| 临床预测模型概述5 | 您所在的位置:网站首页 › 假阳性和假阳性率的区别 › 临床预测模型概述5 |
临床预测模型概述5
|
前言
概述4中简单介绍了我们在做预测模型的时候最常用的三种模型构建的方法(Logistic Regression,Cox Proportional Hazards Model,LASSO Regression)。 那么作为一个新手科研者我们在做完模型构建之后就够了吗?我们怎么知道自己构建的模型好不好呢?这个时候就需要我们找到一些方法对模型进行评价和验证了。
PMID: 29049590 IF: 120.7 Q1 B1 我们可以根据这几条内容初步考虑一下我们自己/其他人构建的模型的效能: 1.研究者是否提供了模型的区分度和校准度信息?如果没有,那么该模型从一开始就可以被质疑。 2.研究者所提供模型的区分能力怎么样?这个模型是否能够足够的区分不同风险的患者?如果模型不能充分区分的话,请不要使用。 3.研究者所提供模型的校准能力怎么样?从图形中是否能够直观的观察到不同风险类别患者的预测结果和观察结果之间存在较好的拟合性? 4.研究者在进行模型对比或者更新模型时,其中之一的模型是否能够更加准确的预测风险? 从上面的问题中,作者着重的提到了区分度(Discrimination), 校准度(Calibration) 。那么这两个指标又是什么呢?它们各自的作用又是怎么样呢? 区分度(Discrimination) 1.1 区分度是什么通俗的来说,区分度就是指该模型能够将高风险和低风险人群所区分开来的能力。 1.2 区分度的评价方式评价区分度的指标是一致性统计量(Concordance statistics)也被称为C指数(C-index),主要用于计算生存分析中的COX模型预测值与真实值之间的区分度,也称为Harrell‘s concordance index。 对于采用logistics模型中的二分类结局数据,常采用受试者效应(Receiving Operating Characteristic Curve,ROC)曲线与图形所划分的曲线下面积(Area Under the Curve, AUC)进行评价。 1.2.1 C-index和AUC的异同点● C-index常被应用于含有时间的生存数据,因此生存数据中经常出现删失数据,C-index指数在计算方法上可以避免删失数据对结果的影响。它对所有研究对象随机组成对子,并对数据进行比较,假设生存时间较长的的患者被预测出的生存时间长于另一位相对较短的患者,则称为预测结果与实际结果相符合也就是预测一致。 ● AUC则仅适用于二分类结局数据,它通过真阳性率和假阳性率的数据进而绘制图形。若终点事件是二分类变量时,C-index与AUC相同。那么AUC值真的不能用去生存数据的分析吗?其实也不是的,假设把生存数据单独的精确到时间点的时候,也就是从纵向数据变成横向数据的时候同样可以采用AUC值进行评估,此时被称为时点AUC(Time-AUC)。 ● 因此C-index是AUC的扩展,AUC是C-index的一种特殊情况。 ● C-index和AUC值均在0.5-1之间,0.5为完全不一致,说明该模型没有预测作用,1为完全一致,说明该模型预测结果与实际完全一致。一般情况下,0.50-0.70为准确度较低,0.71-0.90之间为准确度中等,高于0.90则为高准确度。 1.2.1 受试者效应曲线-曲线下面积而从目前的应用情况来看,AUC和C-index的使用频率是不分伯仲的,而从图表的绘制情况来看,似乎大多数研究者会倾向于去做AUC的图(生存数据做time-AUC)。那么弄懂ROC和AUC就十分有必要了。
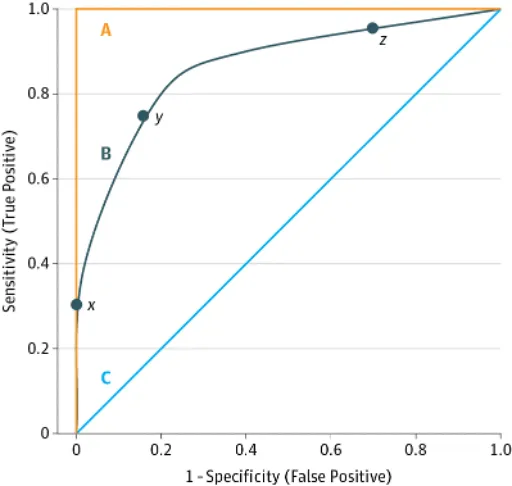
PMID: 29049590 IF: 120.7 Q1 B1 这个图形里边的线条就是受试者效应曲线(Receiving Operating Characteristic Curve, ROC Curve),每一条线与图形所划分的面积被称为曲线下面积(Area Under the Curve, AUC)。X轴所代表的含义是1-特异度,Y轴所代表的含义是灵敏度。 曲线A表示最理想的区分能力,这意味着测试或模型正确识别了所有发生事件的患者,而没有发生事件的患者也不存在错误分类(AUC = 1.0)。曲线B显示了一个潜在有用的测试或模型的曲线,这意味着对发生事件患者的正确分类多于不发生事件患者的错误分类(AUC = 0.8)。那么如果模型不能有效区分哪些患者将发生事件和不会发生事件, 则出现曲线C的情况,甚至会出现向右下凹陷的曲线。 1.2.2 曲线下面积完美的曲线则能获得一个100%的曲线下面积,这样的模型能够准确的将所有发生事件的患者归类为高风险患者,而不发生事件的患者归类为低风险患者。这种面积的百分比值就能直观的展现区分度的能力。 1.2.3 特异度和灵敏度同时我们还需要理解这个图形的X轴和Y轴所代表的含义。 X轴所代表的含义是1-特异度,那么什么是特异度的呢? ● 特异度是指模型正确识别阴性样本的能力,也称为真阴性率(True Negative Rate, TNR)。 ● 特异度 = 真阴性数 / (真阴性数 + 假阳性数),即 Specificity = TN / (TN + FP)。 ● 特异度高意味着模型在识别实际阴性样本时有较高的准确性。对于临床应用,特异度高的模型能够尽量减少误诊。 Y轴所代表的含义是灵敏度,那么什么是灵敏度呢? ● 灵敏度是指模型正确识别阳性样本的能力,也称为真阳性率(True Positive Rate, TPR)。 ● 灵敏度 = 真阳性数 / (真阳性数 + 假阴性数),即 Sensitivity = TP / (TP + FN)。 ● 灵敏度高意味着模型在识别实际阳性样本时有较高的准确性。对于临床应用,灵敏度高的模型能够尽量减少漏诊。 示例表格:
● 灵敏度:如果模型预测的阳性结果中,绝大多数都是实际阳性,则灵敏度高。例如,如果模型检测出100个阳性结果中有90个实际有病,灵敏度(真阳性率)就是90%。那么另外10个患者就是有病但未检测患病了,那1-灵敏度(假阴性率)就是10%。 ● 特异度:如果模型预测的阴性结果中,绝大多数都是实际阴性,则特异度高。例如,如果模型检测出100个阴性结果中有95个实际无病,特异度(真阴性率)就是95%。那么另外10个患者就是没病但检测患病了,那1-特异度(假阳性率)就是10%。 ● 那么作为一个高效的模型,我们希望这个模型的假阳性率较低而真阳性率高啦。而实际情况下,模型始终无法达到百分之100的精确,对人为框定的队列中是一定会出现“漏检”和“误检”的情况。 小结:值得一提的是,我们在使用区分度对不同风险患者进行区分的时候也需要思考一下临床意义,比如按照模型获得的风险比可能存在B患者的风险是A患者的3倍。但如果他们的预测值分别为3%和1%,而实际预测值却为30%和10%,那么结果就具有很严重的误导性。因此我们在做分析的时候必须考虑到实际的临床及生物学意义。 虽然单一的区分度去判断模型的能力是不够的,但研究者也不应使用无法去区分不同风险人群的模型。换句话说如果区分度不行,则需要先提升模型的区分度,之后再去考虑其他的评价指标,比如校准度(Calibration)。 校准度(Calibration) 1.1 校准度是什么校准度是指模型预测概率与实际发生率的一致性,换句话说是关注模型的绝对风险预测值是否准确。一个校准良好的模型,其预测的概率应该与实际观察到的概率相符合。 1.2 校准度的评价方式 1.2.1 通过可视化分析
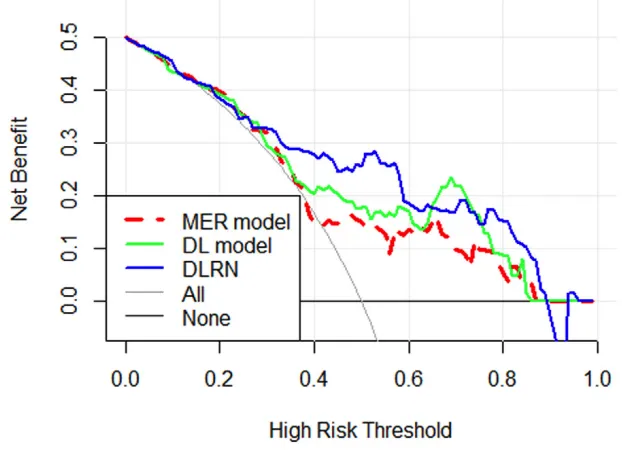
PMID: 29049590 IF: 120.7 Q1 B1 该图表示观察到的1年死亡率(数据标记表示平均值,误差柱表示95% CI)和使用MAGGIC风险评分模型(心衰风险评分)预测的1年死亡率之间的关系。既往的研究已经证实这个模型是具有很好的区分度的,但该模型还是低估了预测死亡率大于30%的患者的死亡率。 研究者大多数的时候是把模型预测概率分成10等分(也可以其他的等分),分别计算每组预测概率的均值和事件发生比例,然后以模型预测概率作为X轴, 以实际事件的比例为Y轴,绘制散点图。校准度较好的模型的散点是按照45°进行排列。 1.2.2 Hosmer-Lemeshow检验Hosmer-Lemeshow是另一种常见的方法,用于评估预测值和观测值之间的差异。但这种方法只能说明预测和实际是否存在差异,没法说明差异的大小。 小结从分析的角度来说,可视化是必须的,研究者从图形上就可以判断出在何种风险情况下观测和实际之间存在着差异,至于Hosmer-Lemeshow则并不必须,当然检验一下那是更好的。 那么我们对模型已经进行了区分度和校准度的检验之后,如何体现模型在临床决策中的价值呢?因为即使模型具有很好的区分度和校准度,这也并不意味着模型能够对临床决策产生获益。这时候临床决策曲线分析(Decision curve analysis)就可以发挥作用了。 临床决策曲线(Clinical decision curve) 1.1 临床决策曲线是什么假设在未获得病理金标准诊断的情况下,如果要切除一个肿块,那么都会存在假阳性和假阴性的可能。比如切这个肿块,是癌症的话手术可以延长10年寿命,但如果不是癌症的话,做手术会硬性生活质量导致预期寿命减少5年,那么这个患者经过模型预测大概有30%的概率可能是癌症,医生是否应该选择手术? 因此有时候临床医生就会考虑尽量避免假阳性,有时候则更希望避免假阴性,但如何去把控这个概率呢?通过什么方法可以去评价这个切或者不切这个肿块给患者带来的获益更大呢?这时候就需要临床决策曲线了。 1.2临床决策曲线的评价方式 1.2.1 临床决策曲线图如下是一张的临床决策曲线图。
PMID:36460582 ● X轴横线(None):代表假定所有患者都是阴性的,所有患者都不采取干预,净获益就是0。(患者来就诊,不管任何概率全部不处理) ● 灰色斜线(All):代表假定所有患者都是阳性的,所有患者都采取干预措施,净获益是效率为负数的反斜线。(患者来就诊,只要有的病可能,就上治疗) ● 横坐标为阈概率:代表患者患病的诊断预测概率。 ● 纵轴为净获益(Net benefit): 是指病人治疗带来的获益减去了非病人治疗的伤害和病人未治疗的损失之后的获益,这个图中患者的净获益最大是0.5,最小是0。进一步解释:假定某个疾病的诊断概率是60%,那么假设我的模型预测的诊断率超过了60%,那么从图中来看,蓝色线对应的Y轴为0.18左右,绿色线对应的Y轴为0.16左右,红色线为0.15左右,这就说明了采用DLRN(蓝色线)的模型预测出来的患者的净获益为0.18,也就是100个人中有18个人净获益了(也就是说100可能患病的人中有59个患者,41个非患者,此时净获益就是18个人)。 ● 不同颜色的线条代表了不同的模型,我们会发现如果模型效果越好,那么在相同诊断效能的情况下的净获益值就会越高。 所有患者采取干预措施的风险阈值选择 那么我们如何去决定所有患者采取干预措施时的风险阈值的选择呢(All斜线的X轴交点)? 很多研究者会采用ROC曲线中的最佳约登值进而使得真阳性率和真阴性率之和最大化,但这假设了敏感度和特异度是相同重要。因此我们在选择风险阈值的时候还是要进一步考虑临床因素,比如我们认为切除肿块手术比不切除肿块手术更重要,那么此时切除肿块得到益处是不切除肿块的危害的5倍,也就是“弊”比“利”为1:5,而这个比值就是风险阈值。总之我们在选择风险阈值的时候需要考虑临床因素! 小结临床决策是临床预测模型中也必不可少的分析,它的应用可以帮助我们更好的做出临床决策。同时在多模型的决策曲线图中,研究者还需要细致观察曲线与曲线之间的情况,比如是否相交?曲线是否平整还是高低不平(涉及到模型稳定性)?相交之前和相交之后是否需要选择不同的模型?等等 参考文献Ana Carolina Alba, Thomas Agoritsas, Michael Walsh et al. Discrimination and Calibration of Clinical Prediction Models: Users' Guides to the Medical Literature. JAMA. 2017 Oct 10;318(14):1377-1384. doi: 10.1001/jama.2017.12126 IF: 120.7 Q1 B1. Ben Van Calster, Laure Wynants, Jan F M Verbeek et al. Reporting and Interpreting Decision Curve Analysis: A Guide for Investigators. Eur Urol. 2018 Dec;74(6):796-804. Ying-Mei Zheng, Jun-Yi Che, Ming-Gang Yuan et al. A CT-Based Deep Learning Radiomics Nomogram to Predict Histological Grades of Head and Neck Squamous Cell Carcinoma. Acad Radiol. 2023 Aug;30(8):1591-1599. doi: 10.1016/j.acra.2022.11.007 IF: 4.8 Q1 B2. 注:若对内容有疑惑或者发现有明确错误的朋友,请联系后台(希望多多交流)。更多内容可关注公众号:生信方舟。 - END - |



【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |