| Python | 您所在的位置:网站首页 › 从文件中读取数据可以创建哪一个类的对象 › Python |
Python
|
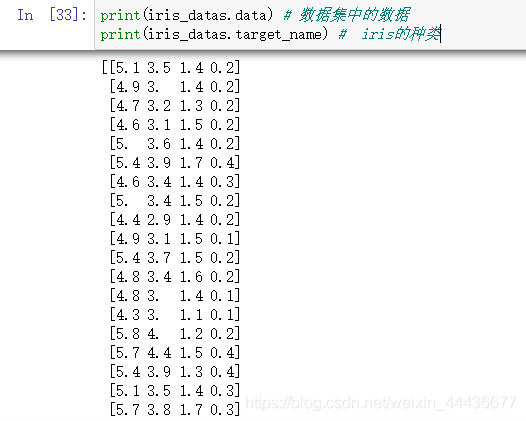
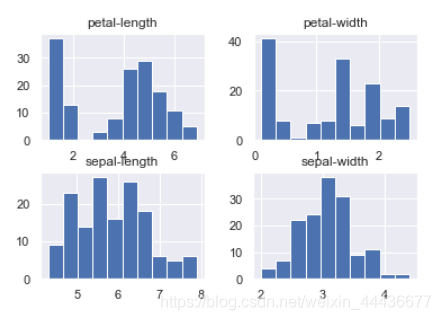
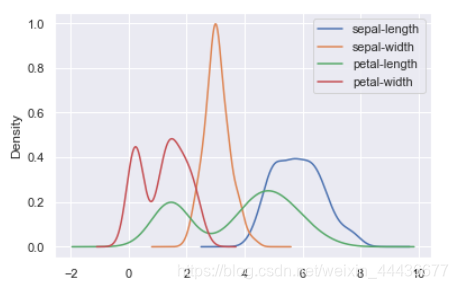
本博客运行环境为Jupyter Notebook、Python3。使用的数据集是鸢尾花数据集(Iris)。主要叙述的是数据可视化。 IRIS数据集以鸢尾花的特征作为数据来源,数据集包含150个数据集,有4维,分为3 类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中常用的测试集、训练集。 读取数据包括sklearn库引入和读取.csv文件保存的数据集。 显示数据包括显示具体数据、查看整体数据信息、描述性统计。 数据可视化包括散点图、直方图、KDE图、箱线图。 目录 读取数据显示数据数据可视化 读取数据从sklearn库中读取:(我使用的是该种办法) ,因为文件运行起来总缺少一组数据,可文件本身打开显示数据是完整的,这个问题我还未解决。如有知道的同学欢迎帮忙指点一下。 此问题已解决,如有问题的小伙伴可以将文件读取改为这句代码!Iris = pd.read_csv(r’Iris.csv’,header = None) from sklearn import datasets import pandas as pd iris_datas = datasets.load_iris()从文件中读取: 路径应该更为相应的的文件存储路径。 import pandas as pd #Iris = pd.read_csv('iris.csv') Iris = pd.read_csv(r'Iris.csv',header = None) 显示数据显示所有数据: print(iris_datas.data) # 数据集中的数据 print(iris_datas.target_name) # iris的种类运行结果如下: 运行结果如下: SepaLengthCm: 花萼长度, 单位cm;SepalWidthCm: 花萼宽度, 单位cm;PetalLengthCm: 花瓣长度, 单位cm ;PetalWidthCm; 花瓣宽度, 单位cm 运行结果如下: 运行结果如下: 150行, 4个64位浮点数,数据中无缺失值。 运行结果如下: 花萼长度最小值4.30, 最大值7.90, 均值5.84, 中位数5.80, 右偏;花萼宽度最小值2.00, 最大值4.40, 均值3.05, 中位数3.00, 右偏;花瓣长度最小值1.00, 最大值6.90, 均值3.76, 中位数4.35, 左偏;花瓣宽度最小值0.10, 最大值2.50, 均值1.20, 中位数1.30, 左偏。 按中位数来度量: 花萼长度 > 花瓣长度 > 花萼宽度 > 花瓣宽度 运行结果如下: 花萼长度与宽度/花瓣长度与宽度的可视化 from collections import Counter, defaultdict import matplotlib import matplotlib.pyplot as plt import numpy as np matplotlib.rcParams['font.sans-serif'] = ['SimHei'] style_list = ['o', '^', 's'] # 设置点的不同形状,不同形状默认颜色不同,也可自定义 data = iris_datas.data labels = iris_datas.target_names cc = defaultdict(list) for i, d in enumerate(data): cc[labels[int(i/50)]].append(d) p_list = [] c_list = [] for each in [0, 2]: for i, (c, ds) in enumerate(cc.items()): draw_data = np.array(ds) p = plt.plot(draw_data[:, each], draw_data[:, each+1], style_list[i]) p_list.append(p) c_list.append(c) plt.legend(map(lambda x: x[0], p_list), c_list) plt.title('鸢尾花花瓣的长度和宽度') if each else plt.title('鸢尾花花萼的长度和宽度') plt.xlabel('花瓣的长度(cm)') if each else plt.xlabel('花萼的长度(cm)') plt.ylabel('花瓣的宽度(cm)') if each else plt.ylabel('花萼的宽度(cm)') plt.show()运行结果如下: 数据直方图 之前已经使用过describe()计算出四个属性所对应的四分位数, 最大值以及最小值等统计量。这些均是以表格的形式展示。 url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'] dataset = pd.read_csv(url, names=names) dataset.hist() #数据直方图histograms运行结果如下: 运行结果如下: KDE图 KDE图也被称作密度图(Kernel Density Estimate,核密度估计)。 dataset.plot(kind='kde')运行结果如下:
|
 读取前五行数据
读取前五行数据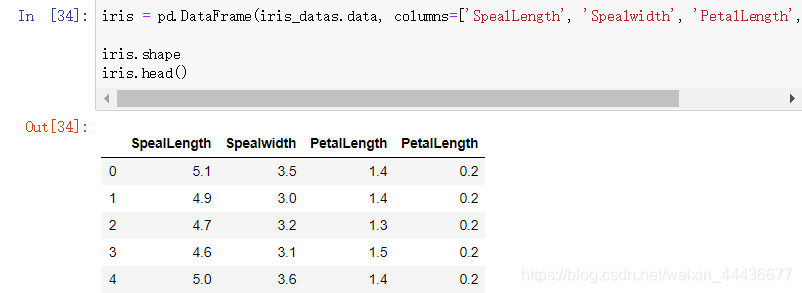 读取后五行数据
读取后五行数据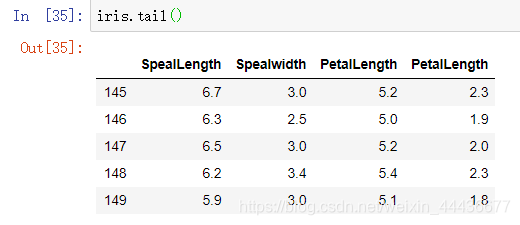 查看数据整体信息
查看数据整体信息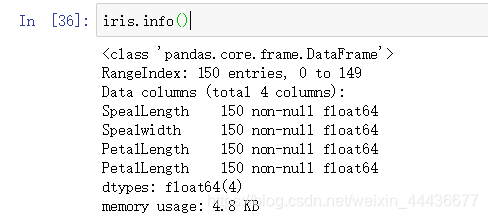 描述性统计
描述性统计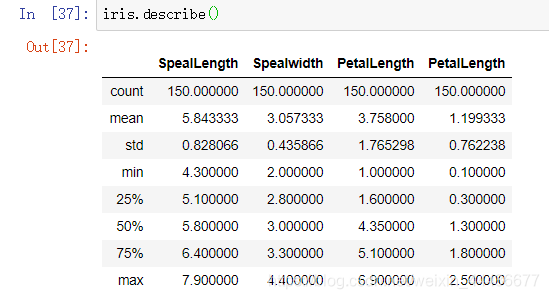 描述性统计转置
描述性统计转置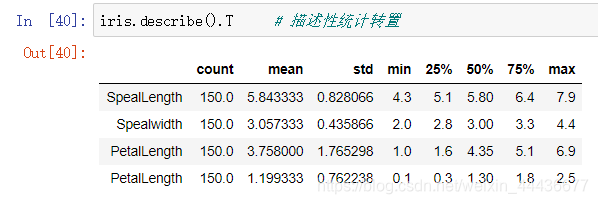
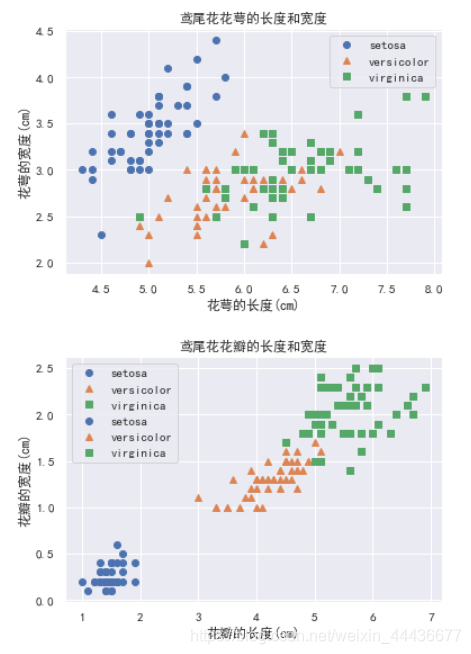
 散点图 x轴表示sepal-length花萼长度,y轴表示sepal-width花萼宽度
散点图 x轴表示sepal-length花萼长度,y轴表示sepal-width花萼宽度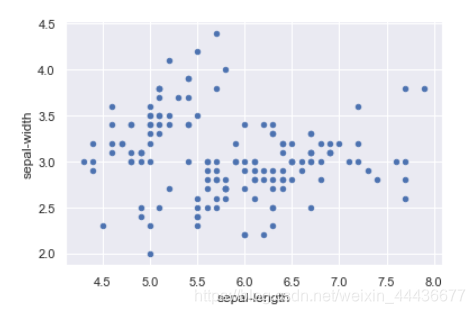
 箱线图 kind='box’绘制箱图,包含子图且子图的行列布局layout为2*2,子图共用x轴、y轴刻度,标签为False。
箱线图 kind='box’绘制箱图,包含子图且子图的行列布局layout为2*2,子图共用x轴、y轴刻度,标签为False。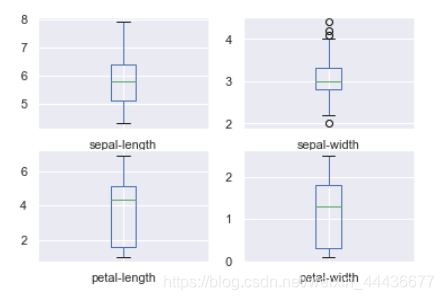
【本文地址】