| 基于coco数据集的人体关键点分布示意图与数据集解析 | 您所在的位置:网站首页 › 人体肩部示意图 › 基于coco数据集的人体关键点分布示意图与数据集解析 |
基于coco数据集的人体关键点分布示意图与数据集解析
|
本文绘制了coco中人体姿态关键点的分布示意图,并解释了每个关键点的含义。 目录 1、数据集介绍 2、示意图 3、数据集解析 1、数据集介绍有pose标注的部分数据样式如下:
每张图中有若干个segment标注,每个标注包含的信息如下: {"segmentation":[[0.43,299.58,2.25,299.58,9.05,287.78,32.66,299.13,39.01,296.4,48.09,290.96,43.55,286.87,62.16,291.86,61.25,286.87,37.65,279.15,18.13,272.8,0,262.81]], "num_keypoints":1, "area":1037.7819, "iscrowd":0, "keypoints":[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,9,277,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], "image_id":397133, "bbox":[0,262.81,62.16,36.77], "category_id":1, "id":1218137}我们所需要的就是其中的'keypoints'部分,每三个数字为一组,代表一个关键点,三个值分别为x坐标、y坐标、标志位,其中,标志位有三个值: 0:未标注1:标注,但被遮挡2:标注,未遮挡 2、示意图下图中,共17个关节点(鼻子x1、眼睛x2、耳朵x2、肩部x2、肘部x2、手腕x2、髋部x2、膝关节x2、脚腕x2):
我们从coco2017中解析数据集并保存为YOLO格式,这种格式可以直接用YOLOv5或者YOLOv8进行训练: """ get person instance segmentation annotations from coco data set. """ import argparse import os import numpy as np import tqdm import shutil from pycocotools.coco import COCO def main(args): annotation_file = os.path.join(args.input_dir, 'annotations', 'person_keypoints_{}.json'.format(args.split)) # init path subdir = args.split[:-4] + '_coco2' img_save_dir = os.path.join(args.output_dir, subdir, 'images') txt_save_dir = os.path.join(args.output_dir, subdir, 'labels') os.makedirs(img_save_dir, exist_ok=True) os.makedirs(txt_save_dir, exist_ok=True) coco = COCO(annotation_file) catIds = coco.getCatIds() imgIds = coco.getImgIds() print("catIds len:{}, imgIds len:{}".format(len(catIds), len(imgIds))) for imgId in tqdm.tqdm(imgIds, ncols=100): img = coco.loadImgs(imgId)[0] annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None) anns = coco.loadAnns(annIds) if len(annIds) > 0: img_origin_path = os.path.join(args.input_dir, args.split, img['file_name']) img_height, img_width = img['height'], img['width'] lines = [] for ann in anns: # if ann['iscrowd'] != 0 or ann['category_id'] != 1: # continue bbox = np.asarray(ann['bbox'], dtype=float) # x1y1wh bbox[::2] = bbox[::2] / img_width bbox[1::2] = bbox[1::2] / img_height # x1y1wh2xywh bbox[0] += bbox[2] / 2 bbox[1] += bbox[3] / 2 bbox_str = [str(b) for b in bbox] keypoints = np.asarray(ann['keypoints'], dtype=float) keypoints[::3] = keypoints[::3] / img_width keypoints[1::3] = keypoints[1::3] / img_height keypoints_str = [str(k) for k in keypoints] line = '{} {} {}'.format(0, ' '.join(bbox_str), ' '.join(keypoints_str)) lines.append(line) if len(lines) > 0: txt_output_path = os.path.join(txt_save_dir, os.path.splitext(img['file_name'])[0] + '.txt') with open(txt_output_path, 'a') as f: for line in lines: f.write(line + '\n') img_output_path = os.path.join(img_save_dir, img['file_name']) shutil.copy(img_origin_path, img_output_path) def get_args(): parser = argparse.ArgumentParser() parser.add_argument("--input_dir", default="/data/public_datasets/coco2017", type=str, help="input dataset directory") parser.add_argument("--split", default="val2017", type=str, help="train2017 or val2017") parser.add_argument("--output_dir", default="/data/datasets/person_pose", type=str, help="output dataset directory") return parser.parse_args() if __name__ == '__main__': args = get_args() main(args)参考: COCO - Common Objects in Context |





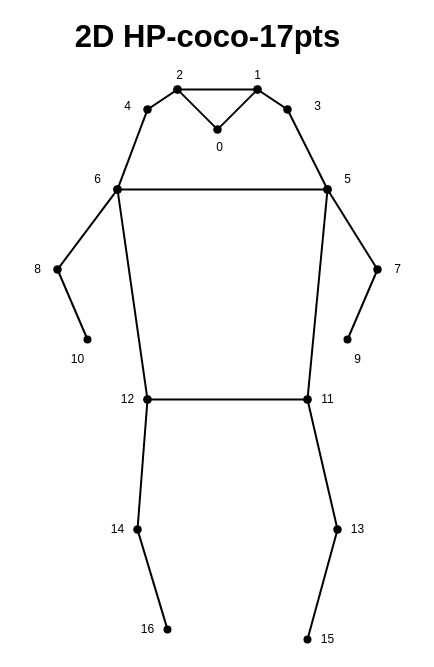
【本文地址】
公司简介
联系我们