东商城中美的电热水器进行评价的,其中“京东”“京东商城”“美的”“热水器”“电热水器"等词出现的频数很大,但是对分析目标并没有什么作用,因此可以在分词之前将这些词去除,对数据进行清洗 # 去掉评论中的数字、字母,以及“京东”“京东商城”“美的”“热水器”“电热水器" content = reviews['content'] # 编译匹配模式 pattern = re.compile('[a-zA-Z0-9]|京东|美的|电热水器|热水器|京东商城') # re.sub用于替换字符串中的匹配项 content = content.apply(lambda x : pattern.sub('',x))
jieba的几个分词接口:cut、lcut、posseg.cut、posseg.lcut # 自定义简单的分词函数 worker = lambda s : [[x.word,x.flag] for x in psg.cut(s)] # 单词与词性 seg_word = content.apply(worker)
由于本案例的目标是对产品特征的优缺点进行分析,类似“不错,很好的产品”“很不错,继续支持”等评论虽然表达了对产品的情感倾向,但是实际上无法根据这些评论提取出哪些产品特征是用户满意的。评论中只有出现明确的名词,如机构团体及其他专有名词时,才有意义,因此需要对分词后的词语进行词性标注。之后再根据词性将含有名词类的评论提取出来。 根据得出的词性,提取评论中词性含有“n”的评论 # 提取含名词的评论的句子id ind = result[[x == 'n' for x in result['nature']]]['index_content'].unique() # 提取评论 result = result[result['index_content'].isin(ind)] # 重置索引 result.reset_index(drop=True,inplace=True)
进行数据预处理后,可绘制词云查看分词效果,词云会将文本中出现频率较高的‘关键词”予以视觉上的突出。首先需要对词语进行词频统计,将词频按照降序排序,选择前100个词,使用wordcloud模块中的WordCloud绘制词云,查看分词效果 from wordcloud import WordCloud import matplotlib.pyplot as plt # 按word分组统计数目 frequencies = result.groupby(by = ['word'])['word'].count() # 按数目降序排序 frequencies = frequencies.sort_values(ascending = False) # 从文件中将图像读取为数组 backgroud_Image=plt.imread('data/pl.jpg') wordcloud = WordCloud(font_path="C:\Windows\Fonts\STZHONGS.ttf",# 这里的字体要与自己电脑中的对应 max_words=100, # 选择前100词 background_color='white', # 背景颜色为白色 mask=backgroud_Image) my_wordcloud = wordcloud.fit_words(frequencies) # 将数据展示到二维图像上 plt.imshow(my_wordcloud) # 关掉x,y轴 plt.axis('off') plt.show() # 将结果写出 result.to_csv("word.csv", index = False, encoding = 'utf-8')
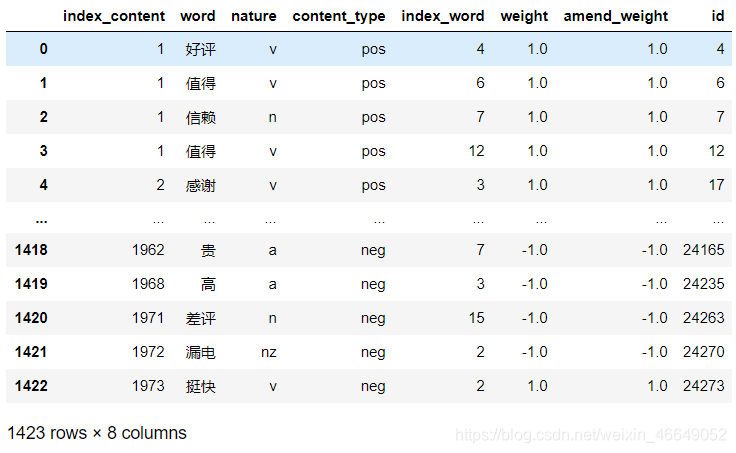
情感倾向也称为情感极性。在某商品评论中,可以理解为用户对该商品表达自身观点所持的态度是支持、反对还是中立,即通常所指的正面情感、负面情感、中性情感。由于本案例主要是对产品的优缺点进行分析,因此只要确定用户评论信息中的情感倾向方向分析即可,不需要分析每一评论的情感程度。对评论情感倾向进行分析首先要对情感词进行匹配,主要采用词典匹配的方法,本案例使用的情感词表是2007年10月22日知网发布的“情感分析用词语集 ( beta版)”,主要使用“中文正面评价”词表、“中文负面评价”“中文正面情感”“中文负面情感"词表等。将“中文正面评价”“中文正面情感”两个词表合并,并给每个词语赋予初始权重1,作为本案例的正面评论情感词表。将“中文负面评价”“中文负面情感”两个词表合并,并给每个词语赋予初始权重-1,作为本案例的负面评论情感词表。 一般基于词表的情感分析方法,分析的效果往往与情感词表内的词语有较强的相关性,如果情感词表内的词语足够全面,并且词语符合该案例场景下所表达的情感,那么情感分析的效果会更好。针对本案例场景,需要在知网提供的词表基础上进行优化.例如“好评”“超值”“差评”“五分”等词只有在网络购物评论上出现,就可以根据词语的情感倾向添加至对应的情感词表内。将“满意”“好评”“很快”“还好”“还行”“超值”“给力”“支持”“超好”“感谢”“太棒了”“厉害”“挺舒服”“辛苦”“完美”“喜欢”“值得”“省心”等词添加进正面情感词表。将“差评”“贵”“高”“漏水”等词加入负面情感词表。 读入正负面评论情感词表,正面词语赋予初始权重1,负面词语赋予初始权重-1。 # 读入评论词表 word = pd.read_csv('word.csv',header=0) # 读入正面、负面情感评价词 pos_comment = pd.read_csv("data/正面评价词语(中文).txt", header=None,sep="\n", encoding = 'utf-8', engine='python') neg_comment = pd.read_csv("data/负面评价词语(中文).txt", header=None,sep="\n", encoding = 'utf-8', engine='python') pos_emotion = pd.read_csv("data/正面情感词语(中文).txt", header=None,sep="\n", encoding = 'utf-8', engine='python') neg_emotion = pd.read_csv("data/负面情感词语(中文).txt", header=None,sep="\n", encoding = 'utf-8', engine='python') # 合并情感词与评价词 positive = set(pos_comment.iloc[:,0])|set(pos_emotion.iloc[:,0]) negative = set(neg_comment.iloc[:,0])|set(neg_emotion.iloc[:,0]) # 正负面情感词表中相同的词语 intersection = positive & negative # 去掉相同的词 positive = list(positive - intersection) negative = list(negative - intersection) # 正面词语赋予初始权重1,负面词语赋予初始权重-1 positive = pd.DataFrame({"word":positive, "weight":[1]*len(positive)}) negative = pd.DataFrame({"word":negative, "weight":[-1]*len(negative)}) posneg = positive.append(negative) # 将分词结果与正负面情感词表合并,定位情感词 data_posneg = pd.merge(left=word,right=posneg,on='word',how='left') # 先按评论id排序,再按在评论中的位置排序 data_posneg = data_posneg.sort_values(by = ['index_content','index_word'])
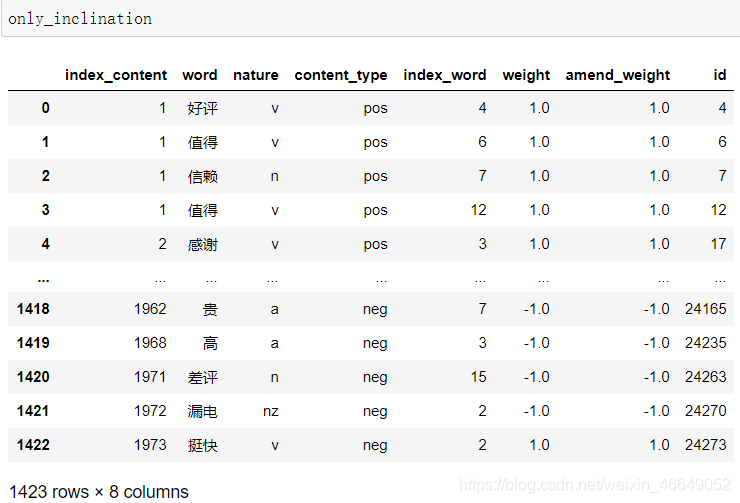
情感倾向修正主要根据情感词前面两个位置的词语是否存在否定词而去判断情感值的正确与否,由于汉语中存在多重否定现象,即当否定词出现奇数次时,表示否定意思;当否定词出现偶数次时,表示肯定意思。按照汉语习惯,搜索每个情感词前两个词语,若出现奇数否定词,则调整为相反的情感极性。本案例使用的否定词表共有19个否定词,分别为:不、没、无、非、莫、弗、毋、未、否、别、六、休、不是、不能、不可、没有、不用、不要、从没、不太。读入否定词表,对情感值的方向进行修正。计算每条评论的情感得分,将评论分为正面评论和负面评论,并计算情感分析的准确率。 # 根据情感词前面两个位置的词语是否存在否定词或双层否定词对情感值进行修正 # 载入否定词表 notdict = pd.read_csv("data/not.csv") # 处理否定修饰词 # 构造新列,作为经过否定词修正后的情感值 data_posneg['amend_weight'] = data_posneg['weight'] data_posneg['id'] = np.arange(0, len(data_posneg)) # 只保留有情感值的词语 only_inclination = data_posneg.dropna() # 修改索引 only_inclination.index = np.arange(0, len(only_inclination))
提取正面评论与负面评论,然后分别绘制词云,来查看情感分析效果 # 给情感值大于0的赋予评论类型pos,小于0的赋予neg emotional_value['a_type'] = '' emotional_value['a_type'][emotional_value['amend_weight'] > 0] = 'pos' emotional_value['a_type'][emotional_value['amend_weight'] |
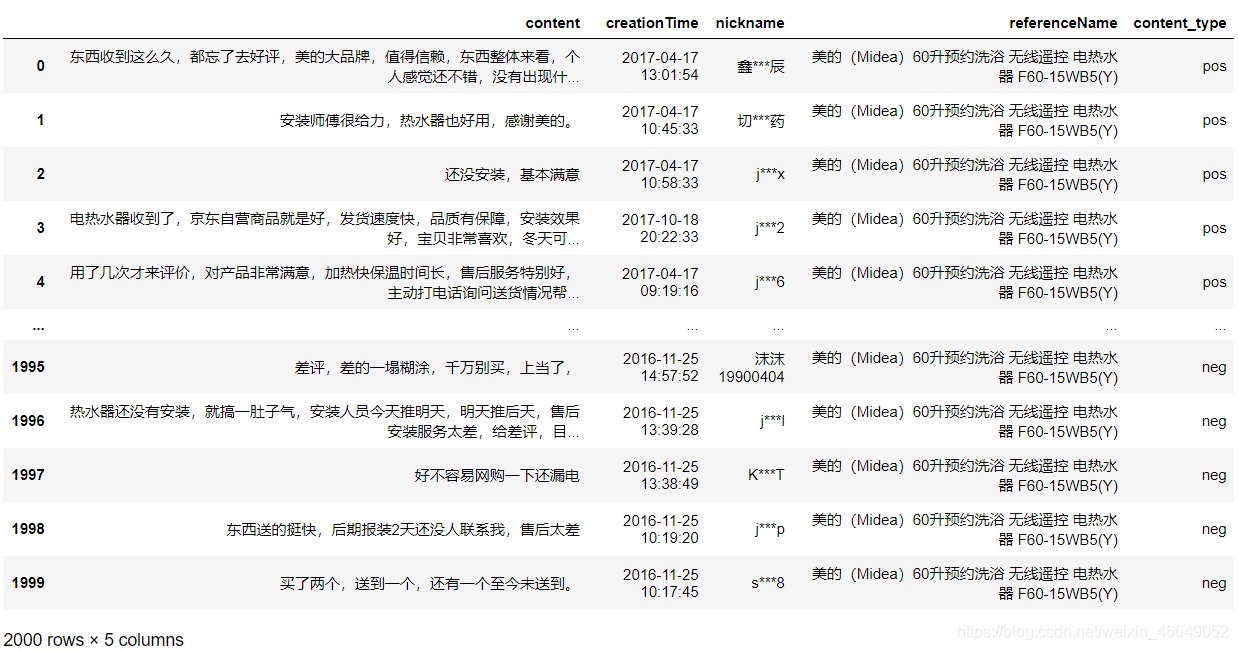




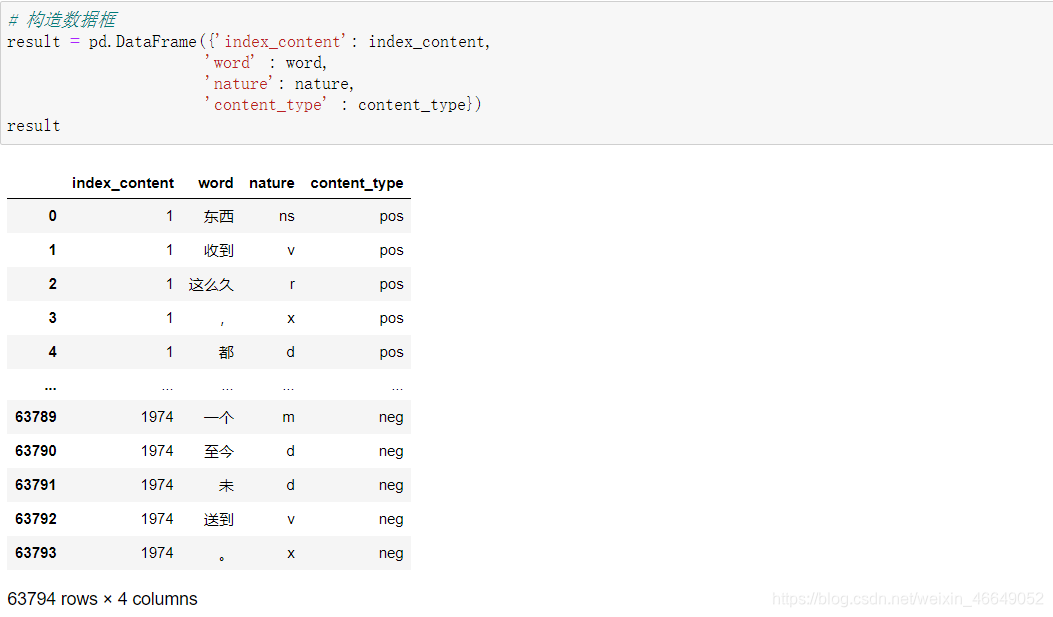 观察nature列得,x表示标点符号 删除标点符号
观察nature列得,x表示标点符号 删除标点符号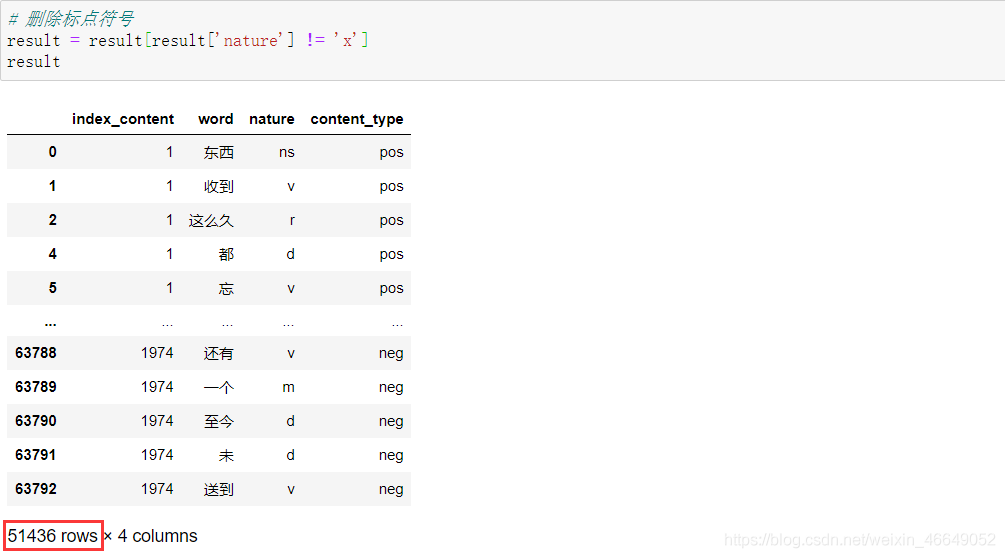 删除停用词
删除停用词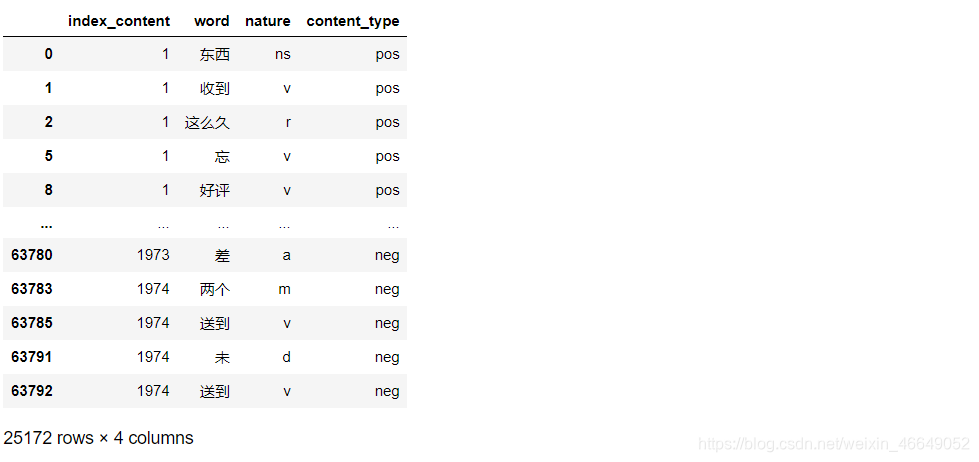
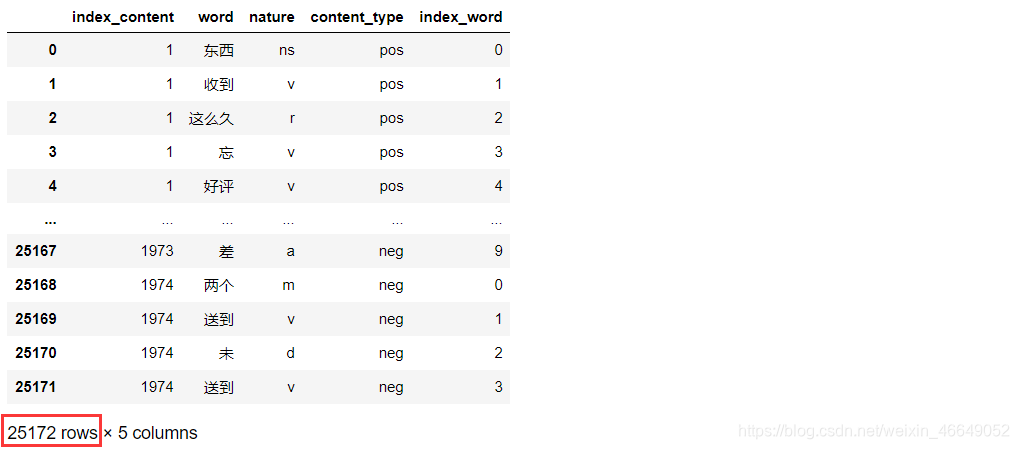

 对评论数据进行预处理后,分词效果较为符合预期。其中“安装”“师傅”“售后”“物流”“服务”等词出现频率较高,因此可以初步判断用户对产品的这几个方面比较重视。
对评论数据进行预处理后,分词效果较为符合预期。其中“安装”“师傅”“售后”“物流”“服务”等词出现频率较高,因此可以初步判断用户对产品的这几个方面比较重视。
【本文地址】