| 一文读懂空间杜宾 | 您所在的位置:网站首页 › 交互项系数不显著怎么处理 › 一文读懂空间杜宾 |
一文读懂空间杜宾
|
目录 一.基本知识及操作 1.基础知识 1.1空间矩阵(w):用来表示平面数据之间的空间距离权重的,是特别重要的参数,可以是经济,空间,其他等区域上的差异距离。(我们是做空间的关系的,所以需要有个代表这个关系的矩阵来表示) 1.2莫兰指数(I):主要是用来检验数据是否存在空间自相关,才能进行空间杜宾模型呀!当然还有其他许多的检验方法。 1.3几种重要模型之间关系: 1.4 其他干货 1.4.1推荐书籍 1.4.2 数据收集与处理 2.操作 2.1 数据获取及相应程序包 2.1.1 第一套:关于犯罪率的数据 2.1.2 第二套:关于面板数据 2.2先自己设置好空间计量矩阵(w) 2.3跑莫兰指数等各类检验指数 2.3.1整体的莫兰检验 2.3.2局部莫兰指数: 2.3.3 分年份的莫兰指数及散点图绘图 2.4 模型的选择(LM,LR,Wald检验) 2.4.1基本整体检验逻辑: 2.4.2 LM检验 2.4.3 LR检验 LR检验-模型选择(sdm,sar,sem) LR 检验-个体时空-时间固定效应模型 2.4.4 Wald检验 2.5模型的回归输出 2.5.1空间自回归模型 2.5.2空间误差模型估计 2.5.3空间杜宾模型估计 2.6选择固定效应还是随机效应模型 2.6.1理论基础 2.6.2实际操作 2.7 反距离矩阵与经济距离矩阵稳健性检验 2.7.1基本概念解释 2.7.2实际操作 2.8 滞后多期稳健性检验 2.8.1 滞后操作 2.8.2滞后结果 2.9 空间调节(中介)效应回归 2.9.1 基本概念 2.9.2 实际操作 2.10 空间异质性检验 2.10.1 相关基本概念 2.10.2 地区异质性分析 2.11 门槛回归及门限效应 2.12 内生性检验 2.13 其他常见知识补充 2.13.1 异方差 2.13.2 多重共线性 2.13.3 其他 2.14常见报错汇总 2.14.1矩阵不匹配的错 二.论文实战 三.反思总结 --------------------------干货比较多,请耐心看完哦,相信会有收获哒----------- 阅读导读:通过这篇文章你能收获到啥? 1.空间杜宾模型的所有基础知识及实际操作 2.空间杜宾模型在截面数据或者面板数据方面的应用,但是这里面有很多坑,需要你我一起慢慢解决哈,模仿只能解决小问题,真正的技术是创新,而创新不可能直接展现。 3.免费的真实论文实战数据及结果(冲击C刊,300块的面板数据免费分享,妈妈在也不用担心我的论文,引用可以直接引用我的文章。)主打就是交个朋友。 4.完整的空间杜宾论文书写体系。 5.这里参考这篇文章:准确衡量数字经济的创新效应——基于数字溢出视角_刘宏楠 6.写的不好,可能会有错误,希望读者可以给予指点迷津,谢谢! 7.实在很难看懂的同学可以私聊,我有空会细讲 ----------------------------点赞关注不迷路!玩的就是真实,开干!!!-------------- 一.基本知识及操作 1.基础知识空间杜宾模型研究的目标是空间上面存在的一些相关关系,来帮助我们更好的了解事物的社会关系。 1.1空间矩阵(w):用来表示平面数据之间的空间距离权重的,是特别重要的参数,可以是经济,空间,其他等区域上的差异距离。(我们是做空间的关系的,所以需要有个代表这个关系的矩阵来表示)比如:我国31各省份之间的空间距离矩阵,可以根据空间经纬度关系,若存在相邻就为1,不存在就为0. 当然还有其他关系,比如经济关系等。 省份空间矩阵的数据如下: 0-1权重矩阵.xlsx 地理距离矩阵(基于经纬度距离)附原始数据.xlsx 36.7K 补充:关于空间距离关系的分类 空间地理位置的相邻关系分类有三种,相邻关系选择需要看实际的相邻情况。
比如当省份和省份之间的高速公路有点多,或者物流频次明显,则应当判定为1,即应当判定为有空间上的相邻关系哦,根据实际情况采用不同的相邻方式来调节莫兰指数的显著性。 1.2莫兰指数(I):主要是用来检验数据是否存在空间自相关,才能进行空间杜宾模型呀!当然还有其他许多的检验方法。01:整体莫兰检验
一般是在-1到1之间,越接近0表示越没有空间自相关,高值对应高值,低值对应低值,定义为正自相关,反之负相关。 02:局部莫兰检验 当然也存在局部空间自相关指标(目的是衡量某个地域与其周围的差异情况,来表示其周围的高低分布情况差异情况,0表示局部之间没有差异,1代表局部之间有正向相关,高对高,低对低等关系),在下面的操作会有讲到。 03:分年份莫兰检验 对于面板数据还有分年份的莫兰指数检验,具体如下图:
分年份的31个省份的莫兰指数检验 补充:如果不显著咋办?第一步就寄了咋办? 你说咋办,去试试啊,可以取对数,取差分,作协整,换变量等等一系列操作,第一步其实根本就限制不了你,真正能限制你的只有你自己的认知和学识,赶紧去补习一下计量经济学理论。 1.3几种重要模型之间关系:SDM 模型(空间杜宾模型)
第一部分是y的空间自回归项,第二部分是关于x的回归,第三部分是关于x的空间回归,第四部分是标准误差
这是一个简单的关于空间杜宾模型的例子,里面还包括了控制变量 SAR模型(空间自相关模型)(是SDM模型去掉和其他地域变量之间的回归可能性)
对应的改编成实际的可行方程 SEM(空间误差模型)(是不存在区域滞后影响关系,但误差存在空间差异,即误差存在空间相关)
那实际进行实证分析的时候到底采用哪种分析模型呢?如何判别呢? 请看2.4 模型的选择。 以上只是带大家简单了解一下关于空间杜宾模型的一些基础知识啦 1.4 其他干货 1.4.1推荐书籍1.高级计量经济学及STATA应用 2.基本无害的计量经济学 3.傻瓜计量经济学与stata应用 关于Eviews10的一些常见操作合集 - 统计猿的文章 - 知乎 关于Eviews10的一些常见操作合集 - 知乎 1.4.2 数据收集与处理面板数据收集 数据收集与处理-缺失值处理-统计局官网数据一文读懂所有 - 统计猿的文章 - 知乎 你似乎来到了没有知识存在的荒原 - 知乎 面板数据标准化 面板数据标准化是将一个变量的各期数据汇总处理,还是分期处理呢? - 统计猿的回答 - 知乎 面板数据标准化是将一个变量的各期数据汇总处理,还是分期处理呢? - 知乎 2.操作 2.1 数据获取及相应程序包 2.1.1 第一套:关于犯罪率的数据http://web.pdx.edu/~crkl/WISE/SEAUG/data/anselin 2.1.2 第二套:关于面板数据链接:https://pan.baidu.com/s/1JApxxaOFNYh6_2HGcYI3Sg 提取码:6666 链接https://pan.baidu.com/s/12aI83ZH0xaHOPMnYfOL7SQ
提取码:6666 数据说明: 1.这里有2套数据,一套面板数据,一套截面数据,具体用那一套我会标出来,代码是差不多得。 2.空间权重矩阵的数据你们根据原始数据自己调节哈!是31个省份就做31个省份(理由:不想丢失数据),是30个省份就30个省份(理由:去掉西藏),还有就是经济距离(你研究所在年份的人均GDP)和反距离矩阵(你研究所采用的省份或区域)都要自己调哈! 这里下面有时候会出现其他的面板数据截图,那个是我自己论文的数据,我之后会分享,先学会方法,在想着如何创新,找选题;同时我也得保证数据的优质性,冒然放上去,到时候一堆人说不行,那不是害人嘛?让我在深化一段时间,这里对我论文的数据做一个简单的说明: 城乡融合发展水平(uid)被解释变量数字普惠金融指数(dif)中介/调节变量数字经济发展水平(ded)核心解释变量对外开放程度(dotw)控制变量固定资产投资水平(ilfa控制变量金融发展水平(fdl)个体效应变量人均国民生产值(pgdp)个体效应变量教育水平(edu)控制变量相应的空间杜宾模型程序包是不用下载的,本来就有可以直接调用,要下载的我会说。 2.2先自己设置好空间计量矩阵(w)数据是对应第一套里面的columbusswm spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\columbusswm.dta",name(w)
空间矩阵图 2.3跑莫兰指数等各类检验指数 2.3.1整体的莫兰检验
结合图示结果可知,三个检验均是拒绝原假设,即存在显著的空间自相关。这里说明犯罪率是存在显著空间自相关的。 虽然犯罪率是具有空间相关性的,但是哪里是犯罪率的空间相关高点,那些地方之间的相关性更大,有没有排名等问题,下面继续学习。 2.3.2局部莫兰指数: spatlsa crime,w(w) moran twotail spatlsa crime,weight(w) moran id(id) graph (moran) symbol(id)
结合图示可知,各个地区的相应莫兰指数,用来代表各个地区同其相邻地区之间的差异程度,是如何的分布情况,比如第一个的莫兰指数是1.586,则说明该地域和其周围地域是局部正向相关的。 那我如何更加可视化的表达出来呢?继续看下文哈! 2.3.3 分年份的莫兰指数及散点图绘图可以参考这篇文章:别人已经给你安排好啦!!! Stata:面板数据的莫兰指数计算与散点图绘制-xtmoran| 连享会主页 (lianxh.cn) 2.4 模型的选择(LM,LR,Wald检验) 2.4.1基本整体检验逻辑:1.先确定是随机(re)还是固定(fe)--------husman检验 2.在确定是个体还是时间还是混合---------LR-个体(ind),时间(time),混合(both)检验 3.在确定是选sar,sem,sdm那一个---------lm,lr,wald检验 检验结果解释lm不稳建的检验稳健的检验lr不稳建的检验稳健的检验waldsem/sdmsar/sdm 2.4.2 LM检验LM检验-----截面数据 先进行简单的ols回归,回归数据还是采用columbusdata.dta,犯罪率那套数据,前面放过链接,自己取就行 代码:(代码不是让你照着抄,而是你要自己改一下路径,你数据放在哪里就改哪里) spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\columbusdata.dta",name(w) spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\columbusswm.dta",name(w) reg crime hoval income spatdiag,weights(w)结果: 回归结果:
先做个简单的ols回归 结合回归结果可以看出普通的ols模型的t检验是显著的,即房价,收入和犯罪率之间是显著负向影响的,房价越高,收入越高,犯罪率就会下降。 LM检验结果:
LM检验结果 这里的检验有2部分: 第一部分是:spatial error(空间误差模型检验),可以看到有一个拒绝了“无空间自相关”假设;第二部分是:spatial lag(空间滞后模型检验),可以看到2个都拒绝了“无空间自相关”假设。 则说明模型是有空间自相关性的,选择空间自相关模型是合理的,反之就应该选择一般的模型,比如做双重差分。 LM检验-----面板数据 针对面板数据,还需要另外对数据和矩阵做匹配,上文介绍的仅仅是空间地域数据,没涉及时间维度的,面板数据的lm检验具体代码如下: **代表注释,不是代码,不要粘进去 **更改一下原始路径 cd "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\" **导入空间矩阵 use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\juli.dta" **对空间矩阵进行扩容,匹配目标面板数据 spcs2xt c1- c30,matrix(w)time(11) **计算空间矩阵,命名为w spatwmat using wxt,name(w) standardize **保存一下 save "wxt.dta", replace **导入面板数据,导不进去就直接在编辑览里面进行复制粘贴 use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\操作数据.xlsx" **对数据进行基本设置 global ylist y global xlist x1 x2 x3 x4 x5 x6 xtset id year **OLS估计 reg y x1 x2 x3 x4 x5 x6 x7 **LM检验 spatdiag,weights(w)结果
很明显模型通过检验,适合做空间杜宾模型,这里我说清楚,一般只要一样过了一个就说明能拒绝原假设,接受存在空间自相关效应的哦,要不要严格自己根据自己的论文水准来。 2.4.3 LR检验 LR检验-模型选择(sdm,sar,sem)代码: 注意:这里需要把数据权重矩阵换回来,换成31*31的才能运行成功具体下面会有代码,否则会报如下错。
结果:
LR检验最终结果 LR 检验-个体时空-时间固定效应模型利用lr检验空间杜宾模型到底选择时间固定模型还是个体固定模型还是双固定模型 代码: spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\julim.dta",name(w) standardize use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\lnstatam.dta" global ylist lnuid global xlist lnded lndotw lnilfa lnfdl lnpgdp lnedu xtset id year **空间杜宾下的双固定效应模型结果 xsmle $ylist $xlist,fe model(sdm) wmat(w) type(both) nolog noeffects est store both **空间杜宾下的时间固定效应模型结果 xsmle $ylist $xlist,fe model(sdm) wmat(w) type(time) nolog noeffects est store time **空间杜宾下的个体固定效应模型结果 xsmle $ylist $xlist,fe model(sdm) wmat(w) type(ind) nolog noeffects est store ind **lr检验,df代表自由度,先不写,软件会告诉你咋搞,之后在填上去就行 lrtest both time,df(14) lrtest both ind,df(14)结果:
时空-时间固定效应模型检验结果 解析: 根据结果,可以看出双固定-时间lr检验结果与双固定-时间lr检验结果都在1%的水平下显著,即都拒绝原假设,即应当选择双固定效应的空间杜宾模型(原假设:有限制的个体效应,时间效应) 2.4.4 Wald检验代码: cd "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\" spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\julim.dta",name(w) standardize **这一步自己从excel自己复制粘贴数据进去,发现跑不了就自己粘贴一下数据 use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\end_data.dta" global ylist y global xlist x1 x2 x3 x4 x5 x6 x7 xtset id year **下面才是Wald检验部分,这里的变量自己对应着改,别直接复制粘贴,自己也要动动脑子。 xsmle $ylist $xlist,wmat(w) model(sdm) fe type(ind) vce(cluster id) nolog test [Wx]x1 =[Wx]x2 =[Wx]x3 =[Wx]x4 =[Wx]x5 =[Wx]x6 =[Wx]x7 =0 **SDM和SEM进行检验,在提醒一遍不要简单复制,你得按照自己得文件路径和变量相应变换呀!!! testnl ([Wx]ded = -[Spatial]rho*[Main]ded) ([Wx]dotw = -[Spatial]rho*[Main]dotw) ([Wx]ilfa = -[Spatial]rho*[Main]ilfa) ([Wx]fdl = -[Spatial]rho*[Main]fdl) ([Wx]pgdp = -[Spatial]rho*[Main]pgdp) ([Wx]edu = -[Spatial]rho*[Main]edu)结果:
SDM/SAR检验结果
SDM/SEM检验结果 最终成表的效果及解读:
空间计量模型结果检验 结果表明:LM 检验统计量均在 5%水平上显著,表明选择空间计量模型的合理性;LR 检验统计量均在 5%水平上显著,强烈拒绝原假设,表明 SDM 模型不能退化为 SAR 模型或 SEM 模型;Wald 检验统计量同样在5%水平上显著,表明与 SEM 和 SAR 模型相比,选择 SDM 模型更优;LR 时间—时空效应检验均在 5%水平上拒绝原假设,表明选择 SDM 模型时,采用时间—时空双固定效应模型更有效。基于此,文章选择时间—时空双固定效应的空间杜宾模型进行分析更有效。 对表的制作做个简单说明: 有小伙伴说这个表的数据没对上,是否需要再次计算? 回答:不用哈,我这个结果只是一个示例表,不需要重新跑数据哈,你就按照回归系数、显著性*、p值,把自己跑出来的数据整理好就行,之后我会把整个论文的制作流程都分享给大家,帮助大家检验和学习自己对实证方面的技术是否到位,相应的代码也会更新,请大家稍安勿燥! 下图是检验结果如果是相反的情况所采用的优先级: 参考论文为: 论Wald、LR和LM检验不一致时的选择依据,胡新明 A、B股之间的信息流动与波动溢出_赵留彦
判断标准次序,如果出现检验结果相悖判断次序 2.5模型的回归输出准备工作(数据采用的是columbusswm,犯罪率这个数据) **计算权重矩阵 spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\columbusswm.dta",name(w) standardize spatdiag,weights(w) **做个简单的ols回归 use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\columbusdata.dta",clear reg crime hoval income 2.5.1空间自回归模型代码: spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\columbusswm.dta",name(w) eigenval(E) spatreg crime hoval income,weights(w) eigenval(E) model(lag) nolog **eigenval(E)代表空间矩阵的特征向量,model(lag)代表空间滞后模型,nolog表示不显示迭代过程结果:
结合图示:空间自回归模型系数的估计值为0.055,且在1%的水平上显著,故存在空间自回归效应。 2.5.2空间误差模型估计代码: **紧跟上面的命令,模型改为了error,空间误差模型 spatreg crime hoval income,weights(w) eigenval(E) model(error) nolog结果:
结合图示:空间自回归模型系数的估计值为0.036,且在1%的水平上显著,故存在空间自回归效应。 2.5.3空间杜宾模型估计代码: xsmle uid ded dotw ilfa fdl pgdp edu,wmat(w) model(sdm) fe robust nolog effects ****源码: xsmle y x1 x2 x3,wmat(name1) emat(name2) dmat(name3) durbin(varlist) model(sdm) model(sac) model(sem) re(默认是随机) fe robust dlag type(ind) type(time) type(both) noeffects(默认情况下介绍) **对于空间杜宾模型的各个选项,下面有整理------------------------------------------------------------------------------------------------------- 对于这个xsmle的相关作用做一个简单的辨析:(怕有些宝宝不了解,想知道一下原理)
看不清看下面,谢谢 wmat(name) 指定空间自回归项的权重矩阵,name代表权重名字 dmat(name) 指定空间滞后回归的权重矩阵;默认情况是使用wmat()矩阵 durbin(varlist) 指定必须在空间上滞后的回归方程;默认情况是滞后于varlist中的所有自变量 re/fe fe代表固定,re代表随机 model(name) 模型选择包括sdm,sem,sar vce(vcetype) 可能是oim、opg、robust(不受时间上相关性影响的标准误差)、cluster-clustvar(不受空间截面分组上影响的标准误差)、dkraay# dlag(dlag) 在模型中包括时间滞后因变量、时空滞后因变量或两者 effects/noeffects 计算直接效应、间接效应和总效应,并将它们添加到e(b)中 noconstant 抑制模型中的常数项。仅用于重新估算 type(ind) type(time) type(both) type()指定固定效应的类型,ind是个体固定效应、time是时间固定效应、both是双向固定效应,这个关系到你到底选那个做固定效应,一般核心解释变量没不显著的情况下,都会选择时间-个体双固定效应。 具体参考这篇文章:【毕业论文】面板数据:混合回归、随机效应、固定效应和双固定效应的介绍和选择 - 小新胡说的文章 - 知乎 【毕业论文】面板数据:混合回归、随机效应、固定效应和双固定效应的介绍和选择 - 知乎 ------------------------------------------------------------------------------------------------------ SDM模型的相关内容
help xsmle就能看到 ----------------------------------------------------------------------------------------------------------- 结果:
结合结果可以知道关于空间杜宾模型的模型中的解释变量回归系数,也有相关的wx的空间交互变量的回归系数,还有空间杜宾模型的直接效应、间接效应、总效应分别是多少,是否显著,是否存在空间溢出效应,以及是否需要考虑空间溢出效应影响;同时你也可以获取到空间杜宾的模型系数及交互项系数还有相应的空间自相关系数rho值,分别的解释见下表。 补充: 空间杜宾模型的空间效应分解内容 1.空间效应分解模型 Y=aWY+bX+cWX a代表总效应,b代表了直接效应大小,c代表了间接效应大小。 2.各类指标解释作用表: 交互项系数(w*核心解释变量)代表周边地区核心解释变量能够促进(系数为正)/抑制(系数为负)本地区被解释变量提升空间自相关系数rho值(其必须显著,pchi2小于0.05的时候,表示拒绝原假设,认为应该选择固定效应模型。sar模型的hausman检验
结果表明:由于原假设是接受随机效应,当Prob >chi2大于0.05的时候,表示没有理由拒绝原假设,认为应该选择随机效应模型。 sdm模型的hausman检验
结果表明:由于原假设是接受随机效应,当Prob >chi2小于0.05的时候,表示拒绝原假设,认为应该选择固定效应模型。 2.7 反距离矩阵与经济距离矩阵稳健性检验 2.7.1基本概念解释1.反距离矩阵:就是利用两个地方的经纬度来计算两地的距离(类似于把地区看成圆求两个点的弧长),之后采用平方的倒数构建反距离矩阵。 基于距离越近权重越大,距离越远权重越小的原则 具体原理看下文: 【MATLAB】经纬度换算距离 - 知乎 (zhihu.com) 2.经济距离矩阵:通过两地的经济实力来计算两地经济上的距离,一般采用两地人均GDP之差的倒数来构建经济距离矩阵。(注:这里的两地人均GDP之差是你做论文所在年份区间内的人均GDP的平均数,别不换,直接拿别人的数据在哪里跑,不显著就真的寄了) 2.7.2实际操作相应的操作数据 它的操作步骤就是直接把矩阵换一下,跑一下空间杜宾回归就行啦!!!代码如下: 这个运行是持续的哈,记得前面重复前面基础代码哈。 **反距离矩阵核心代码 spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\fjulim.dta",name(w) standardize xsmle lnuid lnded lndotw lnilfa lnfdl lnpgdp lnedu,wmat(w) model(sdm) fe robust nolog effects **经济距离矩阵稳健性检验核心代码 spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\jjulim.dta",name(w) standardize xsmle lnuid lnded lndotw lnilfa lnfdl lnpgdp lnedu,wmat(w) model(sdm) fe robust nolog effects
反距离矩阵结果
经济距离矩阵结果 2.8 滞后多期稳健性检验 2.8.1 滞后操作 **目标是对我们的解释变量进行滞后多期操作,lnuid(被解释变量) use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\lnstatam.dta" spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\julim.dta",name(w) standardize global ylist lnuid global xlist lnded lndotw lnilfa lnfdl lnpgdp lnedu xtset id year **这里可以看到滞后两期,一般滞后一期做一下就行,滞后多期自己加数字就行,滞后到5,6期可以作为工具变量用于内生性检验 gen llnuid=l1.lnuid gen llnuid2=l2.lnuid **滞后了多期,所以需要填补一下数据哦,不然没法运行啦!!!这里采用外插法(两边缺失数据,不是内部缺数据) by id: ipolate llnuid year,gen(llnuid_1) epolate by id: ipolate llnuid2 year,gen(llnuid_2) epolate **跑个回归 xsmle lnuid llnuid_1 lnded lndotw lnilfa lnfdl lnpgdp lnedu,wmat(w) model(sdm) fe robust nolog effects 2.8.2滞后结果
跑回归的结果
数据整理结果 结论:为了进一步验证模型的平稳性,对空间杜宾模型采用滞后多期回归处理;结合下表可知,滞后一期的城乡产业融合发展水平系数在1%水平下显著为正,且滞后六期依然保持在1%显著性水平下系数显著为正,说明城乡产业融合发展的前一期的发展对后一期的发展具有显著的促进作用;在滞后的一期到六期的回归结果中,数字经济发展水平回归系数在10%显著性水平下不显著,而未滞后的数字经济发展水平回归系数在10%的显著性水平下显著,一定程度上说明模型具有良好的平稳性;结合下表知,滞后的1-6期的空间自相关系数rho都在10%的水平下显著,说明本地区城乡融合发展水平对其他地区的城乡融合发展水平有显著的空间效应,同时结合在滞后一期和二期的条件下空间自相关系数rho是显著为负的,而未滞后的模型空间自相关系数rho是显著为正的,一定程度上说明,本地区的城乡融合发展水平对其他地区的城乡融合发展水平的空间溢出效应是会随时间发生变化的。 2.9 空间调节(中介)效应回归 2.9.1 基本概念1.啥是调节效应?啥是中介效应? 调节效应就是类似于环境调节变量,它是一种侧面影响因素,用来调节自变量和因变量之间的关系,不是中间的效应,即不是中间所必须经过的路径。 中介效应,就是中间路径,它是一种直接效应,就是自变量和因变量之间必须通过中间这个变量才能完成传递。 有时候它们没分的那么细,有时候就稀里糊涂的随便混用,最好是不要混用哈! 2.基本的模型是啥样子的?有没有参考文献?如何做? 中介效应模型
中介效应实际例子
中介效应逻辑链条 中介效应说白了就是中间路径,它的升级版叫结构方程,就是多了几条路径。 参考文献有: 数字普惠金融、农业科技创新与农村产业融合发展_焦青霞 交通便利性、产业结构变迁与...基于省域面板数据的空间计量_魏思琪 2.9.2 实际操作很简单,分别跑回归就行 **数据自己导入一下,变量自己换一下就行 xtset id year gen lncptm=ln(cptm) gen lnded=ln(ded) gen lndotw=ln(dotw) gen lnilfa=ln(ilfa) gen lnfdl=ln(fdl) gen lnpgdp =ln(pgdp) gen lnedu =ln(edu) gen lninnovation=ln(innovation) global ylist lncptm global xlist lninnovation lnded lndotw lnilfa lnfdl lnpgdp lnedu reg $ylist $xlist跑完列张表:
中介回归表 调节效应模型 调节效应一般用在空间里面比较多,也比较喜欢做交互,有几个交互几个; 比如1个-------交互1次就行,AB交互一下就可以了 2个--------AB交互一次,AC交互一次,ABC交互一次,总共3次,这还要加上自己回归。 方法同上,自己做一下交互就行,别漏掉就行,看下图。
交互表 2.10 空间异质性检验 2.10.1 相关基本概念空间异质性:是指某空间单元观测值与其他空间单元观测值间存在的结构不稳定关系引起的观测值非同质的现象。 简单来讲:就是说你的观测值没办法在不同质的条件下对比,举个例子,一个是有钱人家的且生在书香门第且在美国出生长大的孩子和一个没钱且普通的孩子,有钱人家的孩子考的高一点,然后你的出结论,有钱能使得成绩提高,很显然,这个是在不同环境下,且可能学习方式,考核方式都具有很大不同的孩子,你得出这个普适性结论是不是不太合适欸。这个时候异质性分析就要上场了。 2.10.2 地区异质性分析我们对我国31各省份按照东部,西部,中部,东北部进行相应的划分来进行异质性分析看看情况。 说明:东、西、中、东北四大区域是根据国家统计局官网提供按照经济发展情况划分的区域,具体如下: 东部包括:北京、天津、河北、上海、江苏、浙江、福建、山东、广东和海南。 中部包括:山西、安徽、江西、河南、湖北和湖南。 西部包括:内蒙古、广西、重庆、四川、贵州、云南、西藏、陕西、甘肃、青海、宁夏和新疆。 东北包括:辽宁、吉林和黑龙江。代码: cd "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\" **形成空间权重矩阵 spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\julim.dta",name(w) standardize use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\end_data.dta" global ylist y global xlist x1 x2 x3 x4 x5 x6 x7 xtset id year **这里的处理主要是你需要自己去把数据进行分区域,然后权重也分区域排好,跑一下空间杜宾模型就可以啦! xsmle y x1 x2 x3,wmat(name1) emat(name2) dmat(name3) durbin(varlist) model(sdm) model(sac) model(sem) re(默认是随机) fe robust dlag type(ind) type(time) type(both) noeffects(默认情况下介绍)结果:
东部地区回归结果
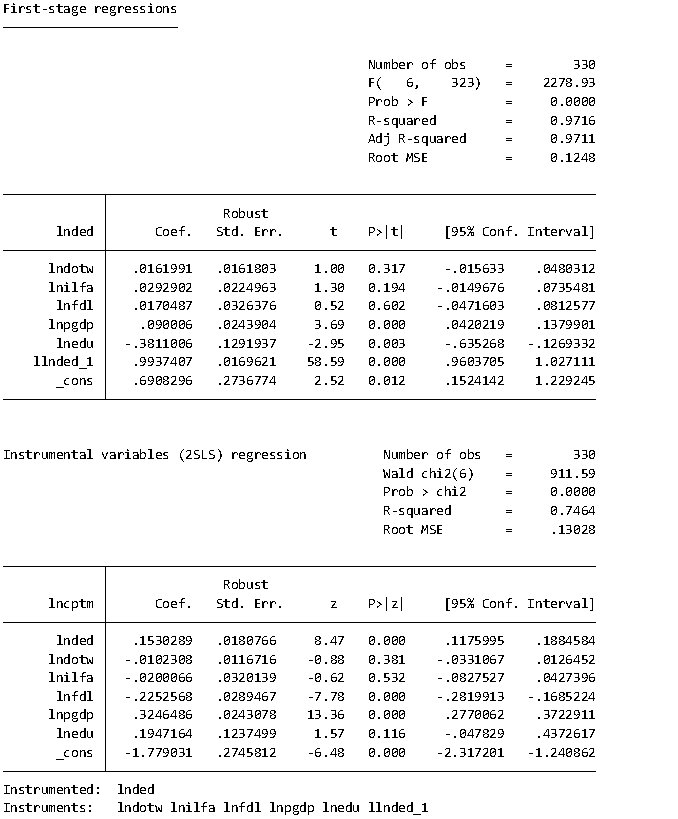
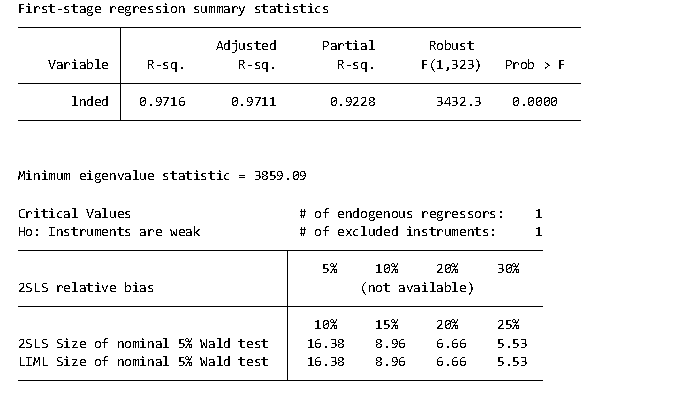
总的回归结果整理 分析: 由于不同地区的资源禀赋现象及经济发展水平的差异,本文采用国家统计局官网公布划分经济地区的标准,将31个省份划分成东部地区、中部地区、西部地区、东北地区,并基于此考察在不同经济地区下数字经济对城乡融合发展的异质性。结合表所示可知,结合标准化后数据的回归系数可以很明显看出东部地区数字经济对城乡融合的影响最大,其后依次为东北地区、中部地区、西部地区,其主要的原因可能是近几十年一直倡导西部大开发以及东北大开发的成果,而东部地区由于经济相对较为发达,数字经济发展也就很好,相应城乡融合效果就会更佳;结合相应的rho值可以看出,东部地区的空间自相关系数在1%的显著水平下显著为负,说明东部地区城乡融合发展产生了严重的虹吸现象,而西部及东北地区的空间自相关系数在1%的显著水平下显著为正,说明目前西部及东北地区城乡融合发展存在正向空间溢出效应,即本地区的城乡融合发展能很好的带动其他地区的城乡融合发展。结合各地区数字经济的空间交互项系数可知,东部地区的空间交互项不显著,猜测其可能存在空间上的门槛效应,而西部地区的空间交互项系数在10%的水平下显著为正,一定程度上说明,西部地区的城市中,周边地区的数字经济发展对本地区的城乡融合发展存在显著促进作用。 2.11 门槛回归及门限效应参考我这篇文章哈:写的挺详细的,内容写太多可能不太细,所以看看这个专题会更好一点 固定效应和随机效应模型是什么? - 统计猿的回答 - 知乎 固定效应和随机效应模型是什么? - 知乎 2.12 内生性检验2.12.1 内生性检验相关概念 内生性是指模型中的一个或多个解释变量与误差项存在相关关系。 这里说一下这个误差项,就是我们通常说的随机误差项,就是模型y=a+bx,中的a a表示观察值与总体平均值之间的差异,可正可负,不可观测,只能得到相应的拟合参数,就是残差项。 如果可以测的了的话,那要预测干嘛?我直接开上帝,预测个锤子,那这个东西搞不定,我那知道,你这个存不存在内生性问题,不知道,没法子检验,啥检验欧克,那就是自然实验,多取几次,然后看看情况,那估计的用到蒙特卡洛模拟。 行,那就暂时默认存在内生性吧,反正就算我证明没问题,你也会说我有问题,无所谓,我不证明了,我直接按照你的方式开始改,行了吧。不和您浪费宝贵的时间。反正各个变量都被你说成主观,不太客观,认识可能产生偏差,一堆的问题,一堆的论证,哈哈;我们一般也不浪费时间去搞一堆看似正确的检验,说实话,那个检验也是作者编的,也没啥用,所以你就直接说本文可能存在明显的内生性问题,需要进行内生性处理。 内生性检验证明补充: 2.12.2 内生性检验操作 内生性处理的几种方式: 1.先来看几篇常见的论文是如何处理内生性问题的 数字经济、非农就业与社会分工* [1]田鸽,张勋.数字经济、非农就业与社会分工[J].管理世界,2022,38(05):72-84.DOI:10.19744/j.cnki.11-1235/f.2022.0069. 1.删除相应的样本或者替换相应的样本 2.工具变量法:以是否为试点×是否开始实施政策,到节点城市的最近距离(取对数)×是否开始实施政策;采用的是did方法。 ------------数字经济、创业活跃度与高质量发展*——来自中国城市的经验证据 [1]赵涛,张智,梁上坤.数字经济、创业活跃度与高质量发展——来自中国城市的经验证据[J].管理世界,2020,36(10):65-76.DOI:10.19744/j.cnki.11-1235/f.2020.0154. 1.排除宏观因素的影响:采用是否使用年份*省份的交互项作为检验标准 2.各城市在1984年的邮电历史数据作为数字经济发展综合指数的工具变量 -----------县域创业活动、农民增收与共同富裕*———基于中国县级数据的实证研究 [1]林嵩,谷承应,斯晓夫,严雨姗.县域创业活动、农民增收与共同富裕——基于中国县级数据的实证研究[J].经济研究,2023,58(03):40-58. 1.替换变量:把县域创业活动换成县域农村创业活动;或者将自变量改成每万人县域创业活动,纳入人口因素 2.滞后解释变量多期:把解释变量滞后多期看看效果是否依旧稳健; ----------数字经济赋能服务业结构升级:理论机制与实证检验;数字普惠金融、农业科技创新与农村产业融合发展 [1]钟晓君,胡凯玲,刘德学.数字经济赋能服务业结构升级:理论机制与实证检验[J/OL].统计与决策,2023(12):11-16[2023-06-25].DOI:10.13546/j.cnki.tjyjc.2023.12.002. [1]焦青霞,刘岳泽.数字普惠金融、农业科技创新与农村产业融合发展[J].统计与决策,2022,38(18):77-81.DOI:10.13546/j.cnki.tjyjc.2022.18.015. [1]易行健,周利.数字普惠金融发展是否显著影响了居民消费——来自中国家庭的微观证据[J].金融研究,2018,(11). [1]钱海章,陶云清,曹松威,曹雨阳.中国数字金融发展与经济增长的理论与实证[J].数量经济技术经济研究,2020,37(06):26-46.DOI:10.13653/j.cnki.jqte.2020.06.002. 1.剔除相应的地区:直辖市的经济发展水平、人口集聚情况、政策惠及程度等与其他省份存在较大差异,这可能影响数字经济对服务业结构升级的作用结果。借鉴钱海章等(2020)[20]的做法,剔除北京、天津、上海和重庆四个直辖市的数据。 2.工具变量法:本文利用数字普惠金融的两种工具量来进行两阶段最小二乘估计,以克服基准回归中的内生性问题:一种是参考易行键和周利(2018)[6]的做法,用数字普惠金融的一阶滞后项和一阶差分的乘积构建工具变量(iv_bartik);另一种是借鉴钱海章等(2020)[17]的做法,采用人均电信业务量作为工具变量(iv_ pp)。 -------------数字经济赋能文旅融合的影响机制与门槛效应研究 [1]杨利,李梦含,张名杰,张怡琼.数字经济赋能文旅融合的影响机制与门槛效应研究[J/OL].统计与决策,2023(12):29-34[2023-06-25].DOI:10.13546/j.cnki.tjyjc.2023.12.005. [15]鲁钊阳,杜雨潼.数字经济赋能农业高质量发展的实证研究[J].中国流通经济,2022,36(11). 1.工具变量:因此借鉴相关研究[15],引入滞后一期的数字经济作为工具变量进行内生性检验,表5中列(3)和列(4)分别表示未加入控制变量和加入控制变量后工具变量的回归结果,结果均在1%显著性水平上呈正相关态势,且检验结果与基准回归结果相近,说明假设1的可靠性进一步得到证实。 例子: 知乎 - 安全中心 可以看到处理的方法大致都差不多,用工具变量法,替换变量,删除区域,这里主流还是工具变量法,其他的和稳健性检验类似,要是缺字数你就写。 2.啥是工具变量法,如何操作? 在模型估计过程中被作为工具使用,以替代模型中与误差项相关的随机解释变量的变量,称为工具变量。 作为工具变量,必须满足下述四个条件: (1)与所替的随机解释变量高度相关; (2)与随机误差项不相关; (3)与模型中其他解释变量不相关; (4)同一模型中需要引入多个工具变量时,这些工具变量之间不相关。 它的意思就是给解释变量找个孪生兄弟,但这个孪生兄弟要符合没有内生性要求,咱也不管它到底是有没有关系,咱就是找就行,按照常规的找一堆的工具变量,看那个工具变量的结果优秀,就放那些结果,但是记住看你文章的水准,越好文章,你应该越严格控制,不然就是数据怪物,天天锁在自己的局子里,无法自拔。 看看上面前人给我们找的路子: 1.过去的邮电数据:1984年的邮电历史数据作为数字经济发展综合指数的工具变量;人均电信业务量作为工具变量。 2.自身滞后:数字普惠金融的一阶滞后项和一阶差分的乘积;引入滞后一期的数字经济作为工具变量 3.想象类:发现了遗漏重要变量,书籍的分布,即获取书籍的便利度;之后想到书籍的原材料松和竹子,在看松和竹子到各个省的府第的距离作为工具变量。 4.特别方法特别针对类:以是否为试点×是否开始实施政策,到节点城市的最近距离(取对数)×是否开始实施政策;采用的是did方法。 stata操作方法: **导入面板数据,需要数据私聊 use "G:\统计建模资料汇总\instatam.dta" **指定面板 xtset id year **获取数字经济滞后一期llnded_1 gen llnded=l1.lnded by id: ipolate llnded year,gen(llnded_1) epolate **先进行两阶段最小二乘估计 ivregress 2sls 被解释变量 (解释变量 = 工具变量) 控制变量, r first ivregress 2sls lncptm ( lnded = lnded_1) lndotw lnilfa lnfdl lnpgdp lnedu, r first **之后对工具变量是否为弱工具变量做出检验 estat firststage,forcenonrobust
引入滞后一期的数字经济作为工具变量进行内生性检验,表5中列(3)和列(4)分别表示未加入控制变量和加入控制变量后工具变量的回归结果,结果均在1%显著性水平上呈正相关态势,且检验结果与基准回归结果相近,说明假设1的可靠性进一步得到证实。 结果表明,在考虑了内生性之后,数字经济对提升经济高质量发展的效应仍旧成立,结果均在 1%的水平下显著。此外,对于原假设“工具变量识别不足”的检验,Kleibergen-Paap rk 的 LM 统计量 p 值均为 0.000,显著拒绝原假设;在工具变量弱识别的检验中,Kleibergen-Paap rk 的 Wald F 统计量大于Stock-Yogo 弱识别检验 10%水平上的临界值。总体而言,以上检验说明了选取数字经济滞后一期工具变量的合理性。 2.13 其他常见知识补充 2.13.1 异方差 异方差检验 就是说残差会随时间或个体变化,不满足ols假设。 **基本设置 cd"G:\统计建模资料汇总\" use "G:\统计建模资料汇总\instatam.dta" xtset id year global ylist lncptm global xlist lnded lndotw lnilfa lnfdl lnpgdp lnedu **基本回归 reg lncptm lnded **画残差散点图----观察残差是否随时间变化 rvfplot rvpplot lnded **BP-检验,p值小于0.05,即拒绝原假设,接受备择假设,存在异方差 estat hettest, iid **怀特检验,p值小于0.05,即拒绝原假设,接受备择假设,存在异方差 imtest, white
核心解释变量的对数的残差分布图
B-P检验
怀特检验 异方差解决 **取残差 quietly reg $ylist $xlist predict e1, res **对残差进行平稳性处理,方便回归 gen e2 = e1^2 gen lne2 = log(e2) **与核心解释变量进行回归,看看这个残差和核心解释变量之间的解释程度,如果很好解释了,就模型就可能存在问题。 reg lne2 lnded , noc **开始预测这部分残差值作为权重,把它平均掉,以其残差倒数作为最小二乘法的权重,消除这部分相关较强的残差影响。 predict lne2f gen e2f = exp(lne2f) reg $ylist $xlist [aw=1/e2f]
缓解后效果-基本回归
缓解后效果-稳健回归+控制变量 缓解了之后就会使得回归结果变得更好 2.13.2 多重共线性说明:这是一个很常见问题,就是说误差变量,解释变量和控制变量之间存在强相关,且互相影响交互。 这就会导致很多的结果不显著,结果违反常理。 多重共线性检验: corr lncptm lnded lndotw lnilfa lnfdl lnpgdp lnedu
相关结果 **估计vif值 reg $ylist $xlist estat vif
经验上,VIF最大不超过10,严格来说不应高于5 很明显没必要修正多重共线性,面板数据能不搞就不搞。 多重共线性修正: 根据变量的相关性排名频率来排先后剔除顺序(相关性至少>0.5) 变量lndedlndotwlnilfalnfdllngdp第一大相关变量lndotwlnilfalnedulnedulnedu第二大相关变量lnilfalnedulngdplnedu lnilfa lndotw,lngdp **用最严格检验 xtreg lncptm lnded lndotw lnilfa lnfdl lnpgdp lnedu i.year, fe r开始剔除,先逐个删除,发现去掉lngdp最好
个体-时间固定效应稳健结果 之后进一步扩大到删除2个,对比发现lnilfa和lngdp效果更好(关注核心解释变量的p值),降到0.251 之后在进一步扩大到3个,对比发现去除lnedu,lngdp,lndotw效果更好,降到了0.191 在扩大删除4个,对比发现降至0.001 之后放宽 xtreg lncptm lnded lnfdl i.year, fe
这里基于的数据是我自己论文数据,到时候会和论文一起发出,不要急,主要了解报错原因 1.在进行莫兰检验时
矩阵不匹配 报错示范代码: cd "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\" spatwmat using "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\julim.dta",name(w) standardize spatgsa uid,weight(w) moran twotail报错原因:矩阵和样本数不匹配 正确代码: cd "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\" use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\julim.dta" spcs2xt c1- c31,matrix(w)time(11) spatwmat using wxt,name(w) standardize save "wxt.dta", replace use "F:\个人汇报文件夹\普惠金融,数字经济促进农村三产融合效率研究\空间杜宾模型数据\end_data.dta" spatgsa uid,weight(w) moran twotail 二.论文实战----------------------------------------期待一下哦-------------------------------------------------------- 1.理论储备 2.数据实操流程 3.论文书写 三.反思总结注:本文引用了部分其他作者内容,主要是用来更好帮助大家理解空间杜宾模型,如有侵权,请联系删除,谢谢您! |



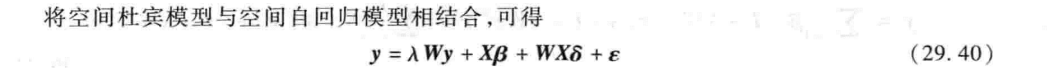














































【本文地址】