| 条件概率,全概率公式与贝叶斯公式的推导,理解和应用 | 您所在的位置:网站首页 › 五大概率公式推导方法 › 条件概率,全概率公式与贝叶斯公式的推导,理解和应用 |
条件概率,全概率公式与贝叶斯公式的推导,理解和应用
|
目录
基础知识概率的定义
条件概率完备事件组乘法公式
全概率公式定义推导应用1.求次品率2.敏感问题调查问卷
贝叶斯公式定义证明应用
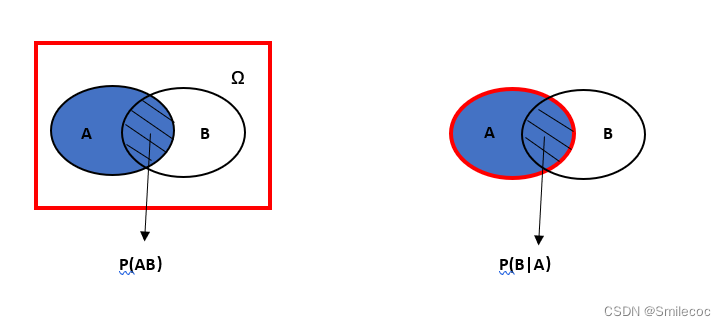
在概率论与数理统计中,条件概率是相当重要概念,同时从条件概率可以引申出有两个相当重要的公式——全概率公式与贝叶斯公式。本篇文章对条件概率,全概率公式与贝叶斯公式进行解释和推导,并列举实际应用以帮助大家了解相关公式。涉及到的内容对应概率论与数理统计课本的第一章内容,如有兴趣可参考课本内容。 基础知识在理解全概率公式与贝叶斯公式之前,我们先了解一下必须的基本统计与概率知识。 概率的定义首先我们先给出两种对于概率的定义: 描述性定义:通常将随机事件A发生的可能性大小的度址(非负值)称为事件A发生的概率,记为 P ( A ) P(A) P(A).统计性定义:在相同条件下做重复试验,事件A出现的次数 K K K和总的试验次数 n n n之比—称为事件A在这 n n n次试验中出现的频率。当试验次数 n n n充分大时,频率将“稳定”于某常数 p p p。 n n n越大,频率偏离这个常数 p p p的可能性 越小 . 这个常数 p p p就称为事件A的概率通俗的理解 :在抛一枚硬币时,如果我们抛10次硬币,出现了7次正面,3次反面,那么对于"抛硬币出现正面"这一个事件的频率为 7 10 \dfrac{7}{10} 107.当我们做很多次实验,那么对于"抛硬币出现正面"这一个事件的频率会稳定接近 1 2 \dfrac{1}{2} 21,这就是"抛硬币出现正面"这一个事件的概率 概率的统计性定义实质上是说,用频率作为事件A 的概率 P ( A ) P(A) P(A)的估计.其直观理解为某事件出现的可能性大小。 条件概率设 A , B A,B A,B为任意两个事件,若 P ( A ) > 0 P(A)>0 P(A)>0,我们称在已知事件A发生的条件下,事件B发生的概率为条件概率,记为 P ( B ∣ A ) P(B|A) P(B∣A),且 P ( B ∣ A ) = P ( A B ) P ( A ) P(B|A) = \frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)。 这个公式有两点需要: 这里的字母顺序 P ( B ∣ A ) P(B|A) P(B∣A)和 P ( A ∣ B ) P(A|B) P(A∣B)代表的含义是不一样的,如果你很容易混淆,可以记作 P ( 结果 ∣ 原因 ) P(结果|原因) P(结果∣原因)或者 P ( 事件 ∣ 条件 ) P(事件|条件) P(事件∣条件) P ( A B ) P(AB) P(AB)的含义事件A和事件B同时发生的概率,等价于 P ( A ∩ B ) P(A \cap B) P(A∩B),概率论中P(AB)都是这一个含义条件概率是理解全概率公式和贝叶斯公式的基础,可以这样来考虑:在条件概率中,最本质的变化是样本空间缩小了——由原来的整个样本空间缩小到了给定条件的样本空间(如下图所示的红色部分),从而也影响了最终事件发生的概率。如下图所示: 同时从上面的图中的逻辑,我们可以使用古典概型推导出条件概率公式: 设整个样本空间Ω中的样本数为 N N N,事件A与B同时发生的样本数为 m m m,事件A的样本数为 n n n,则有 P ( A ) = n N P(A)=\frac{n}{N} P(A)=Nn, P ( A B ) = m N P(AB)=\frac{m}{N} P(AB)=Nm,而 P ( B ∣ A ) = m n = P ( A B ) N n = P ( A B ) P ( A ) P(B|A)=\frac{m}{n}=\frac{P(AB)N}{n}=\frac{P(AB)}{P(A)} P(B∣A)=nm=nP(AB)N=P(A)P(AB) 完备事件组如果有限个(或可列个)事件满足 A 1 , A 2 , … , A n A_{1} ,A _{2},…,A_{n} A1,A2,…,An满足 A 1 + A 2 + ⋯ + A n = Ω A_{1}+A_{2}+⋯+A_{n}=Ω A1+A2+⋯+An=Ω且 A i A j = ∅ ( i ≠ j ) , i , j = 1 , 2 , … , n ) A_{i}A_{j}=\varnothing(i≠j),i,j=1,2,…,n) AiAj=∅(i=j),i,j=1,2,…,n),则称有限个(或可列个)事件构成了一个完备事件组。 通俗的理解 :就是事件之间两两互斥(
A
i
A
j
=
=
∅
A_{i}A_{j}==\varnothing
AiAj==∅),所有事件不重不漏,并集是整个样本空间(
Ω
Ω
Ω,必然事件).举个栗子:掷骰子时,用
A
n
A_{n}
An表示掷出得点数为
n
n
n,
A
1
A_{1}
A1表示掷出的点数为1,
A
6
A_{6}
A6表示掷出的点数为6,则事件
A
1
,
A
2
…
,
A
6
A_{1},A_{2}…,A_{6}
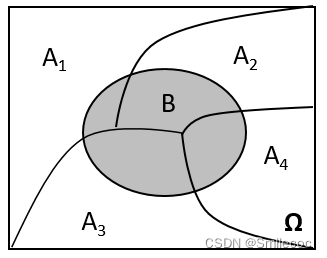
A1,A2…,A6就构成了一个完备事件组,他们之间每个事件都不会同时发生(不重),同时每次掷骰子总会有其中一个发生(不漏)。用文氏图表示如下: 由条件概率公式得: P ( A B ) = P ( A ) P ( B ∣ A ) P(AB) = P(A)P(B|A) P(AB)=P(A)P(B∣A) 上面的式子就是乘法公式。 对乘法公式进行推广,即对于任何正整数 n ≥ 2 n≥2 n≥2,当 P ( A 1 A 2 . . . A n − 1 ) > 0 P(A_{1}A_{2}...A_{n-1}) > 0 P(A1A2...An−1)>0 时,有: P ( A 1 A 2 . . . A n − 1 A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) . . . P ( A n ) ∣ A 1 A 2 . . . A n − 1 ) P(A_{1}A_{2}...A_{n-1}A_{n}) = P(A_{1})P(A_{2}|A_{1})P(A_{3}|A_{1}A_{2})...P(A_{n})|A_{1}A_{2}...A_{n-1}) P(A1A2...An−1An)=P(A1)P(A2∣A1)P(A3∣A1A2)...P(An)∣A1A2...An−1) 全概率公式 定义如果
⋃
i
=
1
n
A
i
=
Ω
,
A
i
∩
A
j
=
∅
(
i
≠
j
,
i
,
j
=
1
,
2
,
.
.
.
.
.
,
n
)
,
P
(
A
i
)
>
0
\bigcup_{i=1}^nA_i=Ω,A_i\cap A_j=\varnothing (i≠j,i,j= 1,2,.....,n), P(A_i)>0
⋃i=1nAi=Ω,Ai∩Aj=∅(i=j,i,j=1,2,.....,n),P(Ai)>0,则对任一事件B,有
P
(
B
)
=
∑
i
=
1
n
P
(
A
i
)
P
(
B
∣
A
i
)
P(B) = \displaystyle \sum_{ i = 1 }^{ n } P(A_i)P(B|A_i)
P(B)=i=1∑nP(Ai)P(B∣Ai) 全概率公式的意义在于执因索果,当直接计算 P ( B ) P(B) P(B)较为困难,而 P ( A i ) , P ( B ∣ A i ) ( i = 1 , 2 , . . . ) P(A_{i}),P(B|A_{i}) (i=1,2,...) P(Ai),P(B∣Ai)(i=1,2,...)的计算较为简单时,可以利用全概率公式计算 P ( B ) P(B) P(B)。全概率的本质不是什么条件概率,在于分解事件,如果 A 1 , A 2 , ⋯ , A n A_{1},A_{2},⋯,A_{n} A1,A2,⋯,An的并集,包含了事件B,且这三个事件两两同时发生的概率为零,则事件B等于三个事件 B A 1 , B A 2 , ⋯ , B A n BA_{1},BA_{2},⋯,BA_{n} BA1,BA2,⋯,BAn之和。之所以写成条件概率的形式,是为了计算概率 P ( B A n ) P(BA_n) P(BAn) 推导因为 Ω \Omega Ω 是一个必然事件(换句话说就是事件全集),因此有 P ( B ) = P ( B Ω ) P(B)=P(BΩ) P(B)=P(BΩ),同时事件 A 1 , A 2 , … , A n A_{1} ,A _{2},…,A_{n} A1,A2,…,An是全集的一个完备事件组,所以有 A 1 + A 2 + ⋯ + A n = Ω A_{1}+A_{2}+⋯+A_{n}=Ω A1+A2+⋯+An=Ω。进一步进行推导有: P ( B ) = P ( B Ω ) = P ( B ( A 1 + A 2 + ⋯ + A n ) ) = P ( B A 1 + B A 2 + . . . + B A n ) P(B)=P(BΩ)=P(B(A_{1}+A_{2}+⋯+A_{n}))=P(BA_1+BA_2+...+BA_n) P(B)=P(BΩ)=P(B(A1+A2+⋯+An))=P(BA1+BA2+...+BAn) 因为事件 B A 1 , B A 2 , . . . , B A n BA_{1},BA_{2},...,BA_{n} BA1,BA2,...,BAn 两两互斥,有: P ( B A 1 + B A 2 + . . . + B A n ) = P ( B A 1 ) + P ( B A 2 ) + . . . + P ( B A n ) P(BA_1+BA_2+...+BA_n)=P(BA_1)+P(BA_2)+...+P(BA_n) P(BA1+BA2+...+BAn)=P(BA1)+P(BA2)+...+P(BAn) 再由上面说到的条件概率公式/乘法公式 P ( A B ) = P ( A ) P ( B ∣ A ) P(AB) = P(A)P(B|A) P(AB)=P(A)P(B∣A)进行代入,将上式转换得到: P ( B A 1 ) + P ( B A 2 ) + . . . + P ( B A n ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + . . . + P ( A n ) P ( B ∣ A n ) P(BA_1)+P(BA_2)+...+P(BA_n)=P(A_1)P(B|A_1)+P(A_2)P(B|A_2)+...+P(A_n)P(B|A_n) P(BA1)+P(BA2)+...+P(BAn)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+...+P(An)P(B∣An) 这就是我们最终得到的全概率公式 P ( B ) = ∑ i = 1 n P ( A i ) P ( B ∣ A i ) P(B) = \displaystyle \sum_{ i = 1 }^{ n } P(A_i)P(B|A_i) P(B)=i=1∑nP(Ai)P(B∣Ai) 应用全概率公式的应用情形比较多,这里简单举两个实际中的例子 1.求次品率某产品由甲、乙、丙三家工厂进行生产,各工厂的次品率分别为5%,4%,2%,它们各自的产品分别占总量的25%,35%,40%,则消费者买到的产品是次品的概率是多少 设事件B为产品是次品, A 1 , A 2 , A 3 A_{1},A_{2},A_{3} A1,A2,A3分别表示甲、乙、丙三家工厂生产的产品 P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) + P ( A 3 ) P ( B ∣ A 3 ) = 25 % × 5 % + 4 % × 35 % + 2 % × 40 % = 0.0345 P(B)=P(A_1)P(B|A_1)+P(A_2)P(B|A_2)+P(A_3)P(B|A_3)=25\% \times5\%+4\% \times35\%+2\% \times40\%=0.0345 P(B)=P(A1)P(B∣A1)+P(A2)P(B∣A2)+P(A3)P(B∣A3)=25%×5%+4%×35%+2%×40%=0.0345 2.敏感问题调查问卷在调查敏感问题的问卷中如果直接设置问题并让所有的受调查者回答,有些受调查者可能会伪造回答。为了取得被调查者的信任一般可以设置一个随机实验进行分类,随机让一部分人回答敏感问题,另一部分人回到其他的问题. 比如调查某地婚外情的比例时, 可以给被调查者一个硬币, 让他避开调查人员自己抛硬币, 正面向上则回答问题"你是否有过婚外情?“, 反面向上则回答"你的生日是否在 7 月 1 日以前?”. 因为调查人员不知道回答的是哪个问题, 所以可以更容易的取得被调查者的信任. 假定我们想调查"有过婚外情行为"的人所占的比例 , 则可以设计下面两个问题: 问题 1:你是否有过婚外情行为? 问题 2:你的生日是在7月1日以前吗? 设问题1中回答"是"的概率为 π \pi π,也就是我们要调查的概率。问题2中回答"是"的概率为 π 2 \pi_2 π2.问题 2 也可以换为其它非敏感问题, 只要回答"是"的概率是 π 2 \pi_2 π2已知的即可,。 然后每个调查者都根据随机试验的结果回答相应的问题. 在此设回答问题1为事件 A 1 A_1 A1,概率 P ( A 1 ) = p P(A_1)=p P(A1)=p,回答问题2为事件 A 2 A_2 A2,概率 P ( A 2 ) = 1 − p P(A_2)=1-p P(A2)=1−p,问卷调查中回答“是”为B,概率为 λ \lambda λ则 P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + P ( A 2 ) P ( B ∣ A 2 ) P(B)=P(A_1)P(B|A_1)+P(A_2)P(B|A_2) P(B)=P(A1)P(B∣A1)+P(A2)P(B∣A2) 即 λ = p π + ( 1 − p ) π 2 \lambda= p\pi+(1-p)\pi_2 λ=pπ+(1−p)π2 从而问题1中回答"是"的概率 π = 1 p [ ( p − 1 ) π 2 + λ ] , π 2 > 0 \pi=\frac{1}{p}[(p-1)\pi_2+ \lambda],\ \pi_2>0 π=p1[(p−1)π2+λ], π2>0 假设总共有 m m m个人回答结果为"是", 所有被调查的人数为 n n n并用近似 m n \frac{m}{n} nm, 就可以得到 λ \lambda λ的估计值 π ^ = 1 p [ ( p − 1 ) π 2 + m n ] , π 2 > 0 \hat{\pi}=\frac{1}{p}[(p-1)\pi_2+\frac{m}{n}],\ \pi_2>0 π^=p1[(p−1)π2+nm], π2>0 这个例子中被调查者生日是在7月1日前后的概率都是50%,即 π 2 = 0.5 \pi_2=0.5 π2=0.5,如果用抛硬币的方式分类,则 p = 0.5 p=0.5 p=0.5 贝叶斯公式 定义贝叶斯的思想是执果索因,就是在知道结果的情况下去推断原因的可能性 设 A 1 , A 2 , … , A n A_{1} ,A _{2},…,A_{n} A1,A2,…,An是样本空间 Ω Ω Ω的一个完备事件组,即 A 1 + A 2 + ⋯ + A n = Ω A_{1}+A_{2}+⋯+A_{n}=Ω A1+A2+⋯+An=Ω且 A i A j = ∅ ( i ≠ j ) , i , j = 1 , 2 , … , n ) A_{i}A_{j}=\varnothing(i≠j),i,j=1,2,…,n) AiAj=∅(i=j),i,j=1,2,…,n),则: P ( A i ∣ B ) = P ( B ∣ A i ) P ( A i ) ∑ k = 1 n P ( B ∣ A k ) P ( A k ) {P(A_{i}\mid B)= \dfrac {P(B\mid A_{i})P(A_{i})}{\sum_{k=1}^{n}P(B\mid A_{k})P(A_{k})}} P(Ai∣B)=∑k=1nP(B∣Ak)P(Ak)P(B∣Ai)P(Ai) 证明由条件概率和全概率公式很容易证明有: P ( A i ∣ B ) = P ( A i B ) P ( B ) = P ( B ∣ A i ) P ( A i ) ∑ k = 1 n P ( B ∣ A k ) P ( A k ) {P(A_{i}\mid B)=\frac{P(A_{i}B)}{P(B)}= \dfrac {P(B\mid A_{i})P(A_{i})}{\sum_{k=1}^{n}P(B\mid A_{k})P(A_{k})}} P(Ai∣B)=P(B)P(AiB)=∑k=1nP(B∣Ak)P(Ak)P(B∣Ai)P(Ai) 应用贝叶斯公式在生活中应用非常广泛,机器学习,图像识别等领域中也都有贝叶斯公式的身影。接下来介绍一个利用贝叶斯公式来进行垃圾邮件过滤的实例来介绍 首先假设收到一封新邮件,在未进行统计分析前,我们假定它是正常邮件和是垃圾邮件的概率各是50%,即 P (正常) = P (垃圾) = 50 % P(正常)= P(垃圾)=50\% P(正常)=P(垃圾)=50% 然后,对这封新邮件的内容进行解析,发现其中含有“发票”这个词,那么这封邮件属于垃圾邮件的概率提高到多少?其实就是计算一个条件概率,在有“发票”词语的条件下,邮件是垃圾邮件的概率: P ( 垃圾 ∣ 发票 ) P(垃圾|发票) P(垃圾∣发票)。直接计算肯定是无法计算了,这时要用到贝叶斯定理 P ( 垃圾 ∣ 发票 ) = P ( 发票 ∣ 垃圾 ) ⋅ P ( 垃圾 ) P ( 发票 ) = P ( 发票 ∣ 垃圾 ) ⋅ P ( 垃圾 ) P ( 发票 ∣ 垃圾 ) ⋅ P ( 垃圾 ) + P ( 发票 ∣ 正常 ) ⋅ P ( 正常 ) P( 垃圾|发票)=\frac{P( 发票|垃圾)\cdot P( 垃圾 )}{P(发票)}=\frac{P\left( 发票|垃圾 \right)\cdot P\left( 垃圾 \right)}{P\left( 发票|垃圾 \right)\cdot P\left( 垃圾 \right)+P\left( 发票|正常 \right)\cdot P\left( 正常 \right)} P(垃圾∣发票)=P(发票)P(发票∣垃圾)⋅P(垃圾)=P(发票∣垃圾)⋅P(垃圾)+P(发票∣正常)⋅P(正常)P(发票∣垃圾)⋅P(垃圾) 其中, P ( 发票 ∣ 垃圾 ) P(发票|垃圾) P(发票∣垃圾) 表示所有垃圾邮件中出现“发票”的概率, P ( 发票 ∣ 正常 ) P(发票|正常) P(发票∣正常)表示所有正常邮件中出现“发票”的概率.为了得到这二个数据必须预先提供两组已经识别好的邮件,一组是正常邮件,另一组是垃圾邮件,解析所有邮件,提取每一个词。然后,计算每个词语在正常邮件和垃圾邮件中的出现频率。 我们假设5000封垃圾邮件中有25封包含“发票”这个词,那么这个概率是5%。$P(发票|正常) $表示所有正常邮件中出现“发票”的概率,我们假设5000封正常邮件中有5封包含“发票”这个词,那么这个概率是0.1%。于是: P ( 垃圾 ∣ 发票 ) = ( 5 % × 50 % ) / ( 5 % × 50 % + 0.1 % × 50 % ) = 98 % P(垃圾|发票)=(5\%×50\%) / (5\%×50\% + 0.1\%×50\%)=98\% P(垃圾∣发票)=(5%×50%)/(5%×50%+0.1%×50%)=98% 因此,这封新邮件是垃圾邮件的概率是98%。从贝叶斯思维的角度,这个“发票”推断能力很强,直接将垃圾邮件50%的概率提升到98%了。那么,我们是否就此能给出结论:这是封垃圾邮件?答案是不能的,因为这里还有个问题:正常邮件也是可能含有“发票”这个词,如果真的是商家开给我们的发票也包含发票这个词呢?误判了怎么办? 所以我们需要将更多的词加入到判断条件中,对于“发票”不好来判断,那就联合其他词语一起来判断,根据经验和日常收到的邮件,如果这封邮件中除了“发票”,还有“常年”,“代开”,“各种”,“行业”,“正规”等词语,那么就通过这些词语联合认定这封邮件是垃圾邮件。所以现在我们要计算多个词同时出现的邮件是垃圾邮件的概率。假设选取3个词(实际应用中是15个词/字以上,以减少误判的可能),假设为:“发票”,“常年”,“代开”。计算这3个词同时出现的条件下,这是一封垃圾邮件的概率 P ( 垃圾 ∣ 发票;常年;代开 ) = P ( 发票;常年;代开 ∣ 垃圾 ) ⋅ P ( 垃圾 ) P ( 发票;常年;代开 ) P\left( 垃圾|发票;常年;代开 \right)=\frac{P\left( 发票;常年;代开|垃圾 \right)\cdot P\left( 垃圾 \right)}{P\left( 发票;常年;代开 \right)} P(垃圾∣发票;常年;代开)=P(发票;常年;代开)P(发票;常年;代开∣垃圾)⋅P(垃圾) 这里假设:所有词语彼此之间是独立的(严格说这个假设不成立;实际上各词语之间不可能完全没有相关性,但可以忽略,这也就是机器学习中的朴素贝叶斯方法加上“朴素”的原因)。所以: P ( 垃圾 ∣ 发票;常年;代开 ) = P ( 发票 ∣ 垃圾 ) ⋅ P ( 常年 ∣ 垃圾 ) ⋅ P ( 代开 ∣ 垃圾 ) ⋅ P ( 垃圾 ) P ( 发票 ) ∗ P ( 常年 ) ∗ P ( 代开 ) P\left( 垃圾|发票;常年;代开 \right)=\frac{P\left( 发票|垃圾 \right)\cdot P\left( 常年|垃圾 \right)\cdot P\left( 代开|垃圾 \right)\cdot P\left(垃圾 \right)}{P(发票)*P(常年)*P(代开)} P(垃圾∣发票;常年;代开)=P(发票)∗P(常年)∗P(代开)P(发票∣垃圾)⋅P(常年∣垃圾)⋅P(代开∣垃圾)⋅P(垃圾) 就可以通过算出概率来判断是否为垃圾邮件 同时也可以将是垃圾邮件的概率与是正常邮件的概率比较,通过比值来判断是否为垃圾邮件: P ( 垃圾 ∣ 发票;常年;代开 ) P ( 正常 ∣ 发票;常年;代开 ) = P ( 发票 ∣ 垃圾 ) ⋅ P ( 常年 ∣ 垃圾 ) ⋅ P ( 代开 ∣ 垃圾 ) ⋅ P ( 垃圾 ) P ( 发票 ∣ 正常 ) ⋅ P ( 常年 ∣ 正常 ) ⋅ P ( 代开 ∣ 正常 ) ⋅ P ( 正常 ) \frac{P\left( 垃圾|发票;常年;代开 \right)}{P\left( 正常|发票;常年;代开 \right)}=\frac{P\left( 发票|垃圾 \right)\cdot P\left( 常年|垃圾 \right)\cdot P\left( 代开|垃圾 \right)\cdot P\left( 垃圾 \right)}{P\left( 发票|正常\right)\cdot P\left( 常年|正常 \right)\cdot P\left( 代开|正常 \right)\cdot P\left( 正常 \right)} P(正常∣发票;常年;代开)P(垃圾∣发票;常年;代开)=P(发票∣正常)⋅P(常年∣正常)⋅P(代开∣正常)⋅P(正常)P(发票∣垃圾)⋅P(常年∣垃圾)⋅P(代开∣垃圾)⋅P(垃圾) 上述结果式子中所有的概率都可以通过已经识别分类好的邮件得出来。假设根据历史数据得出: P(常年|垃圾)=P(常年|正常)=5%,P(代开|垃圾)=5%,P(发票|垃圾)=5% P(代开|正常)=0.1%,P(发票|正常)=0.1% 那么上式比值为2500,即多个词(或字)联合认定,这封邮件是垃圾邮件的概率是正常邮件概率的2500倍,可以确定是垃圾邮件了。 参考文章: https://www.cnblogs.com/Belter/p/5923828.html https://blog.csdn.net/c406495762/article/details/77341116 https://zhuanlan.zhihu.com/p/75790486
|
 举一个例子: 布袋里有2颗蓝色球和3颗红色球。每次随机冲布袋里拿一颗,拿完后不放回布袋了。那么第一次拿到蓝球和第二次拿到蓝球的概率分别是多少? 在计算概率之前,我们需要弄清楚,第1次拿球和第2次拿球是相关事件还是独立事情。第1次随机拿一颗,拿到蓝色的概率是五分之二。 但拿掉一颗之后情形便不同了,所以拿第二个的时候有两种情况: (1)如果第一次拿的是红的,剩下的球里面是2颗篮球,2颗红球。所以第二次拿到蓝球的可能性是四分之二 (2)如果第一次拿到是蓝的,剩下的球里面是1颗篮球,3颗红球,所以第二次拿到蓝球的可能性是四分之一 可以看到在整个过程中随着球被取出,样本空间也在变化,从2颗蓝色球和3颗红色球变为了2颗篮球,2颗红球或者1颗篮球,3颗红球,从而同一个事件“第二次拿到蓝球”在不同的条件下发生的概率也不同,既两个条件概率
P
(
第二次拿到蓝球
∣
第一次拿到蓝红球
)
P(第二次拿到蓝球|第一次拿到蓝红球)
P(第二次拿到蓝球∣第一次拿到蓝红球)和
P
(
第二次拿到蓝球
∣
第一次拿到蓝球
)
P(第二次拿到蓝球|第一次拿到蓝球)
P(第二次拿到蓝球∣第一次拿到蓝球)不同
举一个例子: 布袋里有2颗蓝色球和3颗红色球。每次随机冲布袋里拿一颗,拿完后不放回布袋了。那么第一次拿到蓝球和第二次拿到蓝球的概率分别是多少? 在计算概率之前,我们需要弄清楚,第1次拿球和第2次拿球是相关事件还是独立事情。第1次随机拿一颗,拿到蓝色的概率是五分之二。 但拿掉一颗之后情形便不同了,所以拿第二个的时候有两种情况: (1)如果第一次拿的是红的,剩下的球里面是2颗篮球,2颗红球。所以第二次拿到蓝球的可能性是四分之二 (2)如果第一次拿到是蓝的,剩下的球里面是1颗篮球,3颗红球,所以第二次拿到蓝球的可能性是四分之一 可以看到在整个过程中随着球被取出,样本空间也在变化,从2颗蓝色球和3颗红色球变为了2颗篮球,2颗红球或者1颗篮球,3颗红球,从而同一个事件“第二次拿到蓝球”在不同的条件下发生的概率也不同,既两个条件概率
P
(
第二次拿到蓝球
∣
第一次拿到蓝红球
)
P(第二次拿到蓝球|第一次拿到蓝红球)
P(第二次拿到蓝球∣第一次拿到蓝红球)和
P
(
第二次拿到蓝球
∣
第一次拿到蓝球
)
P(第二次拿到蓝球|第一次拿到蓝球)
P(第二次拿到蓝球∣第一次拿到蓝球)不同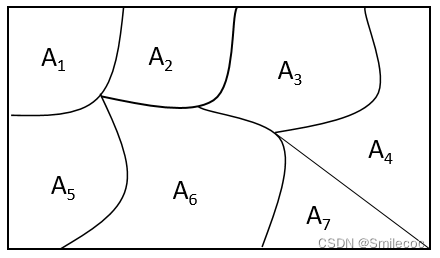

【本文地址】