| MySQL学习笔记(三) | 您所在的位置:网站首页 › 使用sql语句将教师表中的数据合并 › MySQL学习笔记(三) |
MySQL学习笔记(三)
|
MySQL学习笔记(三)
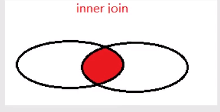
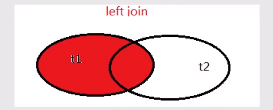
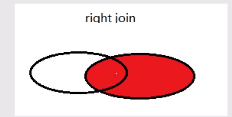
(2019.7.30) 27、查询 编号为‘3-105’课程且成绩至少高于编号为‘3-245’的成绩,这些人的cnumber,snumber和degree,并且按照degree的大小进行由高到低的排序(any)这个题目是真的别扭啊,其实重点就是 至少 :大于其中至少一个,这就用到了 any mysql> select * from score -> where cnumber='3-105' #条件一 -> and degree>any(select degree from score where cnumber = '3-245')#条件二 -> order by degree desc; #排序 +---------+---------+--------+ | snumber | cnumber | degree | +---------+---------+--------+ | 103 | 3-105 | 89 | | 102 | 3-105 | 83 | +---------+---------+--------+ 2 rows in set (0.39 sec)简单来说,就是3-105中大于3-245最小成绩的人的信息 至少 = any 28、查询编号为‘3-105’的课程且成绩高于课程‘3-245’课程的同学的信息?(all)这道题和上一道题相比,少了排序还少了至少,根据题目意思是高于课程‘3-245’所有人成绩的意思. 故语句为 mysql> select * from score -> where cnumber='3-105' #条件一 -> and degree>all(select degree from score where cnumber = '3-245'); 所有=all 29、查询所有教师和同学的name、sex和birthday(union、as)这个前面学到个,可以用 union 去把两个语句连接在一起 mysql> select tname,tsex,tbirthday from teacher -> union -> select sname,ssex,sbirthday from student; +-----------+------+---------------------+ | tname | tsex | tbirthday | +-----------+------+---------------------+ | 古一 | 女 | 0000-01-01 00:00:00 | | 王 | 男 | 2000-09-03 00:00:00 | | 春丽 | 女 | 1988-11-05 00:00:00 | | 刘邦 | 男 | 1978-12-03 00:00:00 | | 张三 | 男 | 1999-09-01 00:00:00 | | 李四 | 男 | 1999-02-11 00:00:00 | | 王二 | 女 | 1999-09-23 00:00:00 | | 王尼玛 | 男 | 1988-01-11 00:00:00 | | 张全蛋 | 男 | 2000-09-03 00:00:00 | | 赵铁柱 | 男 | 1983-04-05 00:00:00 | | 木子 | 女 | 2000-12-16 00:00:00 | +-----------+------+---------------------+ 11 rows in set (0.06 sec)但是会发现,上面的字段不对是tname,这里就要取 别名 …as… mysql> select tname as name,tsex as sex,tbirthday as birthday from teacher -> union -> select sname,ssex,sbirthday from student; +-----------+-----+---------------------+ | name | sex | birthday | +-----------+-----+---------------------+ | 古一 | 女 | 0000-01-01 00:00:00 | | 王 | 男 | 2000-09-03 00:00:00 | | 春丽 | 女 | 1988-11-05 00:00:00 | | 刘邦 | 男 | 1978-12-03 00:00:00 | | 张三 | 男 | 1999-09-01 00:00:00 | | 李四 | 男 | 1999-02-11 00:00:00 | | 王二 | 女 | 1999-09-23 00:00:00 | | 王尼玛 | 男 | 1988-01-11 00:00:00 | | 张全蛋 | 男 | 2000-09-03 00:00:00 | | 赵铁柱 | 男 | 1983-04-05 00:00:00 | | 木子 | 女 | 2000-12-16 00:00:00 | +-----------+-----+---------------------+ 11 rows in set (0.00 sec)第二排可以不用取别名,默认按第一排取别名。 30 、查询所有女教师和女同学的name、sex和birthday这就很简单。。。在两个查询语句后面加上where条件就可以,在用union连接 where tsex='女'+where ssex=‘女’ 31、查询成绩比课程平均成绩低的同学的成绩表先查一下各门课的平均成绩 mysql> select avg(degree) from score group by cnumber; +-------------+ | avg(degree) | +-------------+ | 86.0000 | | 82.0000 | | 76.0000 | +-------------+ 3 rows in set (0.56 sec)求某一门课的平均成绩: mysql> select avg(degree) from score where cnumber='3-105'; +-------------+ | avg(degree) | +-------------+ | 86.0000 | +-------------+ 1 row in set (0.00 sec) 然后,把score复制成a、b两个表(不需要语句,直接写),具体语句如下: mysql> select * from score a where -> degree select tname,depart from teacher -> where tnumber in (select tnumber from course); +--------+-----------------+ | tname | depart | +--------+-----------------+ | 古一 | 化学系 | | 王 | 计算机系 | | 春丽 | 通信工程系 | | 刘邦 | 通信工程系 | +--------+-----------------+ 4 rows in set (0.57 sec) 33、查询至少有2个男生的班号看一下学生表: mysql> select * from student; +---------+-----------+------+---------------------+--------+ | snumber | sname | ssex | sbirthday | class | +---------+-----------+------+---------------------+--------+ | 100 | 张三 | 男 | 1999-09-01 00:00:00 | 一班 | | 101 | 李四 | 男 | 1999-02-11 00:00:00 | 一班 | | 102 | 王二 | 女 | 1999-09-23 00:00:00 | 一班 | | 103 | 王尼玛 | 男 | 1988-01-11 00:00:00 | 一班 | | 104 | 张全蛋 | 男 | 2000-09-03 00:00:00 | 一班 | | 105 | 赵铁柱 | 男 | 1983-04-05 00:00:00 | 二班 | | 106 | 木子 | 女 | 2000-12-16 00:00:00 | 二班 | +---------+-----------+------+---------------------+--------+ 7 rows in set (0.00 sec) mysql> select class from student where ssex='男' group by class having count(*)>=2; +--------+ | class | +--------+ | 一班 | +--------+ 1 row in set (0.00 sec)count(*)统计男生的个数 34、查询student表中不姓 ‘王’ 的同学记录这里可以用到模糊查询,并且区分 …not like… mysql> select * from student where sname not like '王%'; +---------+-----------+------+---------------------+--------+ | snumber | sname | ssex | sbirthday | class | +---------+-----------+------+---------------------+--------+ | 100 | 张三 | 男 | 1999-09-01 00:00:00 | 一班 | | 101 | 李四 | 男 | 1999-02-11 00:00:00 | 一班 | | 104 | 张全蛋 | 男 | 2000-09-03 00:00:00 | 一班 | | 105 | 赵铁柱 | 男 | 1983-04-05 00:00:00 | 二班 | | 106 | 木子 | 女 | 2000-12-16 00:00:00 | 二班 | +---------+-----------+------+---------------------+--------+ 5 rows in set (0.37 sec) 35、查询student表中每个学生的姓名和年龄年龄=当前年份 - 出生年份,当前年份可以用 **year( now())**来体现,再加上别名,具体语句如下: mysql> select sname,year(now())-year(sbirthday) as old from student; +-----------+------+ | sname | old | +-----------+------+ | 张三 | 20 | | 李四 | 20 | | 王二 | 20 | | 王尼玛 | 31 | | 张全蛋 | 19 | | 赵铁柱 | 36 | | 木子 | 19 | +-----------+------+ 7 rows in set (0.00 sec) 36、查询student表中最大最小sbirthday的日期值查询所有出生日期,系统默认使用升序排列,可不写、要是想显示降序可以在语句的最后加上asc mysql> select sbirthday from student order by sbirthday; +---------------------+ | sbirthday | +---------------------+ | 1983-04-05 00:00:00 | | 1988-01-11 00:00:00 | | 1999-02-11 00:00:00 | | 1999-09-01 00:00:00 | | 1999-09-23 00:00:00 | | 2000-09-03 00:00:00 | | 2000-12-16 00:00:00 | +---------------------+ 7 rows in set (0.01 sec)这里可以使用**max()、min()**函数 mysql> select max(sbirthday) as max,min(sbirthday) as min from student order by sbirthday; +---------------------+---------------------+ | max | min | +---------------------+---------------------+ | 2000-12-16 00:00:00 | 1983-04-05 00:00:00 | +---------------------+---------------------+ 1 row in set (0.00 sec) 37、以班级和年龄从大到小的顺序查询student表中的记录这里的年龄要从大到小,因为年份排序是根据年的大小来排序的(2000年>1988年),所以不需要指定降序,默认的升序对年龄来说就是从大到小。 这里order by是先按照第一进行排列,第一个相同再按照第二个进行排列 mysql> select * from student order by class desc,sbirthday; +---------+-----------+------+---------------------+--------+ | snumber | sname | ssex | sbirthday | class | +---------+-----------+------+---------------------+--------+ | 105 | 赵铁柱 | 男 | 1983-04-05 00:00:00 | 二班 | | 106 | 木子 | 女 | 2000-12-16 00:00:00 | 二班 | | 103 | 王尼玛 | 男 | 1988-01-11 00:00:00 | 一班 | | 101 | 李四 | 男 | 1999-02-11 00:00:00 | 一班 | | 100 | 张三 | 男 | 1999-09-01 00:00:00 | 一班 | | 102 | 王二 | 女 | 1999-09-23 00:00:00 | 一班 | | 104 | 张全蛋 | 男 | 2000-09-03 00:00:00 | 一班 | +---------+-----------+------+---------------------+--------+ 7 rows in set (0.00 sec) 38、查询男教师以及所上的课程可以先查男教师,然后再作为条件来用(比较简单,直接写了): mysql> select * from teacher where tsex='男'; +---------+--------+------+---------------------+-----------+-----------------+ | tnumber | tname | tsex | tbirthday | prof | depart | +---------+--------+------+---------------------+-----------+-----------------+ | 112 | 王 | 男 | 2000-09-03 00:00:00 | 副教授 | 计算机系 | | 114 | 刘邦 | 男 | 1978-12-03 00:00:00 | 助教 | 通信工程系 | +---------+--------+------+---------------------+-----------+-----------------+ 2 rows in set (0.00 sec) mysql> select * from course where tnumber in ( select tnumber from teacher where tsex='男'); +---------+--------------+---------+ | cnumber | cname | tnumber | +---------+--------------+---------+ | 3-105 | 数据结构 | 112 | | 9-888 | 数字电路 | 114 | +---------+--------------+---------+ 2 rows in set (0.00 sec) 39、查询最高分同学的信息由最高分找学号,再由学号找信息 mysql> select * from student where -> snumber=(select snumber from score where degree=( select max(degree) from score) ); +---------+--------+------+---------------------+--------+ | snumber | sname | ssex | sbirthday | class | +---------+--------+------+---------------------+--------+ | 101 | 李四 | 男 | 1999-02-11 00:00:00 | 一班 | +---------+--------+------+---------------------+--------+ 1 row in set (0.00 sec) 40、查询和王尼玛同性别的同学名字简单的子查询: mysql> select sname from student where ssex=(select ssex from student where sname='王尼玛'); +-----------+ | sname | +-----------+ | 张三 | | 李四 | | 王尼玛 | | 张全蛋 | | 赵铁柱 | +-----------+ 5 rows in set (0.00 sec) 41、查询和王尼玛同性别且同班的同学名字只需要用and再给上一题添加一个条件就OK了 mysql> select sname from student where ssex=(select ssex from student where sname='王尼玛') -> and class=(select class from student where sname='王尼玛'); +-----------+ | sname | +-----------+ | 张三 | | 李四 | | 王尼玛 | | 张全蛋 | +-----------+ 4 rows in set (0.00 sec) 42、查询所有选修‘人工智能’课程的男同学的成绩先从mysql> select cnumber from course where cname='人工智能';找到cnumber 再从mysql> select snumber from student where ssex='男';找到snumber 然后进行子查询: mysql> select degree from score -> where cnumber=(select cnumber from course where cname='人工智能') -> and snumber in (select snumber from student where ssex='男'); +--------+ | degree | +--------+ | 60 | +--------+ 1 row in set (0.00 sec) 注意这里snumber有多个要用 in ,只有一个用 = 43、使用如下命令建立一个grade表建立了一个等级表 mysql> create table grade( -> low int(3), -> upp int(3), -> grade char(1) -> ); Query OK, 0 rows affected (1.58 sec) insert into grade values(90,100,'A'); insert into grade values(80,89,'B'); insert into grade values(70,79,'C'); insert into grade values(60,69,'D'); insert into grade values(0,59,'E'); mysql> select * from grade; +------+------+-------+ | low | upp | grade | +------+------+-------+ | 90 | 100 | A | | 80 | 89 | B | | 70 | 79 | C | | 60 | 69 | D | | 0 | 59 | E | +------+------+-------+ 5 rows in set (0.00 sec)好啦,现在查询所有同学的snumber、cnumber、和grade列 mysql> select snumber,cnumber,grade from score,grade -> where degree between low and upp order by grade; #再排个序 +---------+---------+-------+ | snumber | cnumber | grade | +---------+---------+-------+ | 106 | 6-166 | A | | 101 | 3-245 | A | | 100 | 3-245 | B | | 102 | 3-105 | B | | 103 | 3-105 | B | | 105 | 6-166 | D | | 104 | 3-245 | D | +---------+---------+-------+ 7 rows in set (0.00 sec)这样就给每个同学的成绩进行了分组 啊~终于把查询的练习弄完了,真的够多也够细了。(2019.7.31) 今天把数据库的主要内容学完,7月结束~ 三、SQL的四种连接查询 1、内连接 inner join 或者 join 2、外连接 a、左连接:left join 或者 left outer join b、右连接:right join 或者 right outer join c、完全外连接:full join 或者 full outer join就是这四种连接,下面我们举例说明:,先创建一个数据库,再创建2个表 person表 id,name,cardid(来自于card表) card表 id,name mysql> create table person( -> id int, -> name varchar(20), -> cardid int -> ); Query OK, 0 rows affected (0.94 sec) mysql> create table card( -> id int, -> name varchar(20) -> ); Query OK, 0 rows affected (0.76 sec)再向表中添加数据: mysql> select * from card; +------+-----------+ | id | name | +------+-----------+ | 1 | 饭卡 | | 2 | 建行卡 | | 3 | 农行卡 | | 4 | 工商卡 | | 5 | 邮政卡 | +------+-----------+ 5 rows in set (0.00 sec) mysql> select * from person; +------+--------+--------+ | id | name | cardid | +------+--------+--------+ | 1 | 张三 | 1 | | 2 | 李四 | 3 | | 3 | 王五 | 6 | +------+--------+--------+ 3 rows in set (0.00 sec)我们没有创建外键,但是这两个表之间是有外键关系的,下面我们进行连接查询: 1、inner join 内连接查询对person和card表进行连接查询,加上条件 mysql> select * from person inner join card on person.cardid=card.id; +------+--------+--------+------+-----------+ | id | name | cardid | id | name | +------+--------+--------+------+-----------+ | 1 | 张三 | 1 | 1 | 饭卡 | | 2 | 李四 | 3 | 3 | 农行卡 | +------+--------+--------+------+-----------+ 2 rows in set (0.00 sec) 内连接查询就是两张表中的数据,通过某个字段相等,查询出相关记录数据,用 on… 表示条件,其中的inner join 可以用 join代替。 2、left join (左外连接) mysql> select * from person left join card on person.cardid=card.id; +------+--------+--------+------+-----------+ | id | name | cardid | id | name | +------+--------+--------+------+-----------+ | 1 | 张三 | 1 | 1 | 饭卡 | | 2 | 李四 | 3 | 3 | 农行卡 | | 3 | 王五 | 6 | NULL | NULL | +------+--------+--------+------+-----------+ 3 rows in set (0.00 sec)左外连接,会把左边表里面的所有数据取出来,而右边表数据如果有相等的,就显示出来,如果没有,就补 NULL 这里王五的cardid为6,在card表中没有对应,所有用NULL补上了 这里的语句,也可以用如下语句替代:left join = left outer join mysql> select * from person left outer join card on person.cardid=card.id; 结果是一样的 3、right join(右外连接) mysql> select * from person right join card on person.cardid=card.id; +------+--------+--------+------+-----------+ | id | name | cardid | id | name | +------+--------+--------+------+-----------+ | 1 | 张三 | 1 | 1 | 饭卡 | | 2 | 李四 | 3 | 3 | 农行卡 | | NULL | NULL | NULL | 2 | 建行卡 | | NULL | NULL | NULL | 4 | 工商卡 | | NULL | NULL | NULL | 5 | 邮政卡 | +------+--------+--------+------+-----------+ 5 rows in set (0.00 sec)与左外连接类似,右外连接会把右边表里面的所有数据取出来,而左边表数据如果有相等的,就显示出来,如果没有,就补 NULL 上面的2、4、5都没有相等,补上NULL,6因为右边card本来就没有就不显示了 这里的语句,也可以用如下语句替代:right join = right outer join mysql> select * from person right outer join card on person.cardid=card.id; 结果是一样的 4、full join(全外连接)mysql> select * from person full join card on person.cardid=card.id; ERROR 1054 (42S22): Unknown column 'person.cardid' in 'on clause' 这样会报错,原因是mysql 不支持 full join 下面我们用图看一下这几种连接: 1、inner join 内连接
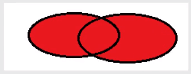
全连接等于左连接和右连接合在一起的结果 mysql> select * from person left join card on person.cardid=card.id -> union -> select * from person right join card on person.cardid=card.id; +------+--------+--------+------+-----------+ | id | name | cardid | id | name | +------+--------+--------+------+-----------+ | 1 | 张三 | 1 | 1 | 饭卡 | | 2 | 李四 | 3 | 3 | 农行卡 | | 3 | 王五 | 6 | NULL | NULL | | NULL | NULL | NULL | 2 | 建行卡 | | NULL | NULL | NULL | 4 | 工商卡 | | NULL | NULL | NULL | 5 | 邮政卡 | +------+--------+--------+------+-----------+ 6 rows in set (0.01 sec)左边是全部,右边也是全部,对应的没有的就补上NULL 四、事务在mysql中,事务其实是一个最小的不可分割的工作单元,事务能够保证一个业务的完整性 比如我们的银行转账: a给b转100块钱,相当于 update user set monry=money-100 where name='a' update user set monry=money+100 where name='b' 需要两条语句,在实际情况中,如果只有一条语句执行成功,而另一条没有执行成功,就会出现数据前后不一致的情况。 事务用来解决:多条sql语句可能会有同时成功的要求,要么就同时失败。 1、mysql如何控制事务?mysql默认是自动提交的 mysql> select @@autocommit; +--------------+ | @@autocommit | +--------------+ | 1 | +--------------+ 1 row in set (0.52 sec) 那么,默认事务开启的作用是什么?当我们去执行一个sql语句的时候,效果会立即体现出来,且不能回滚。 这里又出现了一些概念(回滚),我们举例来说: 创建一个数据库,再创建数据表,插入数据 mysql> create database bank; Query OK, 1 row affected (0.64 sec) mysql> use bank; Database changed mysql> create table user( -> id int primary key, -> name varchar(20), -> money int -> ); Query OK, 0 rows affected (0.93 sec) mysql> insert into user values(1,'a',1000); Query OK, 1 row affected (0.51 sec) mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 1000 | +----+------+-------+ 1 row in set (0.00 sec)事务回滚:撤销sql的执行效果 (rollback;) 下面调用rollback mysql> rollback; Query OK, 0 rows affected (0.00 sec) mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 1000 | +----+------+-------+ 1 row in set (0.00 sec)可以看到,即使调用了rollback,数据依然存在,说明是不能够回滚的,添加数据的语句执行完后默认就提交了。 我们可以通过设置默认事务为0的方式来进行改变,也就是设置mysql默认提交为false set autocommit=0; (1为开启,0为关闭) mysql> set autocommit=0; Query OK, 0 rows affected (0.54 sec) mysql> select @@autocommit; +--------------+ | @@autocommit | +--------------+ | 0 | +--------------+ 1 row in set (0.00 sec)上面的操作,关闭了mysql的自动提交(commit) 这里在操作一遍来验证:(这时候自动提交已经关闭了) mysql> insert into user values(2,'b',1000); #插入数据 Query OK, 1 row affected (0.00 sec) mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 1000 | | 2 | b | 1000 | +----+------+-------+ 2 rows in set (0.00 sec) mysql> rollback; #进行回滚 Query OK, 0 rows affected (0.07 sec) mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 1000 | +----+------+-------+ 1 row in set (0.00 sec)惊不惊喜,刚才插入的数据没有了。我们在执行完语句时(关闭默认提交),看到的效果只是一个临时效果,并没有真实的发生在我们数据库里面,是在一张虚拟的表中。 这里可以用commit提交 #再插入一次数据 mysql> insert into user values(2,'b',1000); Query OK, 1 row affected (0.00 sec) #手动提交数据 mysql> commit; Query OK, 0 rows affected (0.15 sec) #再撤销,是不可以撤销的(事务的一个特性:持久性) mysql> rollback; Query OK, 0 rows affected (0.00 sec) mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 1000 | | 2 | b | 1000 | +----+------+-------+ 2 rows in set (0.00 sec)只要commit了,rollback也没有用了,持久哦~ 自动提交: @@autocommit=1 手动提交: commit 回滚: rollback(在没有提交的情况下,是可以提交的) 也就是说,事务给我们提供了一个返回的机会!!!就像前面说的,当发现有一条语句没有执行成功的情况下,可以回滚了。在检查无误之后,再手动commit让它生效,产生真实效果。 我们再把事务关闭,改为自动提交: mysql> set autocommit=1; Query OK, 0 rows affected (0.00 sec) mysql> select @@autocommit; +--------------+ | @@autocommit | +--------------+ | 1 | +--------------+ 1 row in set (0.00 sec) 事务的其他打开方式? 手动开启事务:begin;或者 start transaction;都可以帮我们手动开启一个事务 这里进行转账例子: mysql> update user set money=money-100 where name='a'; Query OK, 1 row affected (0.95 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> update user set money=money+100 where name='b'; Query OK, 1 row affected (0.14 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 900 | | 2 | b | 1100 | +----+------+-------+ 2 rows in set (0.00 sec) #事务回滚 mysql> rollback; Query OK, 0 rows affected (0.00 sec) mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 900 | | 2 | b | 1100 | +----+------+-------+ 2 rows in set (0.00 sec)这里发现现在rollback是没有任何效果的,因为现在autocommit=1,为自动提交模式,每当执行一句话就立即生效了。 现在在输入这两个语句之前,输入begin;或者 start transaction; #加上begin;或者 start transaction 开启事务 mysql> begin; Query OK, 0 rows affected (0.01 sec) #对a、b进行转账操作 mysql> update user set money=money-100 where name='a'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> update user set money=money+100 where name='b'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 #看一下表 mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 800 | | 2 | b | 1200 | +----+------+-------+ 2 rows in set (0.00 sec) #事务回滚 mysql> rollback; Query OK, 0 rows affected (0.57 sec) mysql> select * from user; +----+------+-------+ | id | name | money | +----+------+-------+ | 1 | a | 900 | | 2 | b | 1100 | +----+------+-------+ 2 rows in set (0.00 sec)事务开启后,一旦 commit 提交,就不可回滚(也就是这个事务在提交的时候结束了),此时再rollback也没有用了 小结: 一、事务的四大特征ACID A 、原子性:事务是最小的单位,不可以再分割。 C、一致性:事务要求,同一事务sql语句,必须保证同时成功或者同时失败 I、隔离性:事务1和事务2之间是具有隔离性的只有隔离性没有讲,下面会有 D、持久性:事务一旦结束,就不可以返回 二、事务开启1、修改默认提交 set autocommit=0; 2、begin; 3、`start transaction; 三、事务提交commit;(让虚拟的效果真实产生) 四、事务手动回滚rollback;(让虚拟的效果撤销) 五、事务的隔离性1、read uncommitted; #读未提交的 2、read committed; #读已经提交的 3、repeatable read;#可以重复读 4、serializable;# 串行化 是啊,一个都看不懂,下面一个一个看: 1、read uncommitted; #读未提交的如果有事务a和事务b, a 事务对数据进行操作,在操作过程中事务没有被提交,但是b可以看见a操作的结果 下面举个例子 小明去淘宝店卖800块钱的鞋子,要转账给淘宝店 mysql> select * from user; +----+-----------+-------+ | id | name | money | +----+-----------+-------+ | 1 | a | 800 | | 2 | b | 1200 | | 3 | 小明 | 1000 | | 4 | 淘宝店 | 1000 | +----+-----------+-------+ 4 rows in set (0.00 sec) 如何查看数据库的隔离级别?在mysql8.0中可以这样: #系统级别的 mysql> select @@global.transaction_isolation; #会话级别的 mysql> select @@transaction_isolation; #mysql默认隔离级别 REPEATABLE-READ mysql> select @@global.transaction_isolation; +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | REPEATABLE-READ | +--------------------------------+ 1 row in set (0.39 sec) 如何修改隔离级别? #修改到可以读未提交的 mysql> set global transaction isolation level read uncommitted; Query OK, 0 rows affected (0.00 sec) mysql> select @@global.transaction_isolation; +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | READ-UNCOMMITTED | +--------------------------------+ 1 row in set (0.00 sec)小明开始进行转账: mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> update user set money=money-800 where name='小明'; Query OK, 1 row affected (0.40 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> update user set money=money+800 where name='淘宝店'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from user; +----+-----------+-------+ | id | name | money | +----+-----------+-------+ | 1 | a | 800 | | 2 | b | 1200 | | 3 | 小明 | 200 | | 4 | 淘宝店 | 1800 | +----+-----------+-------+ 4 rows in set (0.00 sec)然后小明给淘宝店打电话,让他们去看一下钱是否到账了,这时候打开另外一个终端去查user表(相当于淘宝店在另一个ATM机子上查询) mysql> use bank; Database changed mysql> select * from user; +----+-----------+-------+ | id | name | money | +----+-----------+-------+ | 1 | a | 800 | | 2 | b | 1200 | | 3 | 小明 | 200 | | 4 | 淘宝店 | 1800 | +----+-----------+-------+ 4 rows in set (0.00 sec)发现钱确实到账了,然后发货。 淘宝店主晚上请女朋友吃饭,花了1800,结账的时候钱不够。为什么呢? 因为小明在他的ATM上进行了 rollback(相当于在第一个终端上操作) mysql> rollback; Query OK, 0 rows affected (0.53 sec) mysql> select * from user; +----+-----------+-------+ | id | name | money | +----+-----------+-------+ | 1 | a | 800 | | 2 | b | 1200 | | 3 | 小明 | 1000 | | 4 | 淘宝店 | 1000 | +----+-----------+-------+ 4 rows in set (0.00 sec)这样一下钱就回来了。 淘宝店主在他的ATM机子上又查了一下(相当于第二个终端) mysql> select * from user; +----+-----------+-------+ | id | name | money | +----+-----------+-------+ | 1 | a | 800 | | 2 | b | 1200 | | 3 | 小明 | 1000 | | 4 | 淘宝店 | 1000 | +----+-----------+-------+ 4 rows in set (0.00 sec)发现钱没有了??????what??? 这就发现了一个问题:在READ-UNCOMMITTED 条件下 如果两个不同的地方,都在进行操作,如果事务a开启后,他的数据可以被其他事务读取到,这样就会出现 (脏读 )对应淘宝店主其实也是在事务,只是他的每一个事务都执行了 脏读:一个事务读到了另一个事务没有提交的数据,就叫做脏读。在实际开发中是不允许出现的 2、read committed; #读已经提交的我们首先修改隔离级别为read committed set global transaction isolation level read committed; 再查看: mysql> select @@global.transaction_isolation; +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | READ-COMMITTED | +--------------------------------+ 1 row in set (0.00 sec)我们还是举个例子昂: 小张是银行的会计,他查看资产 mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> select * from user; +----+-----------+-------+ | id | name | money | +----+-----------+-------+ | 1 | a | 800 | | 2 | b | 1200 | | 3 | 小明 | 1000 | | 4 | 淘宝店 | 1000 | +----+-----------+-------+ 4 rows in set (0.00 sec)然后去上厕所了,此时小王干了一件事:(再打开一个终端) mysql> use bank; Database changed mysql> start transaction; Query OK, 0 rows affected (0.00 sec) mysql> insert into user values(5,'c',100); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.15 sec) mysql> select * from user; +----+-----------+-------+ | id | name | money | +----+-----------+-------+ | 1 | a | 800 | | 2 | b | 1200 | | 3 | 小明 | 1000 | | 4 | 淘宝店 | 1000 | | 5 | c | 100 | +----+-----------+-------+ 5 rows in set (0.00 sec)此时,小张上完厕所抽完烟,开始计算存款的平均数: mysql> select avg(money) from user; +------------+ | avg(money) | +------------+ | 820.0000 | +------------+ 1 row in set (0.00 sec)小张就会觉着这怎么可能是820呢??明明是1000啊 虽然我只能读到已经提交的数据,但还是会出现问题就是读取一个表的数据,发现前后不一致。 在read committed情况下会出现不可重复读现象 3、repeatable read;#可以重复读老规矩,修改隔离级别 mysql> set global transaction isolation level repeatable read; Query OK, 0 rows affected (0.00 sec) mysql> select @@global.transaction_isolation; +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | REPEATABLE-READ | +--------------------------------+ 1 row in set (0.00 sec) 在repeatable read下会出现什么问题?有张全蛋和王尼玛两个人,在两个地方分别进行操作(两个终端) 在张全蛋的终端上开始事务: mysql> start transaction; Query OK, 0 rows affected (0.00 sec)王尼玛在另一个终端上开始事务: mysql> start transaction; Query OK, 0 rows affected (0.00 sec)然后张全蛋插入了一条数据: mysql> insert into user values(6,'d',1000); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.47 sec)但是王尼玛并没有查到这条记录,所以他就添加6的信息,就会报错,说6号已经存在,但是王尼玛又查不到,这种现象叫做幻读 事务a和事务b同时操作一张表,事务a提交的数据也不能被事务b看到,就会造成幻读!! 4、serializable;# 串行化老规矩,修改隔离级别: mysql> set global transaction isolation level serializable; Query OK, 0 rows affected (0.00 sec) mysql> select @@global.transaction_isolation; +--------------------------------+ | @@global.transaction_isolation | +--------------------------------+ | SERIALIZABLE | +--------------------------------+ 1 row in set (0.00 sec) 当表被另一个事务操作的时候,其他事务里的写操作时不可进行的。进入排队状态,直到另一个事务结束之后,其他事务的写入操作才会执行(在没有超时的情况下) 串行口的问题是,性能太差! 隔离级别越高,性能越差:read uncommitted>read committed>repeatable read>serializable mysql默认隔离级别是repeatable read |
【本文地址】