| 2023 | 您所在的位置:网站首页 › 修改buildprop增强网络 › 2023 |
2023
|
2023-ICCV-隐式神经网络实现低光照图像增强(NeRCo)论文解读+代码解析
引言那么目前低光照图像增强还面临哪些挑战呢?
挑战1. 不可预测的亮度降低和噪声挑战2.度量友好版本和视觉友好版本之间的差异挑战3. 有限的配对训练数据
1.论文概述(原文摘要、引言部分)2.核心创新点(原文方法部分)2.1 归一化的神经表示什么是归一化的神经表示?为什么归一化的神经表示能够奏效?
2.2 文本驱动的外观识别器文本驱动的判别表示外观驱动的判别表示
2.3 整体框架
3.实验部分4.结论5.复现过程(重要)5.1 数据准备5.2 环境搭建下载快速运行训练5.3 取消SSL证书验证(重要)5.4 生成增强图像5.5 模型调优
2023年人工智能顶会ICCV会议论文复现 Implicit Neural Representation for Cooperative Low-light Image Enhancement >>源码以及项目详细部署视频 引言本文涉及到低光照图像增强、图像的神经表示以及多模态学习等领域,下面将简单介绍下相关知识。 1.低光照图像增强 低光图像增强是图像处理领域的一个重要研究方向,旨在改善在低照度条件下拍摄的图像质量。低光条件下的图像往往具有低对比度、噪点增加和细节丢失等问题。低光图像增强方法通过调整图像的亮度、对比度、色彩平衡等方面来提高图像的质量和视觉感知效果。
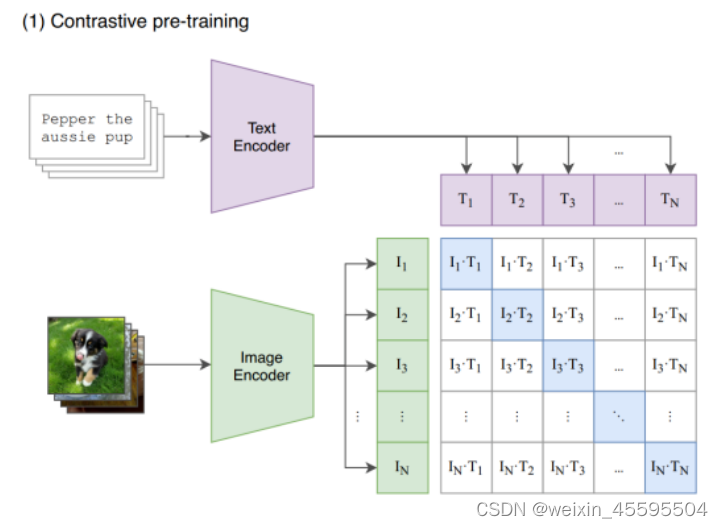
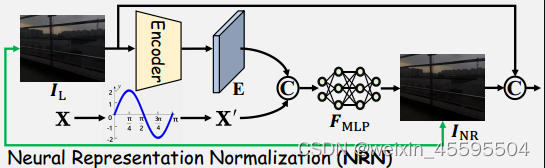
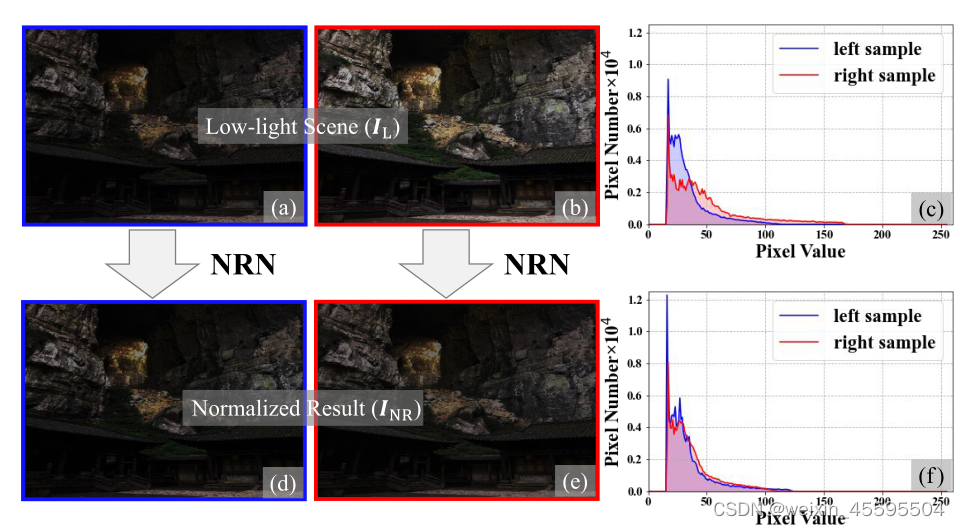
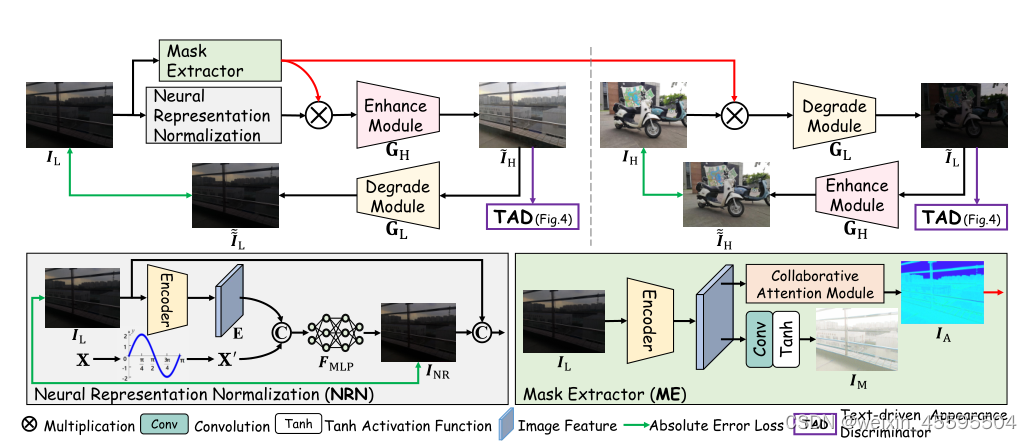
2.图像的神经表示 图像的神经表示指的是通过神经网络模型对图像进行编码和表示的方法。传统的图像表示方法通常使用手工设计的特征提取器,如SIFT、HOG等。而神经表示方法则通过深度学习模型,如卷积神经网络(CNN)、自编码器等,学习到图像的高级特征表示。这些神经表示能够捕捉图像的语义信息和结构信息,对于图像分类、目标检测、图像生成等任务具有重要作用。 3.多模态学习 多模态学习是指利用不同的感知模态(如图像、文本、语音等)之间的关联性进行联合学习和信息融合的方法。Radford提出从语言监督中学习视觉模型,称为CLIP。经过4亿对图像-文本对的训练,它可以用自然语言描述任何视觉概念,并且无需任何特定的训练就可以转移到其他任务中。CLIP模型的核心思想是通过对图像和文本进行对比学习,使得它们在嵌入空间中的表示能够相互匹配。这意味着,在嵌入空间中,相关的图像和文本将被映射到相近的位置,从而使得模型能够理解图像和文本之间的语义关系,如下图。 CLIP模型通过一个共享的编码器来处理图像和文本输入。对于图像,它使用卷积神经网络(CNN)对图像进行编码;对于文本,它使用Transformer模型对文本进行编码。编码器的输出表示图像和文本在嵌入空间中的表示。CLIP模型的优点是不需要大量的标注数据,可以使用大规模的无标注图像和文本数据进行预训练。预训练后的CLIP模型可以用于多种任务,如图像分类、图像生成、图像检索等。它在许多视觉和语言相关的任务中取得了出色的性能,并展现了强大的泛化能力。 那么目前低光照图像增强还面临哪些挑战呢? 挑战1. 不可预测的亮度降低和噪声在低光条件下,图像往往会出现亮度降低和噪声增加的问题。然而,这些退化因素的具体程度和方式往往是不可预测的,因为它们受到多种因素的影响,如光照条件、相机设置等。现有的低光图像增强方法难以准确地对这些退化因素进行建模和处理,导致增强结果可能不够鲁棒并且无法满足视觉感知的要求。 挑战2.度量友好版本和视觉友好版本之间的差异低光图像增强方法通常会追求在度量上有所改善,例如增加对比度、减少噪声等。然而,这些度量友好的改善并不总是与人眼感知的视觉友好相一致。在一些情况下,虽然度量上的改善较大,但图像质量却被认为是不自然或不真实的。因此,现有方法在度量友好版本和视觉友好版本之间存在固有的差距,无法很好地平衡二者之间的关系。 挑战3. 有限的配对训练数据有限的配对训练数据:低光图像增强方法通常需要使用配对的训练数据,即低光图像和对应的高质量图像。然而,获取大规模配对数据是一项耗时且昂贵的任务。由于配对数据的限制,现有方法在模型的泛化能力和适应性方面存在一定的局限性。此外,配对数据可能无法涵盖所有的场景和退化情况,导致模型的性能受到限制。 1.论文概述(原文摘要、引言部分)NeRCo(Implicit Neural Representation for Cooperative Low-light Image Enhancement)提出了一种名为NeRCo的隐式神经表示方法,用于合作式低光图像增强。现有的低光图像增强方法存在以下三个限制:不可预测的亮度降低和噪声、度量友好版本和视觉友好版本之间的固有差距,以及有限的配对训练数据。为了解决这些限制,论文提出了NeRCo方法,它以无监督的方式稳健地恢复感知友好的结果。 具体而言,NeRCo通过一个可控的拟合函数统一了现实场景中多样的退化因素,从而提高了鲁棒性。对于输出结果,论文引入了来自预训练视觉-语言模型的先验信息,采用语义导向的监督方法。它不仅仅追随参考图像,还鼓励结果符合主观期望,寻找更加视觉友好的解决方案。此外,为了减少对配对数据的依赖并减少解决空间,论文开发了一个双闭环约束增强模块,它以自监督的方式与其他相关模块合作进行训练。 最后,广泛的实验证明了我们提出的NeRCo方法的鲁棒性和优越性能。 2.核心创新点(原文方法部分) 2.1 归一化的神经表示 什么是归一化的神经表示?归一化的神经表示(Neural Representation Normalization)是一种在神经网络中对特征表示进行标准化的技术。它的目的是通过对神经表示进行归一化处理,使得不同样本的特征表示在统计上具有相似的分布,从而提高模型的鲁棒性和泛化能力。在神经网络中,每个神经元的输出表示了输入数据的某种特征。这些特征往往具有不同的尺度和范围,可能会对模型的训练和表征能力产生不利影响。神经表示归一化的目的是通过对特征进行调整,使得它们具有相似的均值和方差,从而减少特征之间的差异。本文是利用余弦相似性对输入进行重构,在与encoder进行编码后的特征concat,而后经过多层感知机得到归一化后的图像,如下图:
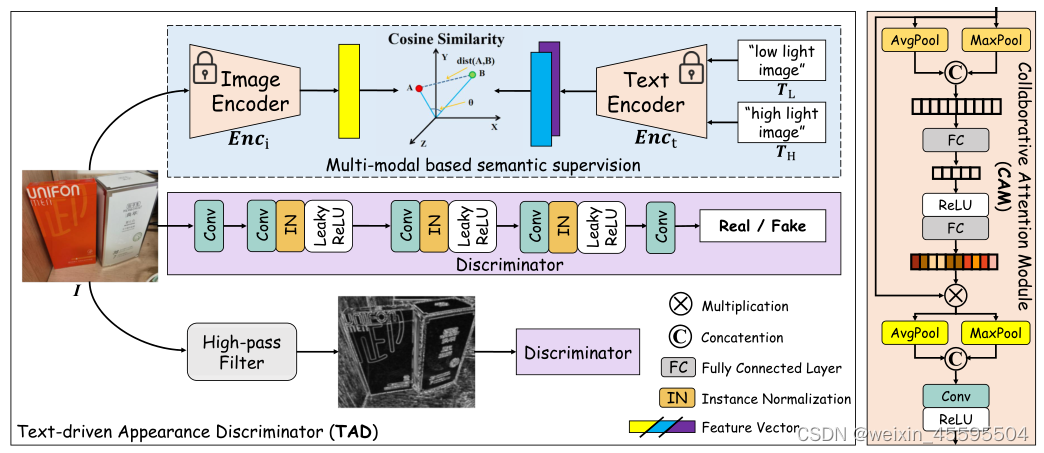
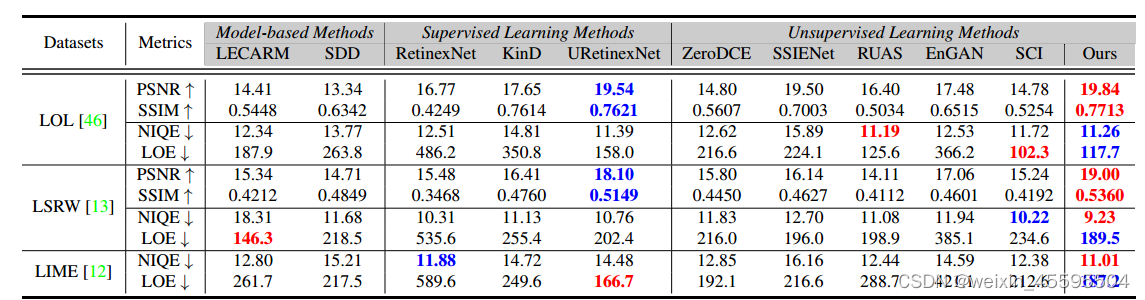
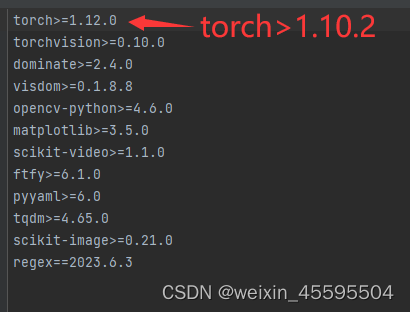
本文提出的文本驱动的外观鉴别器(在左侧区域)和我协同关注力模块(在右侧区域)的细节。前者用文本和图像模态监督输入,并关注高频成分。后者将注意力调整到不同的渠道并输出注意图。 本文将弱光域表示为L,高光域表示为h。如图上图所示,本文引入多模态学习来同时监督图像和文本模态的图像。具体而言,采用了最近广为人知的CLIP模型来获得高效先验。它由两个预训练的编码器组成,即文本的Enct和图像的Enci,具体代码如下: # clip模型核心代码 class CLIP(nn.Module): def __init__(self, embed_dim: int, # vision image_resolution: int, vision_layers: Union[Tuple[int, int, int, int], int], vision_width: int, vision_patch_size: int, # text context_length: int, vocab_size: int, transformer_width: int, transformer_heads: int, transformer_layers: int ): super().__init__() self.context_length = context_length if isinstance(vision_layers, (tuple, list)): vision_heads = vision_width * 32 // 64 self.visual = ModifiedResNet( layers=vision_layers, output_dim=embed_dim, heads=vision_heads, input_resolution=image_resolution, width=vision_width ) else: vision_heads = vision_width // 64 self.visual = VisionTransformer( input_resolution=image_resolution, patch_size=vision_patch_size, width=vision_width, layers=vision_layers, heads=vision_heads, output_dim=embed_dim ) self.transformer = Transformer( width=transformer_width, layers=transformer_layers, heads=transformer_heads, attn_mask=self.build_attention_mask() ) self.vocab_size = vocab_size self.token_embedding = nn.Embedding(vocab_size, transformer_width) self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width)) self.ln_final = LayerNorm(transformer_width) self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim)) self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)) 外观驱动的判别表示为了生成可靠的内容,图像监督是必要的。如中文本驱动器框架图紫色区域(框架图)所示,本文叠加了一个判别器来区分预测结果和真实图像,从而提高了图像级的真实性(例如颜色、纹理和结构)。考虑到图像处理中的细节失真,本文嵌入了一个由高通滤波器和相同结构的鉴别器组成的高频路径。滤波器提取高频分量,鉴别器在边缘级对高频分量进行监督。基于这种双路色边判别结构,实现了色彩与细节的权衡。 在训练过程中,TAD在学习L和H之间的双向映射关系中起对抗作用,利用的是sobel算子实现图像的高通滤波,代码如下。 # -*- coding: utf-8 -*- from re import I import torch import torch.nn as nn import torch.nn.functional as F from PIL import Image from torchvision import transforms import os trans = transforms.Compose([transforms.ToTensor()]) class GradLayer(nn.Module): def __init__(self): super(GradLayer, self).__init__() kernel_v = [[0, -1, 0], [0, 0, 0], [0, 1, 0]] kernel_h = [[0, 0, 0], [-1, 0, 1], [0, 0, 0]] kernel_h = torch.FloatTensor(kernel_h).unsqueeze(0).unsqueeze(0) kernel_v = torch.FloatTensor(kernel_v).unsqueeze(0).unsqueeze(0) self.weight_h = nn.Parameter(data=kernel_h, requires_grad=False) self.weight_v = nn.Parameter(data=kernel_v, requires_grad=False) self.gray2RGB = torch.nn.Conv2d(1, 3, kernel_size=1, stride=1, padding=0) def get_gray(self,x): ''' Convert image to its gray one. ''' gray_coeffs = [65.738, 129.057, 25.064] convert = x.new_tensor(gray_coeffs).view(1, 3, 1, 1) / 256 x_gray = x.mul(convert).sum(dim=1) return x_gray.unsqueeze(1) def forward(self, x): if x.shape[1] == 3: x = self.get_gray(x) x_v = F.conv2d(x, self.weight_v, padding=1) x_h = F.conv2d(x, self.weight_h, padding=1) x = torch.sqrt(torch.pow(x_v, 2) + torch.pow(x_h, 2) + 1e-6) x = self.gray2RGB(x) return x class GradLoss(nn.Module): def __init__(self): super(GradLoss, self).__init__() self.loss = nn.L1Loss() self.grad_layer = GradLayer() def forward(self, output, gt_img): output_grad = self.grad_layer(output) gt_grad = self.grad_layer(gt_img) return self.loss(output_grad, gt_grad) def tran(img): net = GradLayer().to(torch.device('cuda:0')) img = net(img) # input img: data range [0, 1]; data type torch.float32; data shape [1, 3, 256, 256] image = img * 4. return image 2.3 整体框架如图所示,给定一个弱光图像IL,我们首先通过神经表示(NRN,第3.2节)对其进行归一化,以提高模型对不同退化条件的鲁棒性。 然后,Mask Extractor 模块从图像中提取注意掩模,以指导不同区域的增强。之后,增强模块GH(以ResNet为代表)生成高光图像eIH。为了保证图像的质量,设计了一个文本驱动的外观判别器来监督图像的生成,其中文本驱动的监督保证了语义的可靠性,外观监督保证了视觉的可靠性。然后,eIH通过退化模块GL转换回低光域eeIL,并计算与原始低光图像IL的一致性损失。 在训练过程中,我们运行了整个过程,如图1所示。我们输入两幅图像(即弱光IL和高光IH)。IL被增强为eIH,然后再转化回弱光eeIL。IH反之亦然。注意到IH仅用于训练目的,即以无监督的方式训练模型以获得更好的增强而不是退化。因此,我们只使用NRN来增强IL而不降低IH。对于推理,直接将IL增强为eIH,不做任何其他操作, NeRco整体架构如下所示:NeRCo的工作流程。提出了一种包含双闭环分支的合作对抗增强过程,每个分支包含一个增强操作和一个退化操作。我们嵌入了一个掩模提取器(ME)来描绘退化分布,并嵌入了一个神经表示归一化(NRN)模块来归一化输入弱光图像的退化情况。所有这些都被一起训练以相互约束,锁定到一个更精确的目标域。红色表示注意力图的转移。 本文在三个主流的低光照图像数据集上做了消融实验,在不同度量、不同的模型、自监督方法、无监督方法做了测试,本文提出的方法达到了新sota,如下图: 从实际的图像增强效果也可以看出,本文提出的方法优于先前的方法: 总结而言,该论文提出了一种名为NeRCo的隐式神经表示方法,用于协同弱光图像增强。具体而言,该方法通过以下几个方面来实现: 利用神经表示来归一化输入退化图像的水平,包括暗亮度和自然噪声,从而增强方法对不同退化因素的鲁棒性。引入高频路径和预训练的视觉语言模型的先验信息作为感知导向的引导,以确保输出增强图像在视觉上更加友好和自然。开发双闭环合作约束来训练增强模块,以减轻对配对数据的依赖,并以自监督的方式增强弱光场景。这种合作约束促使所有组件相互约束,进一步减少解决方案的空间。通过大量的实验证明,该方法在弱光图像增强任务上表现出优越性能,与其他性能最好的方法相比具有明显的优势。此外,该方法的组件还为其他低级任务,如图像去雾、压缩感知和高光谱成像等,提供了宝贵的灵感和参考。 总体而言,该论文提出的NeRCo方法通过引入隐式神经表示、感知导向引导和双闭环合作约束等创新的方法,有效地解决了弱光图像增强中存在的挑战,为该领域的研究和应用提供了有价值的贡献。成具有更合理笔画连接的更高质量的书法字体,并且在常规字体上也有令人满意的表现 5.复现过程(重要) 5.1 数据准备 Linux or macOSPython 3.8NVIDIA GPU + CUDA CuDNN 5.2 环境搭建键入命令: pip install -r requirements.txt::: tip 这里实测,requirements.txt的一些依赖库版本过高,清华源无法安装,只需要安装到清华源目前现有最高的版本即可。 ::: 例如,我们在安装依赖库的时候键入命令pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
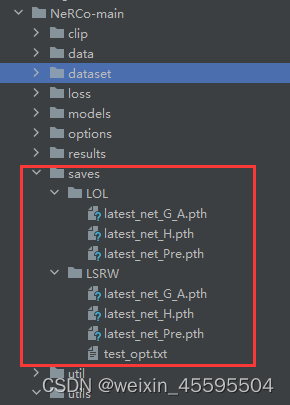
ERROR: Could not find a version that satisfies the requirement torch>=1.12.0 这里会报错找不到满足torch>=1.12.0的错误,我们只需要从上图中找到清华源中关于torch的最新版本1.10.2,我们在requirements.txt中将torch>=1.12.0替换为torch>=1.10.2即可,若遇到其他依赖库版本找不到的问题,同样使用此种解决方式。 你需要创建目录 ./saves/[YOUR-MODEL] (例如 ./saves/LSRW). 下载经过预训练的模型并将其放入 ./saves/[YOUR-MODEL]. 在这里,已经发布了预训练模型的两个版本,它们是在[LSRW]上训练的 LSRW数据集 和 LOL 数据集的下载链接如下: NeRCo trained on LSRWNeRCo trained on LOL最终关于预训练模型的目录应该如下:
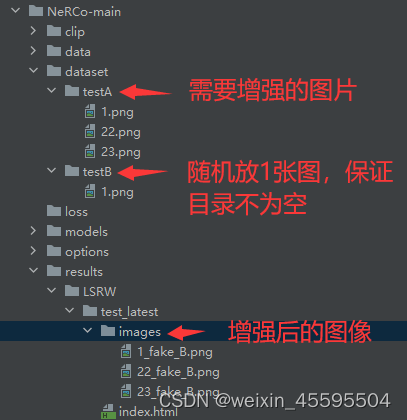 训练
下载训练低光数据并将其放入 ./dataset/trainA.随机采用数百个普通光图像,并将它们放在 ./dataset/trainB.训练模型代码如下:
cd NeRCo-main
mkdir loss
CUDA_VISIBLE_DEVICES=0 python train.py --dataroot ./dataset --name [YOUR-MODEL]
损失曲线保存在目录 ./loss.要查看更多中间结果,请查看 ./saves/[YOUR-MODEL]/web/index.html.
5.3 取消SSL证书验证(重要)
训练
下载训练低光数据并将其放入 ./dataset/trainA.随机采用数百个普通光图像,并将它们放在 ./dataset/trainB.训练模型代码如下:
cd NeRCo-main
mkdir loss
CUDA_VISIBLE_DEVICES=0 python train.py --dataroot ./dataset --name [YOUR-MODEL]
损失曲线保存在目录 ./loss.要查看更多中间结果,请查看 ./saves/[YOUR-MODEL]/web/index.html.
5.3 取消SSL证书验证(重要)
在运行CUDA_VISIBLE_DEVICES=0 python test.py代码的过程中,需要在clip.py文件里要添加取消证书验证代码,否则会报错如下: ::: danger urllib.error.URLError: >源码以及项目详细部署视频 |




【本文地址】