| PIAFusion: A progressive infrared and visible image fusion network based on illumination aware论文阅读 | 您所在的位置:网站首页 › 全局平均池化tensorflow › PIAFusion: A progressive infrared and visible image fusion network based on illumination aware论文阅读 |
PIAFusion: A progressive infrared and visible image fusion network based on illumination aware论文阅读
|
PIAFusion: A progressive infrared and visible image fusion network based on illumination awarePIAFusion:一种基于光照感知的渐进式红外与可见光图像融合网络研究背景传统方法的发展目前正面临瓶颈。一方面,传统方法所采用的变换或表示变得越来越复杂,以获得更令人印象深刻的融合性能,这不能响应实时计算机应用的要求。另一方面,制定的活动度度量和融合规则无法适应复杂的场景。基于AE的融合框架不是完全可学习的,因为利用制定的融合规则来合并深度特征。因此,其他研究人员专注于探索基于端到端CNN的图像融合网络,该网络依赖于优越的网络结构和精细的损失函数来确保融合性能。红外和可见光图像融合社区目前缺乏用于训练鲁棒融合网络的大型基准数据集。主流数据集,即TNO数据集和RoadScene数据集包括一些具有简单场景的图像对,特别是TNO数据集中。在这些数据集上训练的融合网络容易过度拟合,无法处理更复杂的场景。从未研究过照明不平衡,照明不平衡是指白天和夜间场景之间的照明条件差异。现有方法通常假设纹理仅存在于可见图像中,这在白天场景中是合理的。然而,这样的假设可能会导致融合图像在夜间丢失纹理细节。此外,基于AE的方法利用不适当的融合规则来合并深度特征,这可能会削弱纹理细节和显著目标。Idea 白天、夜晚的红外图像和可见光图像包含的细节不一样,现有算法很多只考虑可见光和红外图像之间的细节差,将红外和可见光图像融合定义为红外图像的强度保持和可见光图像的纹理保持,这个设定在白天的情况下是合理的,但是,没有考虑白天夜晚所得到的图像也存在细节差,因此,设计了一个照明感知子网络来评估照明条件。更具体地,预训练的照明感知子网络计算当前场景是白天还是夜晚的概率。然后,利用这些概率构造照明感知损失,以指导融合网络的训练。 网络结构渐进式融合网络架构 图1 基于光照感知的渐进式红外与可见光图像融合算法总体框架表1 渐进融合网络中所有卷积层的核大小、输出信道和激活函数 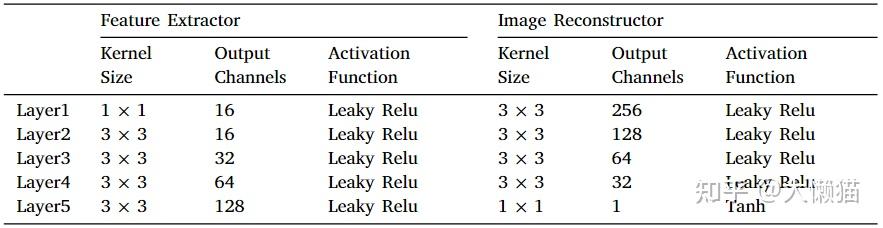 CMDAF模块其中,第 2、3 和 4 层的输出后面跟着一个 CMDAF 模块,用于交换模态互补特征,CMDAF 模块使网络能够以渐进的方式在特征提取阶段整合补充信息,定义如下: CMDAF模块其中,第 2、3 和 4 层的输出后面跟着一个 CMDAF 模块,用于交换模态互补特征,CMDAF 模块使网络能够以渐进的方式在特征提取阶段整合补充信息,定义如下: \oplus\表示按元素求和,\bigodot\表示按通道乘法,\delta(\cdot)\和GAP(\cdot)\分别表示sigmoid函数和全局平均池,CMDAF意味着全局平均池将互补特征压缩成向量,然后,通过sigmoid函数将向量归一化为[0,1]\,以生成信道权重。最后,将互补特征乘以信道权重,并将结果作为模态补充信息添加到原始特征。 融合红外和可见光图像的共同和互补特征通过中途融合的方式完全融合,即级联。中途融合策略表示如下: 该文级联选择的维度是第一维度,因此,融合后的通道数变为256。最后,通过反卷积即可从融合特征中得到融合图像。 光照感知子网络架构 图2 光照感知子网络架构 K4S2表示卷积核大小为4,stride设置为2,LReLU表示Leaky Relu激活函数,GAP表示Global Average Pooling,FC表示全连接层 光照感知子网络旨在估计场景的光照分布,其输入是可见图像,输出是光照概率。它由4个卷积层、一个全局平均池和两个完全连接的层组成。步幅设置为 2 的 4×4卷积层压缩空间信息并提取光照信息。所有的卷积层都使用 LeakyRelu 作为激活函数,并将 padding 设置为相同。然后,利用全局平均池化操作来整合光照信息。最后,两个全连接层根据光照信息计算光照概率。 损失函数渐进式融合网络的损失函数光照感知损失{L_{illum}=W_{ir}\cdot{L_{int}^{ir}}+W_{vi}\cdot{L_{int}^{vi}}}\  W_{ir}\,W_{vi}\表示光照感知权重,L_{int}^{ir}\,L_{int}^{ir}\表示红外和可见光图像的强度损失。 辅助强度损失 光照损失驱动渐进融合网络根据光照条件动态保留源图像的强度信息,但它不保持融合图像的最佳强度分布为此,因此引入辅助强度损失,max(\cdot)\表示选择最大的元素。 纹理损失 希望融合图像能够保持最佳强度分布并同时保留丰富的纹理细节,发现融合图像的最佳纹理可以表示为红外和可见图像纹理的最大聚合。因此,引入纹理损失来强制融合图像包含更多纹理信息。式子中\nabla\表示衡量图像纹理信息的梯度算子,该文中,利用 Sobel 算子来计算梯度。 渐进式融合网络的完整目标函数是光照损失、辅助强度损失以及文理损失的加权组合 光照感知子网络的损失函数 光照感知网络本质上是一个分类器,它计算图像属于白天和夜晚的概率。因此,我们采用交叉熵损失L_{IAN}\来约束光照感知子网络的训练过程。 光照感知子网络的损失函数 光照感知网络本质上是一个分类器,它计算图像属于白天和夜晚的概率。因此,我们采用交叉熵损失L_{IAN}\来约束光照感知子网络的训练过程。 其中z表示输入图像的光照标签,y=[{P_n}, {P_d}]\表示光照感知子网络的输出,\sigma\指的是softmax函数,它将光照概率归一化为[0,1]\. 实验验证数据集 基于 MFNet 数据集构建了一个新的用于红外和可见图像融合的多光谱数据集,移除 125 个未对齐的图像对收集了 715 个白天图像对和 729 个夜间图像对。此外,利用基于暗通道先验的图像增强算法来优化红外图像的对比度和信噪比。因此,发布的新多光谱道路场景 (MSRS) 数据集包含 1444 对对齐的高质量红外和可见图像。实验配置 在 MSRS 数据集上训练渐进融合模型和光照感知模型。选择 427 张白天场景图像和 376 张夜景图像来训练光照感知子网络。采用裁剪和分解数据增强来生成足够的训练数据,具体来说,将这些图像裁剪成 64 x 64 的图像块,步幅设置为 64,可以获得 29,960 个白天补丁和26,320 个夜间补丁。利用 376 个白天图像对,即26,320 个补丁和 376 个夜间图像对,即 26,320 个补丁来学习渐进式融合模型的参数。在输入网络之前,所有图像块都被归一化为 [0, 1]。使用 one-hot 标签作为光照感知子网络的参考,白天场景和夜间场景的标签分别设置为二维向量[1,0] 和 [0, 1]。 光照感知子网络和渐进式融合网络按顺序进行训练。更具体地说,我们首先训练光照感知子网络。之后,在训练渐进融合网络时,利用预训练的光照感知网络计算光照概率并构建光照感知损失。 batch size设置为b\,一个epoch的训练步数设置为p\,训练一个模型需要M\个epochs。对于光照感知子网络,我们根据经验设置b_1\= 128,M_1\= 100,p_1\= 438。对于渐进式融合网络,b_1\设置为 64,M_1\设置为 30,p_1\= 81,模型参数由Adam 优化器更新,学习率首先初始化为 0.001,然后呈指数衰减。对于渐进式融合网络的完整目标函数的超参数,设\lambda_1\= 3,\lambda_2\= 7 和\lambda_3\= 50。所提出的方法在 TensorFlow 平台上实施 54 所有实验均在NVIDIA TITAN V GPU 和 2.00 GHz Intel (R) Xeon (R) Gold5117 CPU 上进行。融合结果评估主观评价(定性比较)传统方法GTFMDLatLRRAEDenseFuseDRFCSFGANFusionGANCNNIFCNNPMGIU2Fussin 图3 PIAFusion与白天场景中9种最先进方法的定性比较(00633D),在每个图像中选择一个纹理区域(即红色框),并在右下角放大它,并突出显示一个目标区域(即绿色框) 客观评价(定量比较)互信息 (mutual information,MI)没有参考图像的情况下,融合图像从原图像中获取的信息量的多少,一般情况下,互信息评价指标的值越大,说明融合效果越好标准差(standard deviation,SD)从统计角度反映了融合图像的分布和对比度视觉信息保真度(visual information fidelity,VIF)从人类视觉系统的角度评估融合图像的信息保真度Q_{abf} \测量从源图像传送到融合图像的边缘信息的量表2 四个指标(即MI、SD、SF、Q_{abf}\)的定量比较, 来自MSRS数据集的150个图像对。红色表示最佳结果,蓝色表示第二最佳结果。  基于光照感知的视觉应用 基于光照感知的视觉应用事实上,一些实际的计算机视觉应用程序在建模时已经考虑了光照因素。王等人,提出了一种用于低光图像增强的全局照明感知和细节保留网络(GLADNet)[46]。GLADNet 首先计算低光图像的全局光照估计,然后根据估计调整光照,并使用与原始图像的级联来增强细节。此外,Sakkos 等人,开发了一个三重多任务生成对抗网络,将具有不同光照的特征集成到分割分支中,极大地提高了前景分割的性能[47]。此外,许多研究人员探索了利用光照信息来提高多光谱行人检测性能的可行性。例如,李等人,提出了一种光照感知更快的 R-CNN,通过在光照感知网络的输出上定义的门函数自适应地融合红外和可见子网络 [48]。巧合的是,Guan 等人,提出了一种基于照明感知行人检测和语义分割的多光谱行人检测框架[49]。他们利用一种新颖的光照感知加权机制来描述光照条件,并将光照信息集成到双流 CNN 中,以获得不同光照情况下的人类相关特征。此外,MBNet 以更灵活和平衡的方式促进优化过程并提高检测器的性能[31]。特别地,光照感知特征对齐模块用于根据光照条件自适应地选择补充信息。 知识欠缺1、渐进式融合网络渐进式融合网络(Progressive Fusion Networks,PFN)是一种用于图像生成和转换任务的深度学习模型。其主要思想是将一个大型任务分解成多个小型子任务,逐步完成多个子任务的学习,最终完成整个任务的学习。该模型通过多个步骤,逐步合并生成器和判别器的特征图,从而逐渐融合不同层次和分辨率的信息,生成高分辨率和高质量的图像。 具体来说,PFN将生成器和判别器分别拆分成多个子生成器和子判别器,在每个子生成器和子判别器中逐步增加分辨率和复杂度,使其能够逐渐学习到更多的图像特征和细节信息。在这个过程中,每个子生成器和子判别器都会生成和判别低分辨率的图像,并将其逐步合并为高分辨率的图像。最终,所有的子生成器和子判别器将合并为一个完整的生成器和判别器,用于生成高质量的高分辨率图像。 相较于传统的生成对抗网络(GAN),PFN具有更强的图像生成能力和更高的图像质量。其通过逐步融合网络,能够生成更加复杂、细节更丰富的高分辨率图像,具有更广泛的应用前景。 2、跨通道差分感知融合(CMDAF)模块深度学习中图像上采样的方法 3、sigmoid函数大白话深度学习中的Sigmoid函数 - 知乎 (zhihu.com) 4、全局平均池化【机器学习】一文带你深入全局平均池化 - 知乎 (zhihu.com) 5、激活函数深度学习笔记:如何理解激活函数?(附常用激活函数) - 知乎 (zhihu.com) 6、级联concatenation深度学习:Concatenate的理解_DreamBro的博客-CSDN博客_深度学习 concatenate 7、one-hot labelsPytorch之torch.nn.functional.one_hot() 8、nn.ReflectionPad2d(padding)import torch.nn as nn # 镜像填充的方式相比于前面使用固定数值进行填充,有可能获得更好的卷积结果。 # 镜像填充封装在nn.ReflectionPad2d中,其填充方式为新的dim值使用反方向的最下边元素的值 # 填充顺序是左-右-上-下 m = nn.ReflectionPad2d(1) # padding=1,表示填充层数1 input = torch.arange(9, dtype=torch.float).reshape(1, 1, 3, 3) input ------- tensor([[[[0., 1., 2.], [3., 4., 5.], [6., 7., 8.]]]]) ---------------------------- m(input) ----- tensor([[[[4., 3., 4., 5., 4.], [1., 0., 1., 2., 1.], [4., 3., 4., 5., 4.], [7., 6., 7., 8., 7.], [4., 3., 4., 5., 4.]]]]) ------------------------------ n = nn.ReflectionPad2d(2) n(input) ------- tensor([[[[8., 7., 6., 7., 8., 7., 6.], [5., 4., 3., 4., 5., 4., 3.], [2., 1., 0., 1., 2., 1., 0.], [5., 4., 3., 4., 5., 4., 3.], [8., 7., 6., 7., 8., 7., 6.], [5., 4., 3., 4., 5., 4., 3.], [2., 1., 0., 1., 2., 1., 0.]]]]) ------------------------------- m = nn.ReflectionPad2d((1, 1, 2, 0)) # padding=(left=1, right=1, top=2, bottom=0) m(input) ------------------------------- tensor([[[[7., 6., 7., 8., 7.], [4., 3., 4., 5., 4.], [1., 0., 1., 2., 1.], [4., 3., 4., 5., 4.], [7., 6., 7., 8., 7.]]]])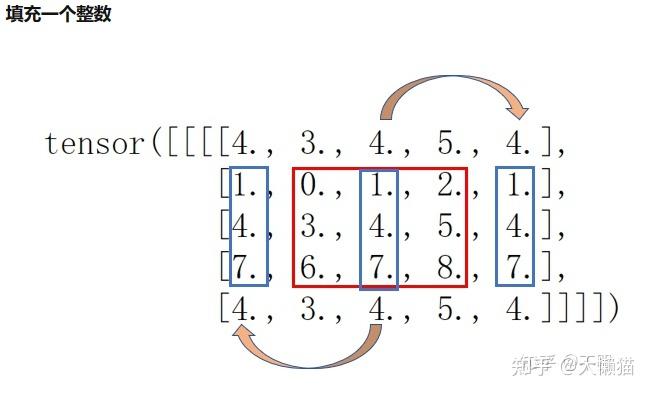  pytorch必须掌握的4种边界Padding方法 - 知乎 (zhihu.com) |
【本文地址】