| 深度学习中backbone网络优缺点(附图文) | 您所在的位置:网站首页 › 优化模型的优点和缺点 › 深度学习中backbone网络优缺点(附图文) |
深度学习中backbone网络优缺点(附图文)
backbone
VGG系列
采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少),例如用三个33取代77后感受野不变,下面参数量对比: 一个7 x 7的卷积核参数量是 77input_channel* output_channel 三个3 x 3的卷积核参数量是 333input_channel output_channel  VGG优缺点
VGG优缺点
优点: (1)VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2) (2)几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好,增加了网络的非线性表达能力。 (3)验证了通过不断加深网络结构可以提升性能。 缺点: (1)参数量太大(140M),导致网络训练起来速度慢,主要原因是VGG有三个FC层,有论文称去掉这三个FC层,对网络的性能没什么影响。 ResNet随着网络的加深,一般伴随以下几个问题: (1)容易出现梯度消失/梯度爆炸 (2)网络加深,网络的非线性表达能力加强,容易导致model出现过拟合 (3)计算资源消耗巨大 梯度消失/梯度爆炸问题的产生:因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑用ReLU激活函数取代sigmoid激活函数。在反向传播过程中需要对参数进行求导,如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。Resnet为了解决这一现象提出了残差结构 新的模型缩放方法,它使用一个简单而高效的复合系数来以更结构化的方式放大 CNNs。 不像传统的方法那样任意缩放网络维度,如宽度,深度和分辨率,该论文的方法用一系列固定的尺度缩放系数来统一缩放网络维度。 通过使用这种新颖的缩放方法和 AutoML 技术,作者将这种模型称为 EfficientNets ,它具有最高达10倍的效率(更小、更快),探究CNN的深度,宽度,分辨率的这三者的关系平衡从而达到更好的accuracy-efficiency trade-off。 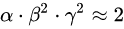 的约束下;STEP 2:接着我们固定 α ,β,γ作为约束,然后利用不同取值的 Φ 对baseline网络做放大,来获得Efficient-B1到B7;
MobileNet系列 的约束下;STEP 2:接着我们固定 α ,β,γ作为约束,然后利用不同取值的 Φ 对baseline网络做放大,来获得Efficient-B1到B7;
MobileNet系列
mobilenet整体结构和之前大多数网络不一样的主要有两点: (1)用了depthwise separable convolution来提高网络的计算速度,depthwise separate convolution包含了depthwise convolution和pointwise convolution. (2)采用了Width Multiplier,Width Multiplier简单来说就是引入一个新的超参数来调节卷积输出的通道数从而更方便的平衡了网络的计算速度和精度。 |
 下面为ResNet不同版本对应的网络结构
下面为ResNet不同版本对应的网络结构  对于跳跃连接时,当输入与输出的维度一样时,不需要做其他处理,两者相加就可,但当两者维度不同时,输入要进行变换以后去匹配输出的维度,主要经过两种方式,1)用zero-padding去增加维度,2)用1x1卷积来增加维度。
对于跳跃连接时,当输入与输出的维度一样时,不需要做其他处理,两者相加就可,但当两者维度不同时,输入要进行变换以后去匹配输出的维度,主要经过两种方式,1)用zero-padding去增加维度,2)用1x1卷积来增加维度。  上图右边为瓶颈残差块,主要是为了降低参数,左边参数量差不多为右边参数量的一倍,但是两者性能没有太大区别。
上图右边为瓶颈残差块,主要是为了降低参数,左边参数量差不多为右边参数量的一倍,但是两者性能没有太大区别。 这里的都是由一个很小范围的网络搜索得到的常量,直观上来讲, 是一个特定的系数,可以控制用于资源的使用量。efficientnet是搜索到的,搜索目标是:
这里的都是由一个很小范围的网络搜索得到的常量,直观上来讲, 是一个特定的系数,可以控制用于资源的使用量。efficientnet是搜索到的,搜索目标是: 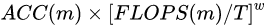
【本文地址】