| 散列查找 | 您所在的位置:网站首页 › 什么是哈希查找 › 散列查找 |
散列查找
|
散列表相关概念 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。建立了关键字与存储位置的映射关系,公式如下: 存储位置 = f(关键字)这里把这种对应关系f称为散列函数,又称为哈希(Hash)函数。 采用散列技术将记录存在在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表。那么,关键字对应的记录存储位置称为散列地址。 散列技术既是一种存储方法也是一种查找方法。散列技术的记录之间不存在什么逻辑关系,它只与关键字有关,因此,散列主要是面向查找的存储结构。 散列函数的构造方法 2.1 直接定址法 所谓直接定址法就是说,取关键字的某个线性函数值为散列地址,即 2.2 数字分析法 如果关键字时位数较多的数字,比如11位的手机号”130****1234”,其中前三位是接入号;中间四位是HLR识别号,表示用户号的归属地;后四为才是真正的用户号。如下图所示。 如果现在要存储某家公司的登记表,若用手机号作为关键字,极有可能前7位都是相同的,选择后四位成为散列地址就是不错的选择。若容易出现冲突,对抽取出来 的数字再进行反转、右环位移等。总的目的就是为了提供一个散列函数,能够合理地将关键字分配到散列表的各个位置。 数字分析法通过适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布比较均匀,就可以考虑用这个方法。 2.3 平方取中法 这个方法计算很简单,假设关键字是1234,那么它的平方就是1522756,再抽取中间的3位就是227,用做散列地址。 平方取中法比较适合不知道关键字的分布,而位数又不是很大的情况。 2.4 折叠法 折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。 比如关键字是9876543210,散列表表长为三位,将它分为四组,987|654|321|0,然后将它们叠加求和987 + 654 + 321 + 0 = 1962,再求后3位得到散列地址962。 折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。 2.5 除留余数法 此方法为最常用的构造散列函数方法。对于散列表长为m的散列函数公式为: 2.6 随机数法 选择一个随机数,取关键字的随机函数值为它的散列地址。也就是f(key) = random(key)。这里random是随机函数。当关键字的长度不等时,采用这个方法构造散列函数是比较合适的。 总之,现实中,应该视不同的情况采用不同的散列函数,这里只能给出一些考虑的因素来提供参考: (1)计算散列地址所需的时间 (2)关键字的长度; (3)散列表的长度; (4)关键字的分布情况; (5)记录查找的频率。 综合以上等因素,才能决策选择哪种散列函数更合适。 处理散列冲突的方法 在理想的情况下,每一个关键字,通过散列函数计算出来的地址都是不一样的,可现实中,这只是一个理想。市场会碰到两个关键字key1 != key2,但是却有f(key1) = f(key2),这种现象称为冲突。出现冲突将会造成查找错误,因此可以通过精心设计散列函数让冲突尽可能的少,但是不能完全避免。 3.1 开放定址法 所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。 它的公式为: 考虑深一步,如果发生这样的情况,当最后一个key = 34,f(key) = 10,与22所在的位置冲突,可是22后面没有空位置了,反而它的前面有一个空位置,尽管可以不断地求余后得到结果,但效率很差。因此可以改进di=12, -12, 22, -22………q2, -q2(q |
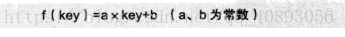 优点:简单、均匀,也不会产生冲突。 缺点:需要事先知道关键字的分布情况,适合查找表较小且连续的情况。 由于这样的限制,在现实应用中,此方法虽然简单,但却并不常用。
优点:简单、均匀,也不会产生冲突。 缺点:需要事先知道关键字的分布情况,适合查找表较小且连续的情况。 由于这样的限制,在现实应用中,此方法虽然简单,但却并不常用。
 mod是取模(求余数)的意思。事实上,这方法不仅可以对关键字直接取模,也可以再折叠、平方取中后再取模。 很显然,本方法的关键在于选择合适的p,p如果选不好,就可能会容易产生冲突。 根据前辈们的经验,若散列表的表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。
mod是取模(求余数)的意思。事实上,这方法不仅可以对关键字直接取模,也可以再折叠、平方取中后再取模。 很显然,本方法的关键在于选择合适的p,p如果选不好,就可能会容易产生冲突。 根据前辈们的经验,若散列表的表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。 比如说,关键字集合为{12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34},表长为12。散列函数f(key) = key mod 12。 当计算前5个数{12, 67, 56, 16, 25}时,都是没有冲突的散列地址,直接存入,如下表所示。
比如说,关键字集合为{12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34},表长为12。散列函数f(key) = key mod 12。 当计算前5个数{12, 67, 56, 16, 25}时,都是没有冲突的散列地址,直接存入,如下表所示。  计算key = 37时,发现f(37) = 1,此时就与25所在的位置冲突。于是应用上面的公式f(37) = (f(37) + 1) mod 12 =2,。于是将37存入下标为2的位置。如下表所示。
计算key = 37时,发现f(37) = 1,此时就与25所在的位置冲突。于是应用上面的公式f(37) = (f(37) + 1) mod 12 =2,。于是将37存入下标为2的位置。如下表所示。  接下来22,29,15,47都没有冲突,正常的存入,如下标所示。
接下来22,29,15,47都没有冲突,正常的存入,如下标所示。  到了48,计算得到f(48) = 0,与12所在的0位置冲突了,不要紧,我们f(48) = (f(48) + 1) mod 12 = 1,此时又与25所在的位置冲突。于是f(48) = (f(48) + 2) mod 12 = 2,还是冲突……一直到f(48) = (f(48) + 6) mod 12 = 6时,才有空位,如下表所示。
到了48,计算得到f(48) = 0,与12所在的0位置冲突了,不要紧,我们f(48) = (f(48) + 1) mod 12 = 1,此时又与25所在的位置冲突。于是f(48) = (f(48) + 2) mod 12 = 2,还是冲突……一直到f(48) = (f(48) + 6) mod 12 = 6时,才有空位,如下表所示。  把这种解决冲突的开放定址法称为线性探测法。
把这种解决冲突的开放定址法称为线性探测法。【本文地址】